

{kind=link}
The following is an article by Alaeddine Abdessalem and Alex C-G of Jina AI.
Large Language Models (LLMs) have recently gained a lot of traction, with many popular models showing up like GPT, OPT, BLOOM and more. These models excel at learning natural language, making them perfect for building chatbots, coding assistants, decision-making assistants, or translation systems. However, they lack knowledge when it comes to other modalities — for instance, they cannot process images, audio, or video. That’s where BLIP comes in, to enhance LLM’s natural language capabilities with visual understanding.
Essentially, you can feed the BLIP model pairs of image and text to perform a variety of tasks, like Visual Question Answering (VQA), Image Captioning or Image-Text Retrieval:
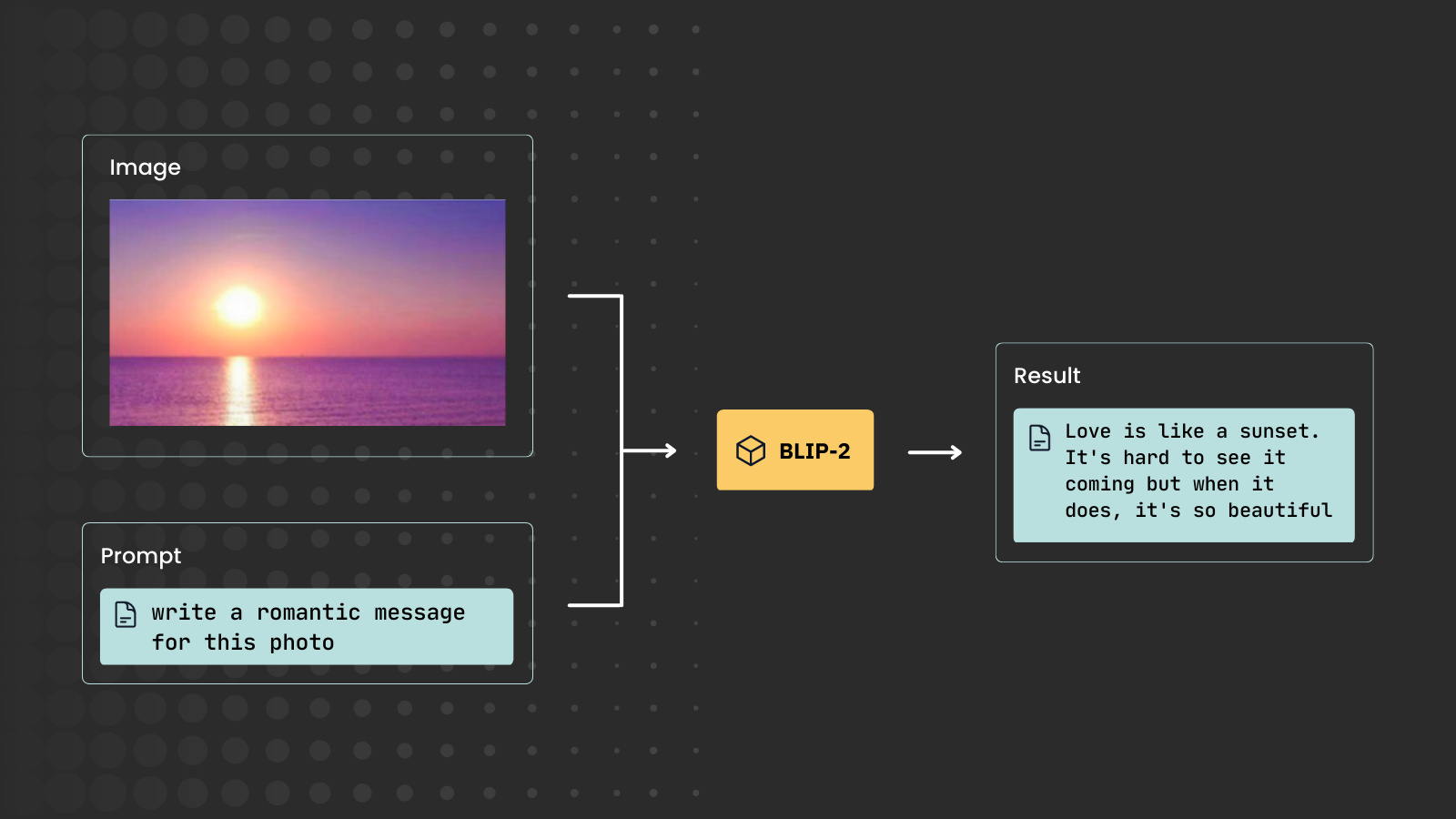
However, building a product out of BLIP may not be trivial: You need the right model-serving framework and data serialization library. At Jina AI, we’ve always believed in Multimodal AI, and that’s why we’ve optimized Jina and DocArray for this purpose. Serving BLIP-2 is a typical use case for these two projects.

