

{kind=link}
Introduction
If you don’t challenge yourself, you will never realize what you can become
Knocktober – the machine learning competition held last weekend sure made history. It was one of the most challenging and intimidating competitions on Analytics Vidhya. We saw top data scientists from across the world using best of their knowledge to secure top position on the leaderboard.
We launched the competition on 21 Oct’16 midnight with over 2275 participants. At the time of launching this competition, we promised that you will be provoked to question your machine learning skills. And we bet you did. The competition ended on 23 oct’16 leaving everyone clueless about private leaderboard ranks.
The winners of the competition have generously shared their detailed approach and codes they used in the competition. XGBoost, Python & GBM were widely used in the competition. But, it was the combination of best features and prudent validation technique which won the competition.
For all those who didn’t participate in this competition, you’ve missed out on one of the best opportunities. Nevertheless, there’s always a next time. Stay tuned for upcoming hackathons.

About the Competition
Medcamp, is a not for profit organisation which organizes health camps in cities with low work-life balance. It was started in 2006 and its core mission is to help people maintain a balanced work-life. For four years, they have conducted 65 health camps in various cities. But they are facing a big problem in their effective business operations. And they want data scientists to provide them a solution.
![]()
The Problem Set
Medcamp is incurring losses. Every year they see a huge drop in the number of people registering for the camp and the ones actually taking test at the camp.
The irregularity in the number of people showing at the camp creates a big problem for them. If the number of people taking the test is less than the total number of registration, then the company incurs loss of unnecessary inventories. And if, the number of people visiting the camp is more than the number of registration, then it can lead to shortage of inventory and thus, a bad experience for the people.
To tackle this problem, Medcamp has provided the total number of registrations from past 4 years and want data scientists to provide them insights from the data. The evaluation metric used was AUC ROC.
Winners!
Knocktober ended on a pleasant note, leaving everyone inquisitive to know what the final results will reveal. And when we announced the Top 3 ranks, not just the participants but even we were surprised. Here are the Top 3 rankers and it was definitely not an easy win.
Rank 1 : Sudalai Rajkumar & Rohan Rao
Rank 2 : Naveen Kumar Kaveti & Suprit Saha
Rank 3 : Sonny Laskar
Here are the final rankings of all the participants at the leaderboard.
All the Top 3 winners have shared their detailed approach & code from the competition. I am sure you are eager to know their secrets, go ahead.
Winner’s Solutions
Rank 3: Sonny Laskar
Sonny Laskar is a data science expert currently heading the IT Operations Analytics wing at Microland. He often participates in machine learning challenges to test his expertise. Here’s what Sonny says:

Sonny Laskar
Even though it was a binary classification problem, the data was not present in the standard labeled format. Hence many were confused as to what is the actual problem.
Another interesting thing was the “No IDs please” clause. Recently, we have observed that some competitions in Analytics Vidhya and Kaggle turned out to a leak – exploration problem which at the end of the day is of very less value to the client. Hence any leak exploration is strictly discouraged.
