

{kind=link}
Open data has gained public attention because of its role in training AI image generation models like Stable Diffusion, but its importance extends to research beyond AI. It gives researchers and developers access to large, publicly available datasets that support projects ranging from combating misinformation and phishing to solving global challenges.
Organizations like Common Crawl and LAION (Large-scale Artificial Intelligence Open Network) lead open data initiatives. By providing freely accessible, large-scale datasets, small research teams can access the same resources that fuel technological breakthroughs for major corporations. But what is open data, and how are Common Crawl and LAION shaping its role in future AI technology?

Related
What is the difference between artificial intelligence and machine learning?
They are related to an extent but quite different
The origins and role of open data in modern research
Why open data is essential for progress and innovation

Open data refers to datasets that are freely accessible for anyone to use, analyze, and share, often under licenses like Creative Commons Zero or Open Data Commons. Similar to open source code, open data and open source AI models give anyone interested in machine learning the tools they need to get started.
Research teams use open data to explore new areas that demand massive datasets. These projects would be impossible without access to these resources. Training AI models like ChatGPT or Stable Diffusion require diverse, large-scale datasets to ensure they generalize effectively across a range of tasks and contexts. A model trained on a narrow dataset risks overfitting, meaning it may perform well on specific data but struggle with other inputs.
Large datasets provide the volume of examples needed for deep learning models to capture complex patterns and relationships within the data. Without diversity and scale, AI models would fail to perform reliably in real-world scenarios or across the wide range of use cases we see today.
Common Crawl: The internet’s data archive
Common Crawl, a nonprofit founded in 2008, is a key provider of open data. It conducts web crawls similar to those performed by search engines like Google. However, instead of keeping the data locked in proprietary systems, Common Crawl makes it freely available to the public.
Common Crawl has amassed over 9.5 petabytes of web data, including text, images, and metadata from billions of web pages.
- Scale and scope: Since its inception, Common Crawl has amassed over 9.5 petabytes of web data, including text, images, and metadata from billions of web pages.
- Compliance and transparency: It respects web standards such as robots.txt, ensuring only publicly accessible content is collected.
- Applications: Beyond AI, Common Crawl’s datasets have been used to study web strategies against misinformation, track hyperlink hijacking used for phishing and scams, and measure censorship practices in countries like Turkmenistan.