Multimodal AI is artificial intelligence that works with multiple modalities at once (e.g. image + text, video + audio, etc), rather than just one single modality.
Let’s see how it works!
BLIP-2
BLIP-2 is a vision-language model proposed in the paper BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models.
It leverages frozen pre-trained image encoders and LLMs by training a lightweight, 12-layer Transformer encoder in between them, to achieve state-of-the-art performance on various vision-language tasks.
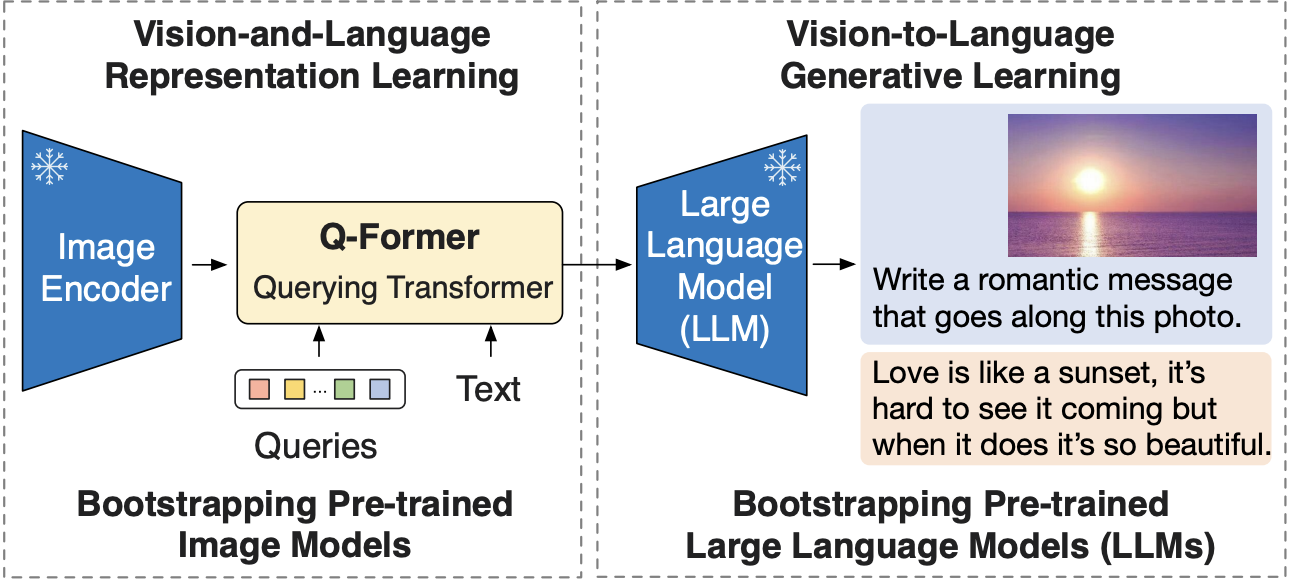
Source: https://arxiv.org/pdf/2301.12597.pdf
Jina and DocArray
Before diving into the code, let’s briefly introduce Jina and DocArray and explain what’s recently been happening with both projects.
