

{kind=link}
This blog focuses on scaling many model training. While much of the buzz is around large model training, in recent years, more and more companies have found themselves needing to train and deploy many smaller machine learning models, often hundreds or thousands.
Our team has worked with hundreds of companies looking to scale machine learning in production, and this blog post aims to cover the motivation and some best practices for training many models. Using the approaches described here, companies have seen order-of-magnitude performance and scalability wins (e.g., 12x for Instacart, 9x for Anastasia) relative to frameworks like Celery, AWS Batch, AWS SageMaker, Vertex AI, Dask, and more.
In this blog, we’ll cover:
- Why companies are doing many model training
- How to use Ray to train multiple models
- The properties of Ray that enable efficient many model training
Why train many models?
While cutting edge applications of machine learning are leading to an explosion in model size, the need for many models cuts across industries.
As a few examples
- Models per geographical zone at Instacart: Instacart uses machine learning for a huge variety of tasks including delivery ETA prediction, planning the supply of couriers, and optimizing routing models for shoppers. For each use case, one model is trained for each zone, often a geographical location like a zip code. Separate models are also trained for different attributes like the time of the day. This results in tens of thousands of models. Using the approach in this blog post, Instacart reduced training times for these models by 12x compared to AWS batch and Celery, from days down to hours.
- Search and ranking for ecommerce: Ecommerce companies we work with use machine learning for applications ranging from query suggestion to ranking to personalization. One of the most important use cases is product classification, in which every new product sold on the site is tagged with hundreds or thousands of attributes (e.g., soft, green, kitchen, holiday, …) often based on pictures of the product. These attributes are used to improve product search. It’s very common to use one model per attribute, leading to an explosion of models being trained and deployed.
- Per customer and per product forecasting and modeling: One B2B analytics company we work with trains per-customer models to forecast growth as well as churn. As a result, they need to frequently retrain and redeploy thousands of models. Another multinational manufacturing company trains predictive models for each of tens of thousands of products. Using the approach in this blog post, both companies were able to achieve significant scalability and performance wins relative to their previous solutions, often by an order of magnitude. As another forecasting example, Nixtla ran a benchmark training 30,000 models. In a separate experiment, they trained one million models in 30 minutes.
- Finding the best model among many (hyperparameter tuning): Another B2B analytics company we work with experiments with thousands of types of models (both different types of models as well as different model hyperparameters) so that they can choose the best one, and they do this for every single one of their customers. This is essentially a massive hyperparameter tuning job.
Let’s go over the techniques these companies use to achieve these results. We’ll describe a couple of the most popular methods.
These approaches use Ray to scale many model training. For an overview of Ray, check out the Ray documentation or this introductory blog post. Later in this blog post, we include links showing how companies like OpenAI, Uber, Shopify, Instacart, Netflix, Lyft, Cruise, and Bytedance are scaling their machine learning workloads with Ray.
How to train many models
While there are a growing number of blog posts and tutorials on the challenges of training large ML models, there are considerably fewer covering the details and approaches for training many ML models. We’ve seen a huge variety of approaches ranging from services like AWS Batch, SageMaker, and Vertex AI to homegrown solutions built around open source tools like Celery or Redis.
Ray removes a lot of the performance overhead of handling these challenging use cases, and as a result users often report significant performance gains when switching to Ray. Here we’ll go into the next level of detail about how that works.
Approach 1: Using Ray Core (1 task per file)
Suppose you already have a big list of model training configurations (e.g., paths to individual model data files for each zip code or SKU) and just need to parallelize execution of a model training function. Let’s run this with Ray. In the following example, we’ll train 1 million scikit-learn models on different input files.
First, the serial implementation:
# For reading from cloud storage paths.
from smart_open import smart_open
import pandas as pd
def train_model(file_path: str):
data = pd.read_csv(smart_open(file_path, "r"))
## Train your model here.
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
# (Column names are anonymized)
lr.fit(data[["id4", "id5"]], data["v3"])
## Write outputs.
# smart_open(output, "w").write(pickle.dumps(lr))
models_to_train = [
f"s3://air-example-data/h2oai_1m_files/file_{i:07}.csv"
for i in range(1000000)
]
# This will take much too long serially.
for file in models_to_train:
print("Training model serially", file)
train_model(file)
We could parallelize this directly using ray.remote functions, but to make things easier we’ll use Ray’s multiprocessing library— one of Ray’s distributed libraries:
from ray.util.multiprocessing import Pool
import tqdm
# Create a pool, where each worker is assigned 1 CPU by Ray.
pool = Pool(ray_remote_args={"num_cpus": 1})
# Use the pool to run `train_model` on the data, in batches of 10.
iterator = pool.imap_unordered(train_model, models_to_train, chunksize=10)
