

{kind=link}
Editor’s note: Noah is a speaker for ODSC West 2021. Be sure to check out his talk on deepfakes, “Identifying Deepfake Images and Videos Using Python with Keras,” there!
Deepfake videos have generated a lot of interest since they first started appearing in the dark corners of the internet in late 2017. By now, almost everyone has seen impressive examples of deepfake videos (if you haven’t, just search YouTube and you’ll find plenty!), but most people don’t know how they’re made and just accept them as a natural but mysterious consequence of modern AI. Even many people familiar with the general outlines of neural networks don’t know how supervised learning is used to power this remarkable video editing technology.
The point in this post is to show how the basic idea behind a popular version of deepfakes—the face swap—not only is very accessible and intuitive, but it beautifully illustrates and builds upon one of the most elegant ideas in all of deep learning: the autoencoder. In an upcoming workshop, I’ll discuss methods for using deep learning to detect deepfakes; these methods are often informed by the processes by which deepfakes are produced.
Autoencoders
An autoencoder is a neural network with multiple layers that first get progressively narrower (these form the encoder portion of the autoencoder) and then progressively widen back to the original size (this second half is the decoder):
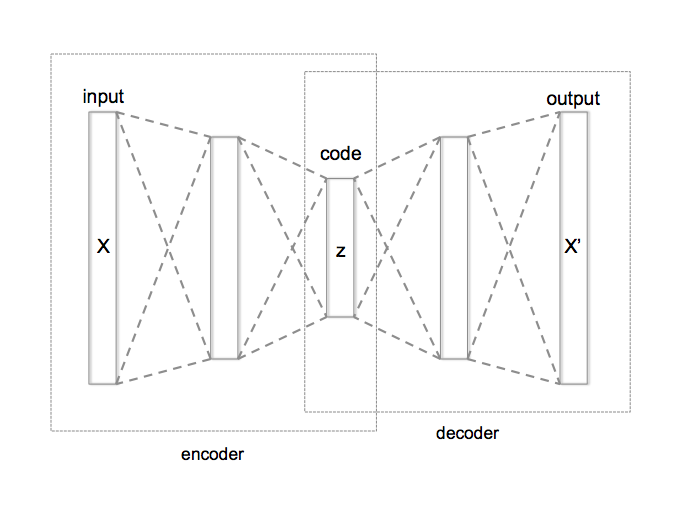
Image source: by Chervinskii, on Wikipedia, license CC BY-SA 4.0
This neural network is trained on the self-supervised task of returning the exact same data point that it is fed each time. This sounds bizarre at first, but what’s really happening is that by passing all the data through the narrow middle region of the autoencoder, the neural net is forced to compress the data—and due to the magic of deep leaning, it finds on its own the best way of doing this, through some internally learned conceptualization of the data. To put it more intuitively, the autoencoder is shown lots of data and told it must find a way to compress the data like a zip file, and it realizes the best way to do this is by first understanding the meaning of the data.
![]()
Autoencoding Different Faces
When training an autoencoder on a data set consisting of many images of different faces, the autoencoder learns whatever it needs to describe a face with as few numbers as possible. For instance, it might find a way to quantify the skin tone, the hair color, the hair style, the shape of the face, the shape and location of the facial features, etc. We don’t have to know how it works; we just run it and see that it does. The encoder part of the autoencoder is what translates a face into this collection of numbers summarizing the face, then the decoder part sees these numbers and attempts to reconstruct the face from them.
Autoencoding One Face
If we train an autoencoder on many different photos of the same person, then it doesn’t need to learn how to quantify the distinguishing characteristics of the person—instead, the autoencoder focuses on quantifying the person’s expression and orientation in each photo. For instance, it might learn to numerically encode the angle the head is rotated, the direction the eyes are pointing, how much the mouth is open, the extent to which the person is smiling, etc.
In practice, the numerical features autoencoders learn are not as simple and anthropomorphic as the ones mentioned here, but hopefully explaining it this way at least gives you a sense of what the autoencoder does with faces.
Face Swapping
Back to our face-swap task. Suppose we want to put Person A’s face onto a movie with Person B. We’ll do this by using two interlinked autoencoders. We use photos of Person A to train an autoencoder to compress and then reconstruct their face, and similarly, we use photos of Person B to train an autoencoder for their face—except we partially merge these two autoencoders by having them use the same encoder (so that only the decoder is customized to each person). The result is that a collection of numbers summarizing a face’s orientation and expression can now be decoded into either Person A’s face or Person B’s face. Then we’re ready to play the game: for each frame in the movie, we locate Person B’s face and encode, then we decode it using Person A’s decoder.
That’s all there is to it. But that was pretty brief, so let’s unpack that last sentence.
For concreteness, let’s pretend one of the numbers the autoencoder discovers measures how much the lips are smiling. When Person B has a big smile, this number will be large—and since we use the same encoder for both Person A and Person B, we know that the Person A decoder will interpret this large number as a large smile on Person A’s face. This happens simultaneously for everything essential about their faces: what direction their eyes are looking, whether their mouth is open and how much and in what shape, etc. In this way, whatever Person B’s face is doing in each movie frame is replaced with a synthetic photo of Person A doing the exact same thing. In other words, Person B’s face is translated into Person A’s face in a way that preserves the expression, orientation, etc.
Conclusion
This is just one type of deepfake (the face-swap) and just one type of methodology for it (linked autoencoders), but hopefully, it gave you a sense of some of the cool ideas behind deepfakes!
This essay is adapted from Noah Giansiracusa’s book “How Algorithms Create and Prevent Fake News: Exploring the Impacts of Social Media, Deepfakes, GPT-3, and More,” about which Paul Romer—Nobel Laureate and former Chief Economist of the World Bank—said “It’s a joy to read a book by a mathematician who knows how to write… There is no better guide to the strategies and stakes of this battle for the future.”
More on Noah’s upcoming ODSC West session: This workshop will cover the basic methodologies used for creating deepfakes, the public databases available for training, and some methods (implemented in Python with Keras) for building a detection algorithm. While there are some fully trained detection systems available to web-based users, it is important to know how these systems work and to be able to adjust, adapt, and fine-tune them—skills this workshop aims to equip you with.
 Article by Noah Giansiracusa, Assistant Professor of Math and Data, Bentley University
Article by Noah Giansiracusa, Assistant Professor of Math and Data, Bentley University
Noah received a PhD in mathematics from Brown University and is an Assistant Professor of Mathematics and Data Science at Bentley University, a business school near Boston. He previously taught at U.C. Berkeley and Swarthmore College. He’s received multiple national grants to fund his research and has been quoted in Forbes, Financial Times, and U.S. News. He is the author of “How Algorithms Create and Prevent Fake News: Exploring the Impacts of Social Media, Deepfakes, GPT-3, and More,” about which Nobel Laureate and former Chief Economist at the World Bank Paul Romer said, “There is no better guide to the strategies and stakes of this battle for the future.”