Jina is an MLOps framework to build and serve multimodal AI services, then scale and deploy them on the cloud. But recently we’ve been reshaping Jina to serve models more effectively. And in the 3.14 release, we allow users to serve Executors as standalone services using the gRPC protocol. In this post we’ll use those newly released features to serve a BLIP-2 model.
For data representation and serialization, Jina uses DocArray, a library for unstructured, multimodal data. It’s optimized for data in transit, in the sense that data can be serialized in several formats including protobuf. In other words, model input and output can be received/sent over the wire using DocArray formats.
We’re also reshaping DocArray to better fit multimodal AI use cases. In fact, it’s going through heavy refactoring with the goal of offering flexible and powerful data formats with DocArray v2.
Therefore, we’ll use both the current DocArray and the alpha version of DocArray v2 to represent model queries and output (and in doing so you’ll quickly understand why we refactored DocArray!).
Serving BLIP-2 with DocArray and Jina
Since BLIP-2 uses LLMs, it comes with different open-source language models (i.e, flan-t5 and opt). In this blog, we’ll use flan-t5-xl. Let’s start by installing the dependencies:
pip install jina torch git+https://github.com/huggingface/transformers pillow
Then, we can initialize a Jina Executor that loads the model:
from jina import Executor, Deployment, DocumentArray, requests
from transformers import Blip2Processor, Blip2ForConditionalGeneration
import torch
class Blip2Executor(Executor):
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.processor = Blip2Processor.from_pretrained("Salesforce/blip2-flan-t5-xl")
self.model = Blip2ForConditionalGeneration.from_pretrained(
"Salesforce/blip2-flan-t5-xl", torch_dtype=torch.float16
)
self.model.to('cuda')
Performing a Visual Question Answering task with BLIP-2 is pretty straightforward: Just feed the image and text question into the input and generate the text output.
