

{kind=link}
This article was published as a part of the Data Science Blogathon
Introduction:

Natural language processing has been an area of research and used widely in different applications. We often love texting each other and find that whenever we try to type a text a suggestion poops up trying to predict the next word we want to write. This process of prediction is one of the applications NLP deals with. We have made huge progress here and we can use Recurrent neural networks for such a process. There have been difficulties in basic RNN and you can find it here.
This article deals with how we can use a neural model better than a basic RNN and use it to predict the next word. We deal with a model called Long Short term Memory (LSTM). We can use the TensorFlow library in python for building and training the deep learning model.
Why use LSTM?
Vanishing gradient descend is a problem faced by neural networks when we go for backpropagation as discussed here. It has a huge effect and the weight update process is widely affected and the model became useless. So, we used LSTM which has a hidden state and a memory cell with three gates that are forgotten, read, and input gate.
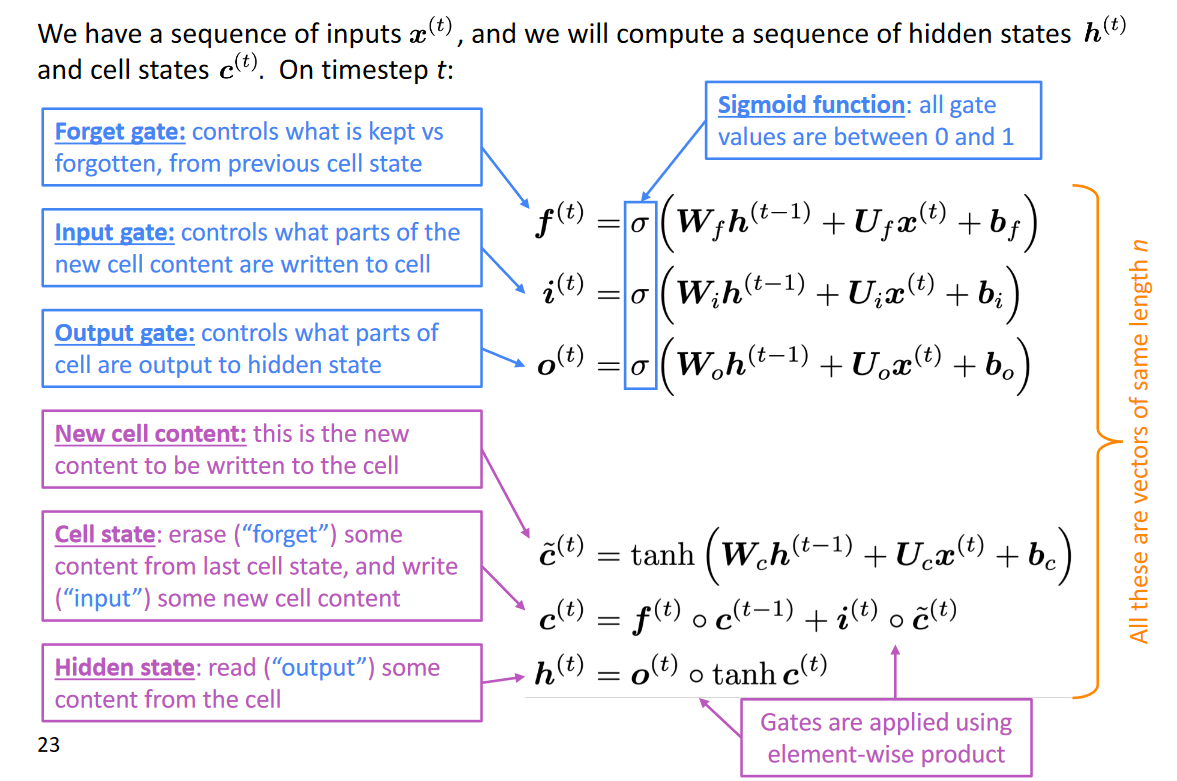
The following figure helps us understand how these gates work. The forget gate is mainly used to get good control of what information needs to be removed which isn’t necessary. Input gate makes sure that newer information is added to the cell and output makes sure what parts of the cell are output to the next hidden state. The sigmoid function used in each gate equation makes sure we can bring down the value to either a 0 or 1.