Related
LAION: Turning raw data into AI-ready datasets
Common Crawl collects raw web data, while LAION refines it for machine learning applications. LAION is a nonprofit organization specializing in creating large, open datasets for AI training, such as its widely recognized LAION-5B dataset. It was started by a high school teacher and a 15-year-old student who wanted to democratize access to machine learning resources.
- LAION-5B: This dataset contains 5.8 billion text-image pairs curated from Common Crawl’s archives. It’s the backbone for many generative AI models, including Stable Diffusion from StabilityAI.
- Focus on diversity: LAION’s datasets include multilingual and multicultural data, allowing researchers to develop AI models that work across languages and regions.
- Accessibility: By releasing its datasets under open licenses, LAION ensures that developers of all scales, not only large corporations, can access high-quality training data.
There is a world of research and development focused on solving critical global challenges, much of which is overshadowed by AI hype, deepfakes, and commercial AI assistants. These organizations demonstrate the transformative power of open data by providing researchers and developers access to resources that were once exclusive to industry giants.
The importance of open data in AI and global research
Smaller research teams and independent developers benefit
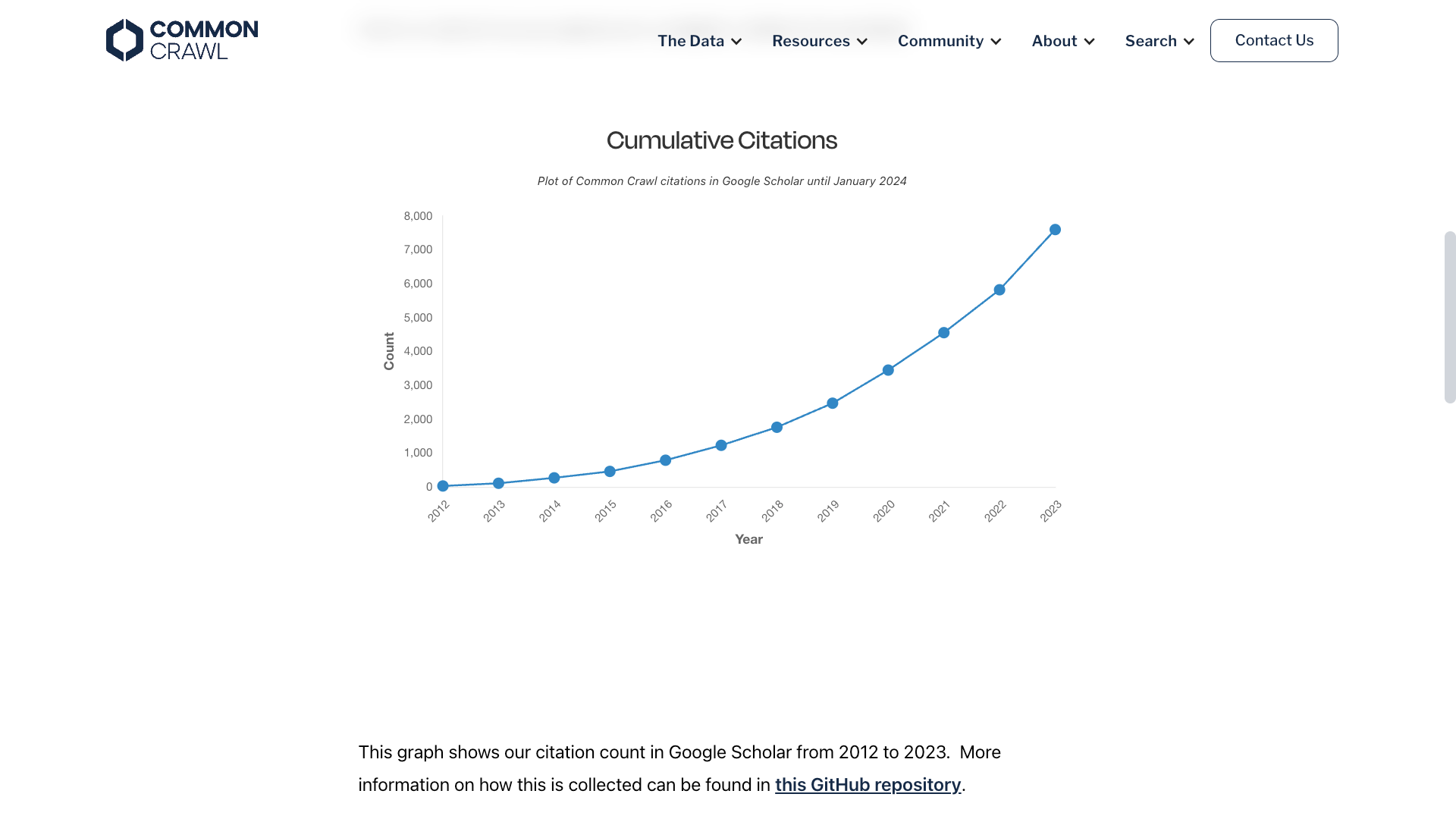
Open data initiatives like Common Crawl and LAION are essential for training generative AI systems. The LAION-5B dataset includes over 5 billion CLIP-filtered image-text pairs and was used to train image generation models like Midjourney and Stable Diffusion.
However, the impact of open data extends beyond AI:
- Global research benefits: From studying internet censorship to tracking climate change, open data fuels research that addresses real-world challenges.
- Leveling the playing field: Smaller research teams and independent developers now have access to data resources previously dominated by large tech corporations, enabling innovation at every level.
- Transparency in AI development: By making datasets open, organizations like LAION allow scrutiny of the data used in training models, addressing concerns about bias and misuse.
In an increasingly data-driven world, the availability of open data supports innovation outside big business.
Why publicly available data matters
In an increasingly data-driven world, the availability of open data supports innovation outside big business. Initiatives like Common Crawl and LAION ensure that the development of AI systems and other research breakthroughs remains free from cost and access barriers to training datasets.
As AI grows, ensuring access to open data will become increasingly important to prevent a technological gap as wide as the existing economic divide. AI is a powerful tool that should not be monopolized by large corporations, especially those with a track record of data breaches.
Addressing ethical and practical challenges
What if you don’t want AI to be trained on your data?
One of the main criticisms of open datasets like LAION-5B is the inclusion of copyrighted material. Since web crawlers like Common Crawl collect data from publicly available websites, these datasets may inadvertently include copyrighted images or text, sparking debates about consent and intellectual property rights.
While some argue that scraping publicly accessible data is legally permissible, others point out that it raises ethical questions about how the data is used. Tools like Spawning.ai’s Have I Been Trained? allow artists to opt out of datasets like LAION-5B, but widespread adoption of such measures remains a challenge.

Related
AI art in Project Zomboid’s update sparks community outrage
The more extreme elements of the anti-AI movement have a history of hostile tactics
Potential biases and misinformation
Another challenge is the quality and diversity of open datasets. When original data sources contain bias or misinformation, AI models become more prone to hallucinations, which are inaccurate or misleading results. Organizations like LAION work to address this through continued filtering and curation, but the problem cannot be eliminated.
Balancing openness and regulation
As open data takes on a more central role in technological development and AI image generation models become accessible enough to run on personal computers for free, the need for comprehensive regulatory frameworks becomes increasingly urgent. Balancing the benefits of openness with safeguards against misuse will require global collaborative efforts from governments, nonprofits, and private sector organizations.
Open data is fueling innovation but raises critical questions
The work of Common Crawl and LAION showcases how open data can democratize access to information, foster transparency, and accelerate global innovation. By providing researchers with the tools they need to train AI systems and conduct groundbreaking studies, these organizations help shape the future of technology and science.
Yet, as the use of open data expands, so do the ethical and practical challenges it presents. From debates about intellectual property to concerns about bias, the road ahead will require careful thought and collaboration to ensure open data remains a force for good. Open data’s potential to benefit society outweighs its risks if used responsibly.