Let’s create an Executor Endpoint method to enable the VQA task:
@requests
def vqa(self, docs: DocumentArray, **kwargs):
for doc in docs:
doc.load_uri_to_image_tensor()
inputs = self.processor(images=doc.tensor, text=doc.tags['prompt'], return_tensors="pt").to('cuda', torch.float16)
generated_ids = self.model.generate(**inputs)
generated_text = self.processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
doc.tags['response'] = generated_text
A DocArray Document can store an image in the tensor field and we can put the prompt and text output in the tags field.
Finally, we can serve our Executor with the newly released Deployment class:
with Deployment(uses=Blip2Executor, timeout_ready=-1, port=12345) as dep:
dep.block()
Loading checkpoint shards: 100%|██████████████████████████████████| 2/2 [00:05<00:00, 2.92s/it]
─────────────────────────────── 🎉 Deployment is ready to serve! ───────────────────────────────
╭────────────────────── 🔗 Endpoint ──────────────────────╮
│ ⛓ Protocol GRPC │
│ 🏠 Local 0.0.0.0:12345 │
│ 🔒 Private 192.168.178.31:12345 │
│ 🌍 Public 2003:f1f:4a00:85b7:3950:81fa:952f:12345 │
╰─────────────────────────────────────────────────────────╯
Now our Executor should be ready to serve. Simply use Jina Client to send requests to the Executor over gRPC:
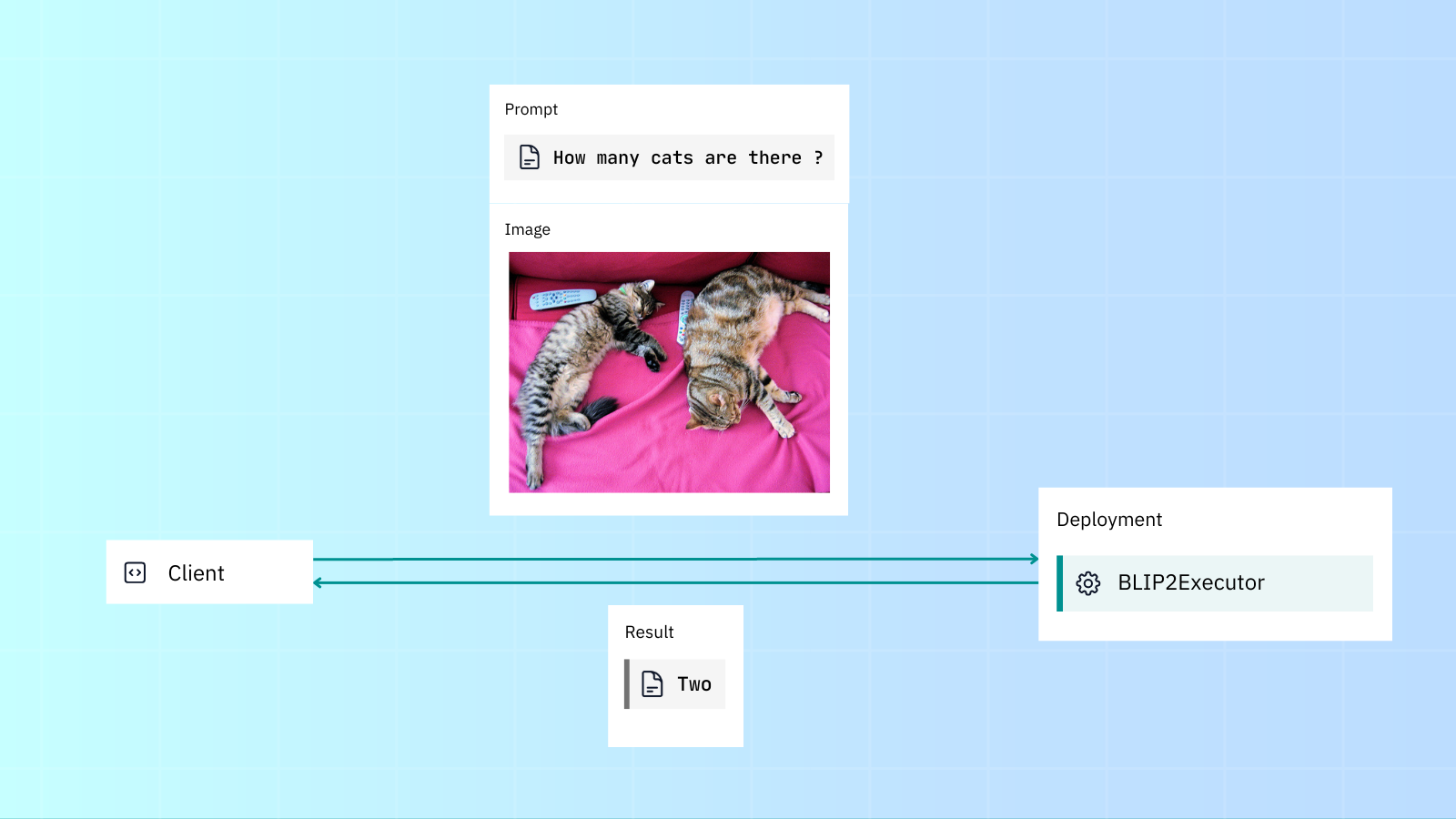
from jina import Client, Document
client = Client(port=12345)
docs = client.post(
on='/',
inputs=[Document(
uri='<http://images.cocodataset.org/val2017/000000039769.jpg>',
tags={'prompt': 'Question: How many cats are there? Answer:'}
)]
)
print(docs[0].tags['response'])
two
As we can see, BLIP-2 correctly replies to the question. But the wrapper for that answer is a little…kludgy. While DocArray offers flexibility with dynamic fields like tags and chunks, this comes with some downsides: no explicit schema, weird syntax, and same schema used for both input and output.