As always, I started with a few visualizations. Below are few of the plots:
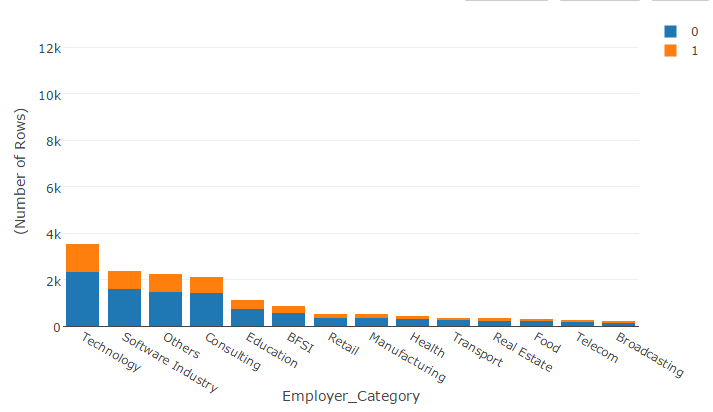
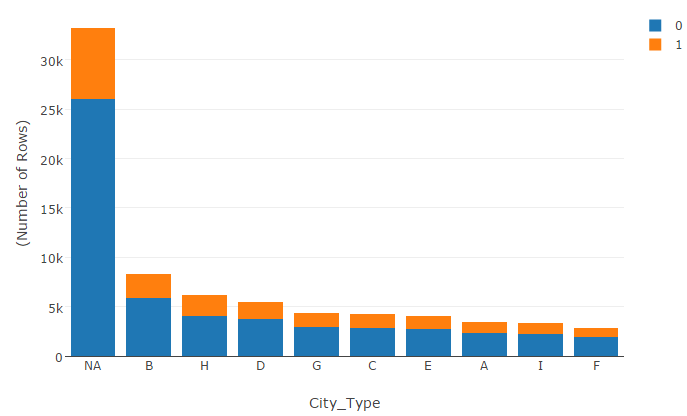
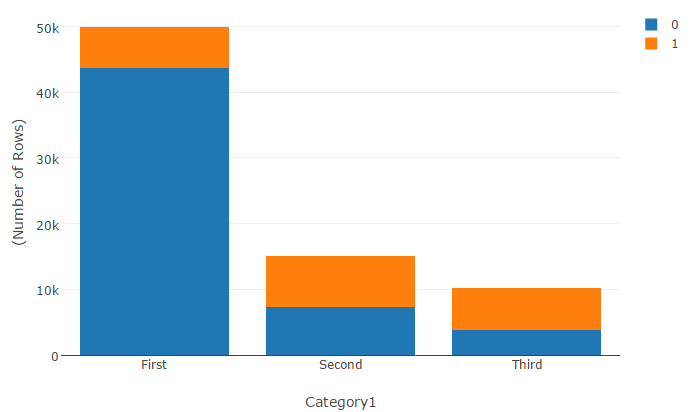
Feature Engineering
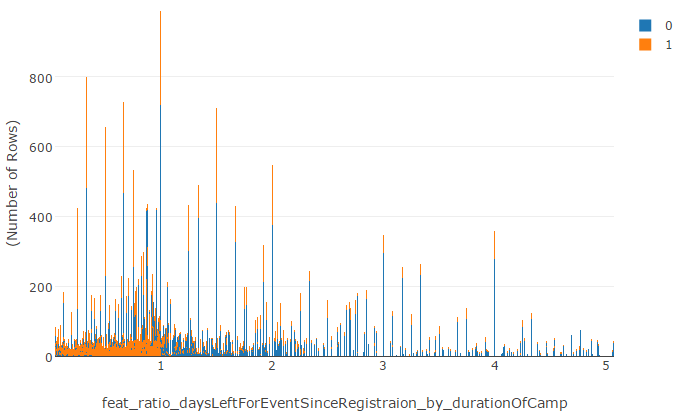
Like others, I also had created few time-based features. The ratio of the days left for the event to end to the duration of the camp was an interesting feature that worked for me. Another interesting feature was how many days have elapsed between the previous registrations by the same patient.
Plots above show that the 1’s occurred more if the patient registered for the event much closer to the event start date. May be as days pass, the patient loses interest.
Modelling
In my experience, tree-based models work better than linear models in such data sets. Hence I started with Xgboost, the universally accepted tree-based algo. Surprisingly, RandomForest didn’t work as well , might be because I didn’t tune that well. GBM performed slightly better than Xgboost.
I created two bags for both Xgboost and GBM and did a final rank average ensemble of the scores.
Key learnings
This competition reminded me of the thumb rule:
- Always trust your CV and don’t be overwhelmed by what the leaderboard says
- All it takes to win is one or two very good features
Link to Code
Rank 2: Naveen Kumar Kaveti & Suprit Saha
Naveen Kumar Kaveti and Suprit Saha are both statistical analyst at Walmart Labs, India. Naveen and Suprit are both data science enthusiasts and often participates in competitions to test their skills. Here’s what they shared:
Naveen Kumar
Suprit Saha
Initially we generated numerous features but later realized that some of them are performing very well in the train set but they are adding noise in the test set. In this competition we mainly focused on feature engineering rather than algorithm selection.
