



{kind=link}
Introduction
The volume of data collected worldwide has drastically increased over the past decade. Nowadays, data is continuously generated if we open an app, perform a Google search, or simply move from place to place with our mobile devices. This data generation has boosted business decision-making and operational efficiencies whilst advancing the field of predictive analytics. As a result, businesses and organizations must manage, store, visualize, and analyze massive volumes of important data.
Several specialized big data software and architecture solutions have been developed to handle this level of complexity and volume. This article will use big data tools like PySpark MLlib and Koalas to solve a classification problem.
This article was published as a part of the Data Science Blogathon.
Table of contents
What is PySpark and Koalas?
Big data platforms are especially created to handle enormous volumes of data that enter the system at high velocities and in a broad variety. These big data platforms often include a variety of servers, databases, and business intelligence tools that enable data scientists to manipulate data to discover trends and patterns.
PySpark is one such tool to handle large-scale data processing. MLlib is Spark’s machine learning (ML) library and is a wrapper over PySpark. To store and process data, this library employs the data parallelism technique.
Data scientists use pandas to explore data. Although it is one of the best tools for handling and analyzing data, it cannot handle large amounts of data. When their data volume increases, they need to choose and learn a new system from scratch, such as Apache Spark, to adapt and transform their current workload. Koalas bridges the gap by providing pandas-like APIs that work with Apache Spark. Because Koalas supports many operations that are difficult to execute with PySpark, such as visualizing data directly from a PySpark DataFrame, it is valuable not only for pandas users but also for PySpark users.
How to Use Koalas with Pyspark?
Carrying out exploratory data analysis, feature engineering, and model construction are the norm while developing machine learning models. I’ll try to touch on the aforementioned topic with Koalas. Pandas API is reportedly used by the majority of Data scientists for feature engineering and EDA tasks. I’ll show how to utilize Koalas to complete these tasks and PySpark to create the model.
I’ll use the Bank marketing campaigns dataset. It is a dataset that describes the outcomes of Portugal’s bank marketing activities. Campaigns were generally conducted through direct phone conversations, offering bank clients the opportunity to put a term deposit. If the client decides to put in a deposit after all marking efforts, the target variable is marked ‘yes,’ otherwise ‘no.’ We will create a model to predict the client’s potential to sign up for a bank term deposit.
Step 1: Import the Necessary Libraries
To install PySpark, you can read the official documentation.
To install Koalas use:
! pip install koalas
import databricks.koalas as ks
import os
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import confusion_matrix, classification_report
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
plt.style.use(‘ggplot’)
plt.rcParams[‘figure.figsize’] = (15, 10)PySpark is not present on the system path by default. You can add it to the system path at runtime to make it importable. Use findspark to do this task.
import findspark
findspark.init()
findspark.find()Now you can import PySpark.
from pyspark.ml.evaluation import BinaryClassificationEvaluator
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.classification import RandomForestClassifier , LogisticRegressionStep 2: Loading the Dataset using Koalas
data = ks.read_csv('bank-additional-full.csv',sep=";")
data.head(10)
Step 3: Data Preprocessing
We can easily use Koalas with Seaborn to generate graphs by converting the Koalas dataframe to a NumPy array.
data['y'] = data['y'].apply(lambda x: 0 if x=='no' else 1)
sns.countplot(data['y'].to_numpy())
plt.title('Deposit Distributions n (0: No || 1: Yes)', fontsize=14)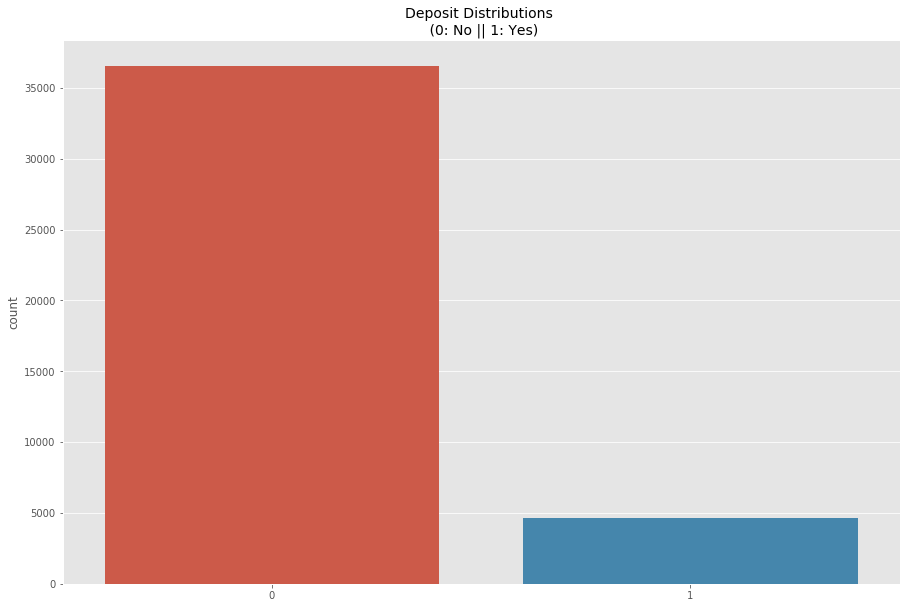
Similar to examining the data with Pandas, we can do the same with Koalas.