That’s why we’re refactoring things in DocArray v2!
Better syntax with DocArray v2
The main idea behind DocArray v2 is that users can define input and output schemas using type hints. This means that you define the needed fields in those schemas, instead of trying to fit your data into a fixed-schema Document.
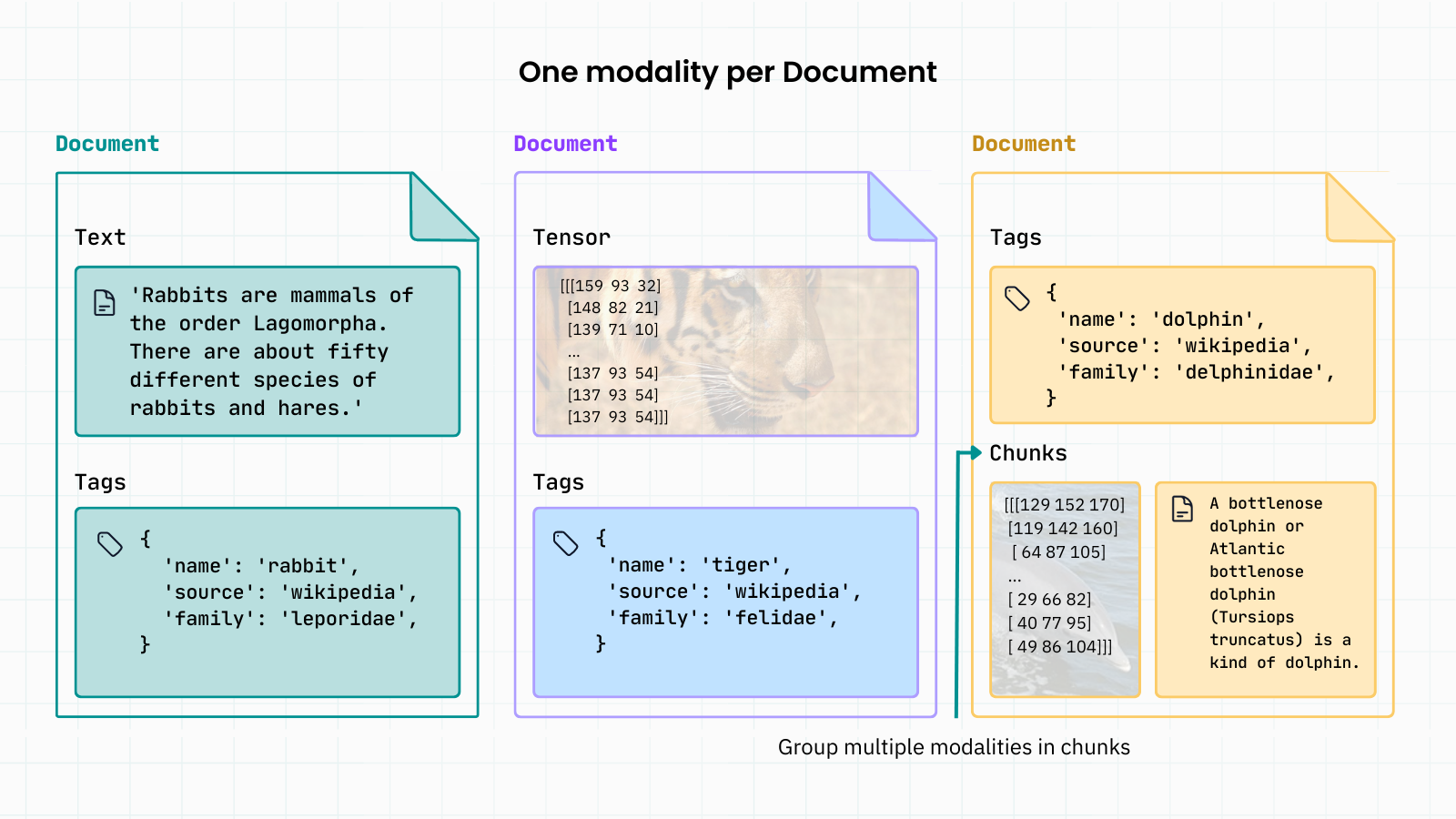
This is how your data would be represented with DocArray v1. Representing multimodal data meant adding more chunks (sub-Documents) to your Document. Yuck:
Now, instead of dumping everything into the tags and chunks fields, in DocArray v2, schemas are more flexible and representative. You can add as many fields as you want and ensure strict typing for data validation:

This offers the best of both worlds. It gives users the flexibility to define their own schema, while offering explicit typing for better data validation and casting.