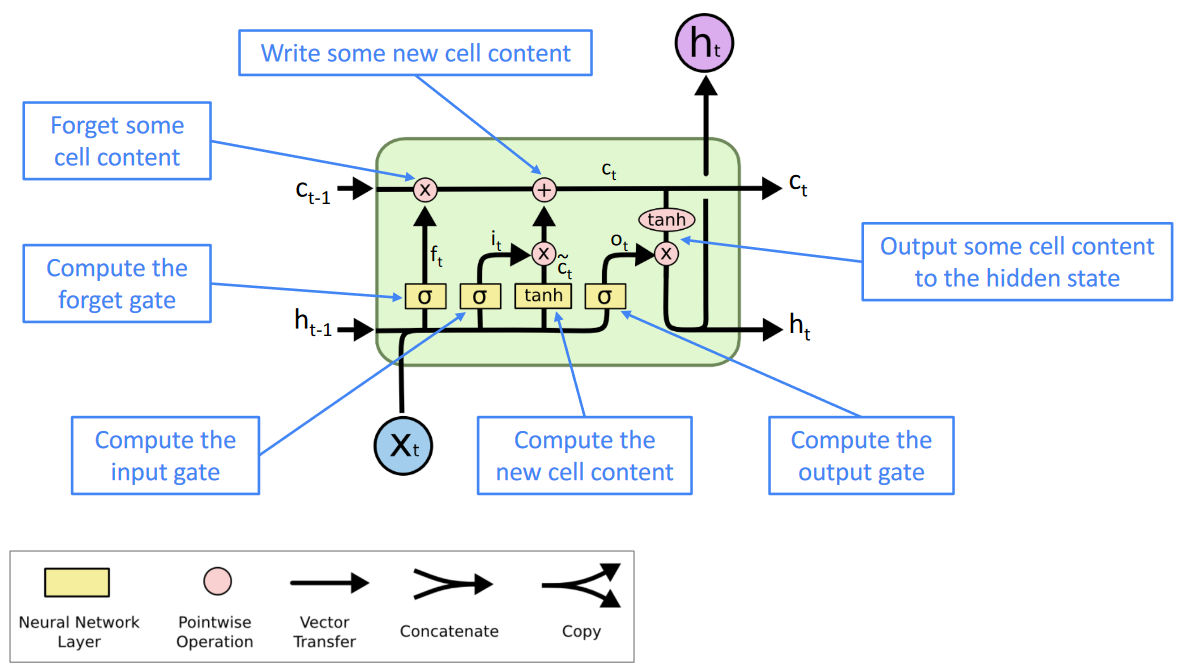
The exact architecture of an LSTM is shown in this figure. Here, X is the word subscript t indicates that time instant. As we can see, c and h are input coming from an earlier time or the last step. We have the forget gate that controls the weights so that it can exactly know what information needs to be removed before going to the next gate. We use sigmoid here. The input I am added and some new information is written in the cell at that time instant. Finally, the output gate outputs the information that is given to the next LSTM cell.
Prediction of next word:
Till now we saw how an LSTM works and its architecture. Now comes the application part. Predicting the next word is a neural application that uses Recurrent neural networks. Since basic recurrent neural networks have a lot of flows we go for LSTM. Here we can make sure of having longer memory of what words are important with help of those three gates we saw earlier.
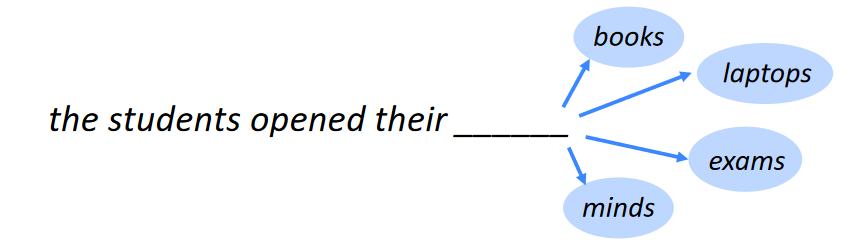
The following diagram tells us exactly what we are trying to deal with. What could be the next word? We will build a neural model to predict this. The dataset used is available here. I have followed this code from this tutorial.
1. Import the required libraries:
We use TensorFlow with Keras for our model building. We can import the LSTM model from Keras and use it. For different NLP tasks, we can use the NLTK library.
import numpy as np import heapq import matplotlib.pyplot as plt from nltk.tokenize import RegexpTokenizer from keras.models import Sequential, load_model from keras.layers.core import Dense, Activation from keras.layers import LSTM import pickle from keras.optimizers import RMSprop
2. Read the dataset:
We can check the length of the corpus by using the len function on text after reading and converting everything to lower case to avoid duplication of words.
path = 'data.txt'
text = open(path).read().lower()
print('length of the corpus is: :', len(text))
length of the corpus is: 581887
3. Using tokenizers:
The tokenizers are required so that we can split into each word and store them.
tokenizer = RegexpTokenizer(r'w+') words = tokenizer.tokenize(text)
4. Getting unique words:
We get all the unique words and we require a dictionary with each word in the data within the list of unique words as the key and its significant portions as value.
unique_words = np.unique(words) unique_word_index = dict((c, i) for i, c in enumerate(unique_words))
5. Feature Engineering:
Feature engineering will make the words into numerical representation so that it is easy to process them.