Moving further, we will create a list of categorical variables by selecting the columns with an object data type. Once we have a set of categorical variables, we will use get_dummies() to turn them into indicator variables.
#get the list of categorical columns
cat_col=[col for col in data.columns.values if data[col].dtype=='object']# sepearting the numerical and categorical feature
df_cat=data[cat_col]
df_num= data.drop(cat_col,axis=1)
df_cat_dum= ks.get_dummies(df_cat,drop_first=True)
df_features=ks.concat([df_num,df_cat_dum], axis=1)
sns.countplot(data['y'].to_numpy())
plt.title('Deposit Distributions n (0: No || 1: Yes)', fontsize=14)We will now select features with a correlation greater than a certain threshold.
correlations = df_features.corr()
all_features = correlations['y'].index.to_list()
corr_y = correlations['y'].values
selected_features = []
for i in range(len(corr_y)):
if abs(corr_y[i]) > 0.01:
selected_features.append(all_features[i])
print(all_features[i])
df_features = df_features[selected_features]Now we will scale the features using a MinMax scaler.
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
data_standardised = scaler.fit_transform(df_features.values)
df_std = ks.DataFrame(data_standardised)
df_std.columns = selected_featuresCreating Feature Vectors
Now that we have created the features with the help of Koalas, we will convert the Koalas DataFrame into a Spark Data frame. Then, using PySpark’s VectorAssembler, we’ll build a feature vector to train the model.
df =df_std.to_spark()
features = df_features[selected_features].columns.to_list()
features.remove('y')
vectorAssembler = VectorAssembler(inputCols = features, outputCol = "vectors")
vpp_sdf = vectorAssembler.transform(df)
#to see data in jupyter notebook
from IPython.display import HTML
v = vpp_sdf.select('vectors').toPandas().head()
HTML(v.to_html())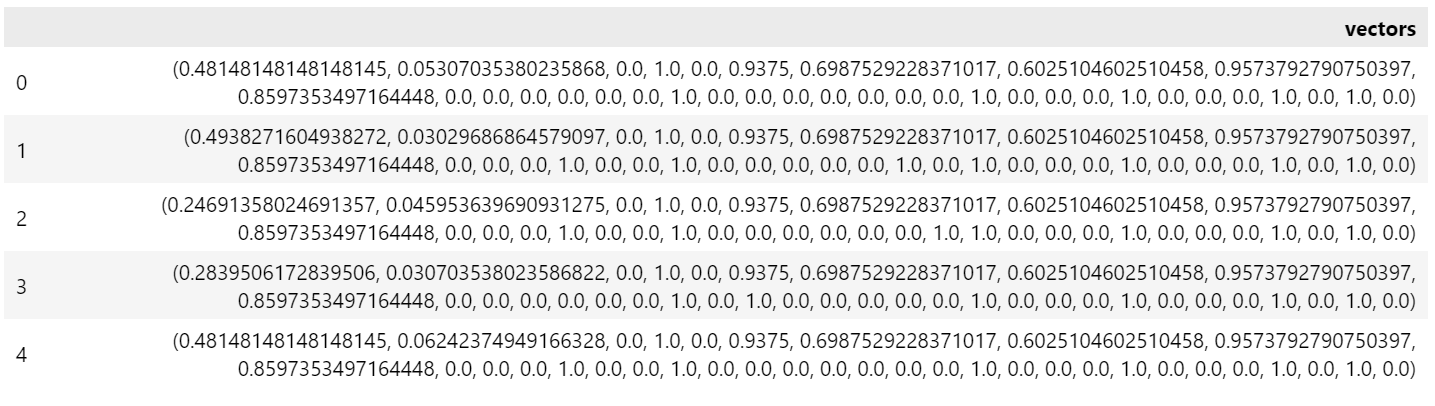
Train Test Split
splits = vpp_sdf.randomSplit([0.7,0.3])
train_df = splits[0]
test_df = splits[1]Training PySpark Model
We will use MLlib’s Random forest classifier. It takes two arguments: featuresCol (the feature vector) and labelCol (the label to predict).