Jina offers early support for DocArray v2, and lets you use the schemas as type annotations in the Executor Endpoint to define the input/output format of the services.
Let’s see how it works. First install DocArray from the v2 development branch:
pip install "git+https://github.com/docarray/docarray@feat-rewrite-v2#egg=docarray[common,torch,image]"
Then we’ll rewrite the Executor by specifying the input and output schemas:
- The input schema includes an image and text prompt field.
- The output schema includes only a text field (the generated response).
from jina import Executor, requests
from transformers import Blip2Processor, Blip2ForConditionalGeneration
import torch
from docarray import BaseDocument, DocumentArray
from docarray.typing import ImageUrl
class ImagePrompt(BaseDocument):
img: ImageUrl
prompt: str
class Response(BaseDocument):
answer: str
class Blip2Executor(Executor):
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.processor = Blip2Processor.from_pretrained("Salesforce/blip2-flan-t5-xl")
self.model = Blip2ForConditionalGeneration.from_pretrained(
"Salesforce/blip2-flan-t5-xl", torch_dtype=torch.float16
)
self.model.to('cuda')
@requests
def vqa(self, docs: DocumentArray[ImagePrompt], **kwargs) -> DocumentArray[Response]:
response_docs = DocumentArray[Response]()
for doc in docs:
inputs = self.processor(images=doc.img.load(), text=doc.prompt, return_tensors="pt").to('cuda', torch.float16)
generated_ids = self.model.generate(**inputs)
generated_text = self.processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
response_docs.append(Response(answer=generated_text))
return response_docs
Now, let’s serve the Executor and submit requests to it:
from jina import Deployment
with Deployment(uses=Blip2Executor) as dep:
docs = dep.post(on='/bar', inputs=ImagePrompt(
img='<http://images.cocodataset.org/val2017/000000039769.jpg>',
prompt='Question: how many cats are there ? Answer:'
), return_type=DocumentArray[Response])
print(docs[0].answer)
two
Conclusion
Jina lets you build multimodal AI services based on gRPC. It removes the complexity of building a gRPC service by allowing you to define endpoints and request/response schemas in a pythonic way.
DocArray lets you represent and serialize multimodal data efficiently. For this purpose, it offers predefined multimodal data types and built-in protobuf serialization.
Thus, Jina and DocArray offer the top-of-the-line tech stack for building multimodal AI services, thanks to pillars like efficient networking and serialization, pythonic API and expressive data types.
Here are the top takeaways:
- Use Jina
Deploymentto serve an Executor that wraps your favorite model. - Use DocArray to represent your unstructured data. You can experiment with DocArray v2 alpha version to enjoy better syntax.
- Bonus: if your model supports batching, try out Jina’s dynamic batching to increase throughput with efficient hardware utilization, or simply explore Jina scale out features.
- Extra bonus: Jina AI Cloud will soon release a BLIP API as part of its inference service for various vision-language tasks. Keep an eye on our Slack and social media to stay up-to-date!
Article originally posted here. Reposted with permission.