LENGTH_WORD = 5 next_words = [] prev_words = [] for j in range(len(words) - LENGTH_WORD): prev_words.append(words[j:j + LENGTH_WORD]) next_words.append(words[j + LENGTH_WORD]) print(prev_words[0]) print(next_words[0])
6. Storing features and labels:
X will be used to get the features and Y to get the labels associated with them.
X = np.zeros((len(prev_words), LENGTH_WORD], len(unique_words)), dtype=bool) Y = np.zeros((len(next_words), len(unique_words)), dtype=bool) for i, each_words in enumerate(prev_words): for j, each_word in enumerate(each_words): X[i, j, unique_word_index[each_word]] = 1 Y[i, unique_word_index[next_words[i]]] = 1
7. Building our model:
We can see that we have built an LSTM model and used a softmax activation at the end to get few specific words predicted by the model.
model = Sequential()
model.add(LSTM(128, input_shape=(WORD_LENGTH, len(unique_words))))
model.add(Dense(len(unique_words)))
model.add(Activation('softmax'))
8. Model training:
The model training uses RMSprop as the optimizer with a learning rate of 0.02 and uses categorical cross-entropy for loss function. With a batch size of 128 and a split of 0.5, we train our model.
optimizer = RMSprop(lr=0.01) model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy']) history = model.fit(X, Y, validation_split=0.05, batch_size=128, epochs=2, shuffle=True).history
8. Saving model:
The model is saved using the save function and loaded.
model.save('next_word_model.h5')
pickle.dump(history, open("history.p", "wb"))
model = load_model('next_word_model.h5')
history = pickle.load(open("history.p", "rb"))
9. Evaluating the model:
We can see the results of the models on evaluation.
plt.plot(history['acc'])
plt.plot(history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')

plt.plot(history['loss'])
plt.plot(history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')

10. Testing next word:
These functions will help us to predict the next few words when we provide a sentence.
def prepare_input(text): x = np.zeros((1, SEQUENCE_LENGTH, len(chars))) for t, char in enumerate(text): x[0, t, char_indices[char]] = 1. return x
def sample(preds, top_n=3):
preds = np.asarray(preds).astype('float64')
preds = np.log(preds)
exp_preds = np.exp(preds)
preds = exp_preds / np.sum(exp_preds)
return heapq.nlargest(top_n, range(len(preds)), preds.take)
def predict_completions(text, n=3):
x = prepare_input(text)
preds = model.predict(x, verbose=0)[0]
next_indices = sample(preds, n)
return [indices_char[idx] + predict_completion(text[1:] + indices_char[idx]) for idx in next_indices]
quotes = [
"It is not a lack of love, but a lack of friendship that makes unhappy marriages.",
"That which does not kill us makes us stronger.",
"I'm not upset that you lied to me, I'm upset that from now on I can't believe you.",
"And those who were seen dancing were thought to be insane by those who could not hear the music.",
"It is hard enough to remember my opinions, without also remembering my reasons for them!"
]
11. Predict the next word:
for q in quotes: seq = q[:40].lower() print(seq) print(predict_completions(seq, 5)) print()
12. Result:
The result will show us the words that can come next to the sentence we provided.
it is not a lack of love, but a lack of ['the ', 'an ', 'such ', 'man ', 'present, '] that which does not kill us makes us str ['ength ', 'uggle ', 'ong ', 'ange ', 'ive '] i'm not upset that you lied to me, i'm u ['nder ', 'pon ', 'ses ', 't ', 'uder '] and those who were seen dancing were tho ['se ', 're ', 'ugh ', ' servated ', 't ']it is hard enough to remember my opinion [' of ', 's ', ', ', 'nof ', 'ed ']
Reference:
https://medium.com/@antonio.lopardo/the-basics-of-language-modeling-1c8832f21079
Conclusion:
Image:https://sm.mashable.com/t/mashable_in/photo/default/shutterstock-1208129407_trm5.960.jpg
About Me: I am a Research Student interested in the field of Deep Learning and Natural Language Processing and currently pursuing post-graduation in Artificial Intelligence.
Feel free to connect with me on:
1. Linkedin: https://www.linkedin.com/in/siddharth-m-426a9614a/
2. Github: https://github.com/Siddharth1698