We built different models like logistic regression, random forest, xgboost and GBM (in h2o package) using our initial set of features and observed that, there is a significant difference between cross validation score and public leaderboard score. We realized that some of the features in train set have different distribution in test set then we started our hunt for finding out the variables, which are adding noise in the test set.
To start with, we compared the distribution of variables across test and train and then we validated our results against public leaderboard score to find out noise variables.
After eliminating noise variables, we tried aforementioned models again and among those GBM was outperforming others. Using only GBM we reached 8th position in the public leaderboard after that we tried different ensemble methods but none of them increased the score in public leaderboard.
Key learning from this competition is that, feature engineering is one of the most important part of modeling, probably much more than the choice of algorithm. This competition reminds us the famous quote by George Box “All models are wrong, but some are useful”. I think here the useful ones are the one with good set of features.
The major key for our success in this competition is elimination of noise variables and adding relevant features.
Some of the features, which helped us in pushing leaderboard score:
- Recency – How recent a patient is
- Frequency – How frequent a patient is
- Age_Prob – Probability for getting a favorable outcome of a patient belonging to age group
- Difference between registration date and camp start date
- Difference between registration date and camp end date
- Difference between registration date and first interaction date
- Camp duration
Tools used: R (Package: h2o)
Link to Code
Rank 1: Sudalai Rajkumar & Rohan Rao
Sudalai Rajkumar is a lead data scientist at Freshdesk and Rohan Rao is a lead data scientist at AdWyze. Their profound knowledge and deep understanding of machine learning concepts is truly inspiring. Here’s what they shared:
Our approach was to explore the data independently and merge our models towards the end to generate a strong ensemble.
SRK
Sudalai Rajkumar says:
I started off with a camp based 5 fold-cross validation where camps were disjoint among the folds. This worked decently for me. If there was a substantial increase in my CV score, there was some improvement in my LB score as well though not in the same magnitude. But one thing I realised was that I will not be able to create time based features in this methodology since this might cause a future leakage. From the data exploration, we can see that train and test are separated not only by camps but also by time. So, I created a validation set using the rows from the last few camps given in the training set and used the rest as development sample.
Feature Engineering
One thing I cherished a lot in this competition is feature engineering. Since I had some good amount of time during this hackathon unlike the recent ones, I spent time creating variables, checking the performance and then adding / discarding them.
To start with, I ran an xgboost model using all the variables and checked the variable importance. I discarded those features with low variable importance (A trick learned from Rohan!). Removing those did not affect the cv scores and public LB score.
Then I started creating additional variables. The ones that are included in my model and the reasoning for including the same are as follows:
1. Duration of the camp in days – if the duration is long, then more people might attend
2. Date difference between camp start date and registration date – If the person register close to the camp start date, then the chance of turning up for the camp is quite high.
3. Date difference between camp end date and registration date – Some registration dates fall after camp start date as well. So to understand whether registration is done well ahead of the final day of the camp.
4. Date difference between registration and first interaction – Frequent interactions might help gain more popularity for the camps.
5. Date difference between camp start date and first interaction – Very similar to the reasoning of (2).
6. Number of times the patient registered for a camp – To capture the individual characteristics.
7. Number of patients registered for the given health camp – To capture the camp characteristics.
8. Date difference between current registration date and the previous registration date – If the difference is a shorter time span, then there might be a higher chance to attend.
9. Date difference between current registration date and the next registration date – Same reasoning as that of previous one.
10. Mean outcome of the patient till the given date – To capture the historical patient outcome characteristics.
11. Format of the previous camp attended – To capture if the patient attends any particular format of camps.
12. Sum of donations given by the patient till the given date – If a patient donates more, then there might be a chance that the person is interested in attending the camps.
13. Total number of stalls visited by the patient till the given date – If a patient visits more stalls, then the chance of attending the camps might be high.
Variables that did not help me improve the score are:
1. Different ratio variables on the date i.e. one date differences divided by another.
2. Ratio variables using age, income and education.
3. Mean health score values of the previously attended camps.
4. Last known outcome value for the patient.
5. Bayesian encoding on categorical variables.
The reason could be that they were not really helpful or this information was already captured by some other variables present above.
Model
My final model was an xgboost which scored 0.8389 in public leaderboard and I bagged them thrice to get 0.8392.