rfc = RandomForestClassifier(labelCol="y", featuresCol="vectors")
rfc_model = rfc.fit(train_df)
predictions = rfc_model.transform(test_df)Evaluate the Model
We have two options for evaluating the model: utilize PySpark’s Binary classification evaluator, convert the predictions to a Koalas dataframe and use sklearn to evaluate the model. One advantage of using the latter is that we can easily visualize the results.
Using PySpark, we can find the area under ROC with the help of this code:
evaluator = BinaryClassificationEvaluator(labelCol="y", rawPredictionCol="prediction", metricName='areaUnderROC')
predictionAndTarget = predictions.select("y", "prediction")
evaluator.evaluate(predictionAndTarget)0.5777082763196241
Convert a Spark DataFrame to a Koalas DataFrame and simply compute the confusion matrix.
#convert spark dataframe to koalas dataframe
kdf_predictions = ks.DataFrame(predictions)cm = confusion_matrix(kdf_predictions['y'].to_numpy(),kdf_predictions['prediction'].to_numpy())sns.heatmap(cm, annot=True, cmap='viridis',fmt='g')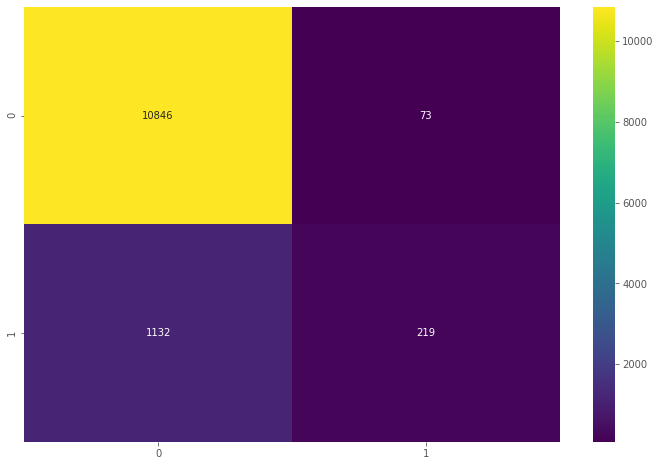
classification_report(kdf_predictions['y'].values,kdf_predictions['prediction'].values)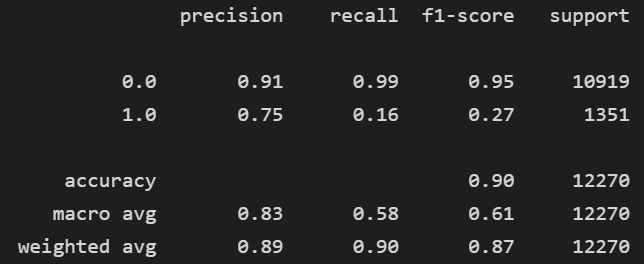
Conclusion
Koalas can help scale our Pandas code on Spark without learning a new framework from scratch by swapping out one package with another. In this article, we build a binary classifier using Pyspark. The following are some major takeaways from the article:
- We learned how to use Koalas to process the data.
- We created feature vectors using PySpark’s VectorAssembler.
- Finally, we used a Random Forest classifier to train our model and evaluated the model using different methods.
Frequently Asked Questions
A. Koalas is an open-source Python library in Databricks that provides a pandas-like interface for working with big data using Apache Spark, making it more accessible to Python users.
A. Databricks Koalas bridges the gap between pandas and big data tools like PySpark. While pandas is for small to medium-sized data, Koalas allows you to work with larger datasets using a similar API.
A. Koalas and PySpark serve different purposes. Koalas is ideal for users familiar with pandas who want to work with big data, while PySpark is a comprehensive big data framework with more extensive capabilities.
A. PySpark is an open-source Apache Spark library for distributed data processing. Databricks is a cloud-based platform for big data analytics. Koalas is a library within Databricks, bridging pandas and PySpark for easier big data analysis in Python.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.