# Track the progress using tqdm and retrieve the results into a list.
list(tqdm.tqdm(iterator, total=1000000))
Wrapping the call to the pool will give us a nice progress bar to monitor progress. Internally, Ray dispatches tasks to workers in the cluster, automatically handling issues such as fault tolerance and batching optimizations:
We can see in the Ray dashboard the above job takes just a few minutes to run on a 10-node cluster. Each task reads the input file from S3 before training the model (a no-op in the example code above):
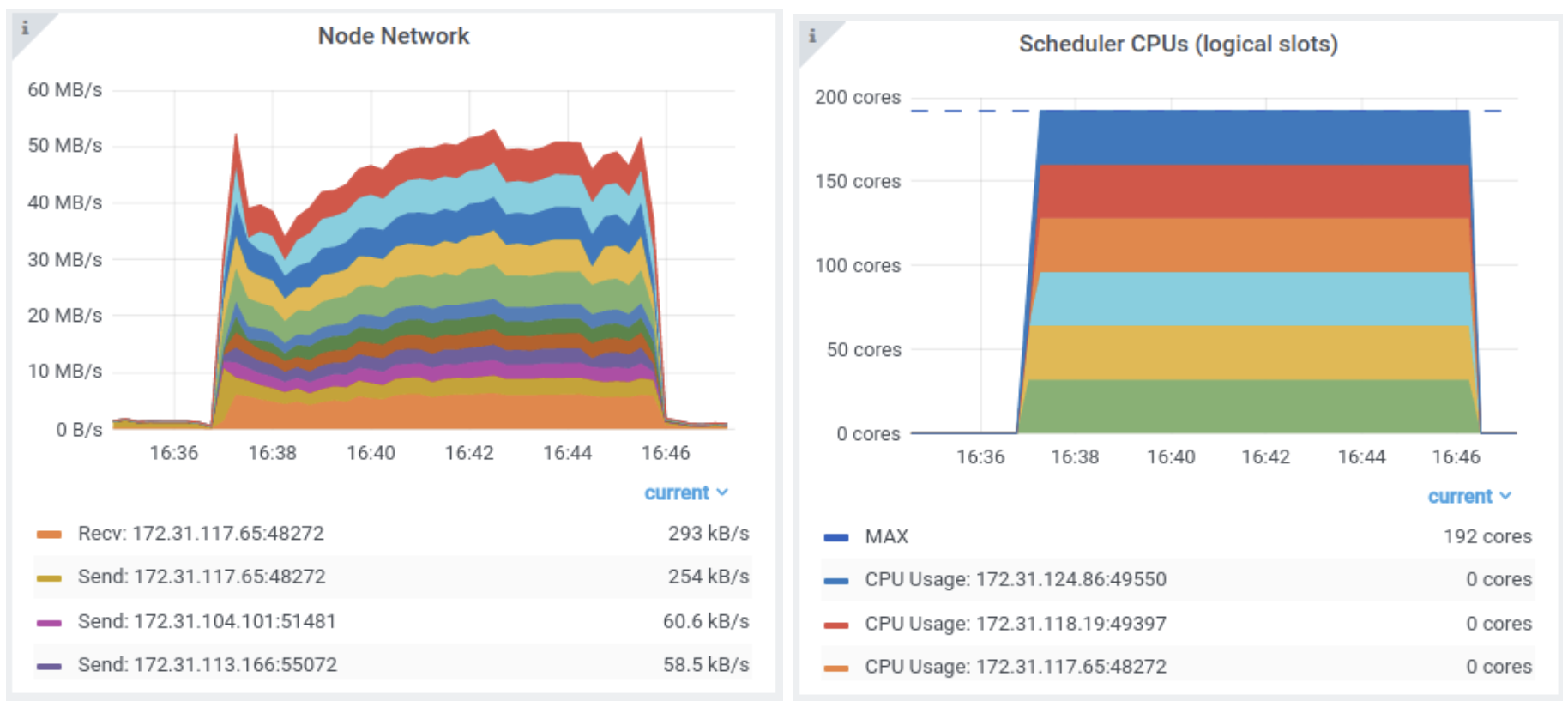
It takes about 10 minutes to train 1 million models from individual data files using Ray’s multiprocessing library. That was pretty simple. But what if your data isn’t already organized by model?
Approach 2: Using Ray Data (grouping data by key)
Often your data will be in some other format, such as parquet files (e.g., the output of a separate ETL job), and will not be already partitioned by model. You could turn to a separate Spark cluster to generate those nice single-model files we had in Approach 1.
To keep things in the same script, here we’ll show how to use Ray’s Dataset library to group a dataset by customer ID, prior to training a model on each customer. First, we load the data using the read_csv method of Ray Datasets, and group it by our desired grouping key:
import ray
ds = ray.data.read_csv("s3://air-example-data/h2oai_benchmark")
# Repartition the single CSV into 500 blocks to increase the parallelism.
ds = ds.repartition(500)
# Compute our (dummy) `customer_id` key as the concatenation of the
# `id3` and `v1` columns and then group the dataset by it.
ds = ds.add_column("customer_id", lambda r: r["id3"] + r["v1"].astype(str))
ds = ds.groupby("customer_id")
We’ll use the special map_groups() function on GroupedDataset, which takes in a batch of data and returns one or more results. We’ll return a single trained model for each batch of data:
def train_model(data):
## Train your model here.
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(data[["id4", "id5"]], data["v3"])
# Return a single dict of the model and stats, etc.
return [{
"coef": lr.coef_,
"intercept": lr.intercept_,
"customer_id": data["customer_id"][0],
}]
# Execute the model training.
ds = ds.map_groups(train_model)
# Write the results to destination files.
# ds.write_parquet("s3://path/to/output")
When this executes, Ray’s Dataset library will execute the distributed shuffle operations needed to group the data by customer ID, and then can parallel apply the given model training function to generate the model.