Rohan’s approach:
Rohan Rao
As I was busy at the World Sudoku/Puzzle Championships, I had very less time in this hackathon. Hence, I decided to focus on building a tangential different model with features so as to blend well with SRK’s.
I spent 95% of my time in exploring the data and engineering features. I did not even have time to tune my parameters, so, stuck with the set I started with. I went with a minimalistic approach, carefully choosing the most effective features, which gave stable CV and LB scores.
I used the following raw features:
1. Category1
2. Category2
3. Age
4. Education Score
5. City Type
6. Income
These mainly capture metadata on the camps and the patients.
The following engineered features boosted my model’s performance:
7. Start_Date_Diff: Difference between start date of camp and registration date of patient.
8. End_Date_Diff: Difference between end date of camp and registration date of patient.
9. Prev_Date_Diff: Difference between registration date of patient and previous registration date of the patient.
10: Next_Date_Diff: Difference between registration date of patient and next registration date of the patient.
11. Count_Patient: Number of camps a patient registered.
12. Count_Patient_Date: Number of camps a patient registered on each date.
13. Donation_Flag: Binary indicator if the patient made a donation in the past.
Using the raw date features isn’t a good idea since the test data is split on time, hence, converting the date features into date differences was very useful.
I found that patients who donated had a higher response rate than other patients, and thats how donation_flag helped the model.
The other features are similar to SRK’s, which describe characteristics of the timing and patient.
Model
My final model was an XGBoost with these 13 variables. I also subsetted the data, excluding observations in 2003 and 2004, and ones where the registration date was missing.
It scored 0.8375 on the public LB.
We checked the correlation of our best performing models and to our surprise it was 0.93 – low correlation for a second level input, given both of us used the same modelling algorithm – XGBoost. The varied set of features in our base models is the reason for this. Hence we averaged both our models together to get to 0.8432 in the public leaderboard, which proved to be stable and robust, as we finished 1st on the public as well as the final private leaderboard.
On working together as a team
Sudalai: Rohan was very busy during the weekend with his World Championships. Inspite of his busy schedule, he managed to squeeze some time and create an awesome model with very few features and varied from my model. Salutes and thanks to him! It is always a great learning experience working with Rohan and look forward to the same in the future as well.
Rohan: It was fun and interesting to work with Sudalai, and our ensemble made a considerable difference at the end, which got us the win. Really happy with our team-work and performance. Thanks to SRK for all the help and support!
Link to Code
Learnings from the Competition
Below are the key learnings from this competition:
- Nothing beats Feature Engineering: Having seen in previous competitions as well, feature engineering remains a formidable part of building high prediction models. Don’t expect algorithms to always extract hidden features themselves. Of course they do to some extent, but what differentiates the winners from the rest is the thought process which went in creating these features. If you still don’t believe it, re-look at the code of each of the winner above!
- k-fold cross validation doesn’t always work: In time based problems, you can’t validate your classifier using a k folds strategy. Instead, a hold out validation approach seems more reliable. Therefore, you should know various methods of validation and use them judiciously.
- Exploratory Analysis always pays off: The toppers have shared their codes and if you spend time understanding the code, you will the amount of time spent in EDA. That was the only way for you to understand the mixes of camps have changed over time and hence you will need different way of looking at validation in this problem.
- Learn parameter tuning by doing: In today’s world, it is not about how to code an run an algorithm – a Google search will tell you that. What differentiates winners from others is the ability to tune parameters to bring out the best from an algorithm.
- Learn Ensembling & Model Averaging: When one model doesn’t help, bring in another. This technique is often used in competitions and has resulted in encouraging leaderboard positions. It’s should be next on your “to-learn” list.
EndNotes
As we come to the end of this article, I am sure you will agree with me that it was an incredible competition. We thoroughly enjoyed each & every bit of it. For all other participants who would like to share their codes with our fellow users, please post them in the comments below. And tell us more about your experience by dropping in your comments.
For all those, who didn’t participate in the competition, I am sure you are regretting it big time. To ensure that you don’t miss out on such competitions, subscribe for email alerts and follow the link below for all the upcoming competitions. And until we meet again for another round of face-off with the machine learning champions, keep learning & improving your skills.