The takeaway here is that Ray’s swiss army knife of libraries allows us to scale this task to a cluster in just Python, without having to wrangle multiple distributed systems or services.
Training Multiple Larger Models
Suppose we wanted to train multiple larger models, each requiring a GPU, or perhaps multiple processes to train in parallel. Ray’s resource-based scheduling lets us handle that seamlessly.
For models requiring GPU resources, we could tell Ray to schedule tasks onto GPUs by specifying num_gpus=1 as a remote arg. For example,
# Create a pool that assigns each worker a GPU.
Pool(ray_remote_args={"num_gpus": 1})
# Execute the model training, telling Ray to assign 1 GPU per task.
ds = ds.map_groups(train_model, num_gpus=1)
Similarly, if we wanted to use multiple CPUs per model (e.g., configuring sklearn to use 8 CPUs per model), we could set num_cpus=8 as a remote arg to tell Ray to reserve 8 CPU slots per training task:
# Create a pool that assigns each worker 8 CPUs.
Pool(ray_remote_args={"num_cpus": 8})
# Execute the model training, telling Ray to reserve 8 CPUs per task.
ds = ds.map_groups(train_model, num_cpus=8)
Using Ray AIR for distributed training
For higher-level distributed training APIs, you may want to pull from Ray AIR libraries such as Ray Train and Ray Tune, which are designed to manage the execution of multiple computationally intensive model training jobs. Train runs single distributed training jobs and can work with Tune to run multiple of these jobs at once.
Tune can also run many simple model training jobs, but is a bit less scalable in this dimension than the other approaches (think hundreds of models instead of millions) . Here’s an example of using Tune to execute the Approach 1 example from above (see also the Tune Experiments User Guide):
from ray import tune
# For reading from cloud storage paths.
from smart_open import smart_open
import pandas as pd
def trainable_func(config: dict):
data = pd.read_csv(smart_open(config["file_path"], "r"))
## Train your model here.
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(data[["id4", "id5"]], data["v3"])
# Return a single dict of the model and stats, etc.
return {
"coef": lr.coef_,
"intercept": lr.intercept_,
"customer_id": data["customer_id"][0],
}
# Tune is designed for up to thousands of trials.
param_space = {
"file_path": tune.grid_search([
f"s3://air-example-data/h2oai_1m_files/file_{i:07}.csv"
for i in range(1000)
])
}
tuner = tune.Tuner(trainable_func, param_space=param_space)
print(tuner.fit())
Compared to directly using Ray tasks, Tune offers:
- Status reporting and tracking, including integrations and callbacks to common monitoring tools.
- Checkpointing of trials for fine-grained fault-tolerance.
- Gang scheduling of multi-worker trials.
Why Ray is great for training many models
To summarize, Ray is great for many-model training for a few reasons.
- Flexible scheduling: Ray provides lower overhead for per-model training task (milliseconds, instead of seconds to minutes). This is in contrast to training frameworks like SageMaker that launch docker containers or nodes per task. In the examples above, Ray is able to multiplex tasks onto individual processes, for lower per-task overhead.
- Unification: Ray’s collection of built-in libraries means you can performantly handle both data preprocessing and training with just a few lines of Python, instead of spinning up new distributed systems. This is what enables the example in Approach 2 to run as a single Ray script.
Ray also excels at other use cases that stretch the boundaries of existing frameworks. For example, distributed training of large single models, or distributed serving of many different models. More on these topics in future blog posts.
More about Ray
More relevant material for learning about Ray
- To get started with Ray, check out our GitHub and documentation or ask questions on our forums.
- In addition to the use cases described in this blog, Ray includes libraries for scaling training, reinforcement learning, hyperparameter tuning, model serving, and data ingest & processing.
- Learn about how Ray integrates with the rest of the machine learning ecosystem, including training frameworks like PyTorch, TensorFlow, Horovod, XGBoost, Scikit-learn, Hugging Face, and LightGBM. Ray also integrates with MLOps frameworks like Weights & Biases, MLFlow, Arize and data platforms like Snowflake and Databricks.
- Learn how OpenAI trains their largest models including ChatGPT using Ray.
To learn more about how companies like Uber, Shopify, Cohere, Netflix, Lyft, Cruise, Bytedance, and others are building on Ray, check out the talks from the recent 2022 Ray Summit.
Article originally posted here by Eric Liang and Robert Nishihara of Anyscale. Reposted with permission.