

The first wave of AI features has been defined by summarization. Apple, Google, and Samsung all offer some version of notes, notifications, or email summaries, in some cases without the need to connect to the internet at all. That makes a good bit of sense: large language models are trained on mountains of text, so it might follow that they’re able to condense that text efficiently.
No Thanks, Keep Reading
If you’ve used any of these features, you know that their quality is mixed at best, but they’re ultimately laying the groundwork for something better. The next big wave of AI tools is focused on not just feeding AI text, but letting it deal with the vast wilderness of things happening on your screen. The various implementations vary, but they all point to the same thing: a contextual AI that can act as a second pair of eyes on whatever you’re doing.
Here’s why it’s the sweet spot for generative AI, and why device makers are at a real advantage when it comes to offering these features to users.

{kind=link}
A second pair of eyes
Circle to Search, Pixel Screenshots, and Copilot Vision
It’s not dependent on generative AI, but Google’s Circle to Search feels like the first 2024 example I can think of where letting software see your screen came with advantages that outweighed the costs.
Circle to Search, which debuted on the Samsung Galaxy S24, but is technically a part of Android now, is essentially a specialized version of reverse image search. Long-press your phone’s navigation bar and the screen will freeze, letting you circle anything on your phone you want to learn more about.
That could be a pair of shoes someone’s wearing in a TikTok video, or text on a poster. Circle to Search can pull up information about all of them, helping you find a product you want to buy, defining a term, or translating text you don’t understand.
As of December 2024, anything you’ve circled in Circle to Search can also be sent to Pixel Screenshots, a new app introduced alongside the Pixel 9 for cataloging screenshots. It uses AI to sort screenshots into different categories, and as part of a recent update, suggests the content from images as suggestions in GBoard.
Those features, along with the general ability to just ask Gemini questions about what’s on your screen (mostly focused on summarization, unless you’re watching a video), gesture at what’s possible when you give AI a view of what you’re looking at.
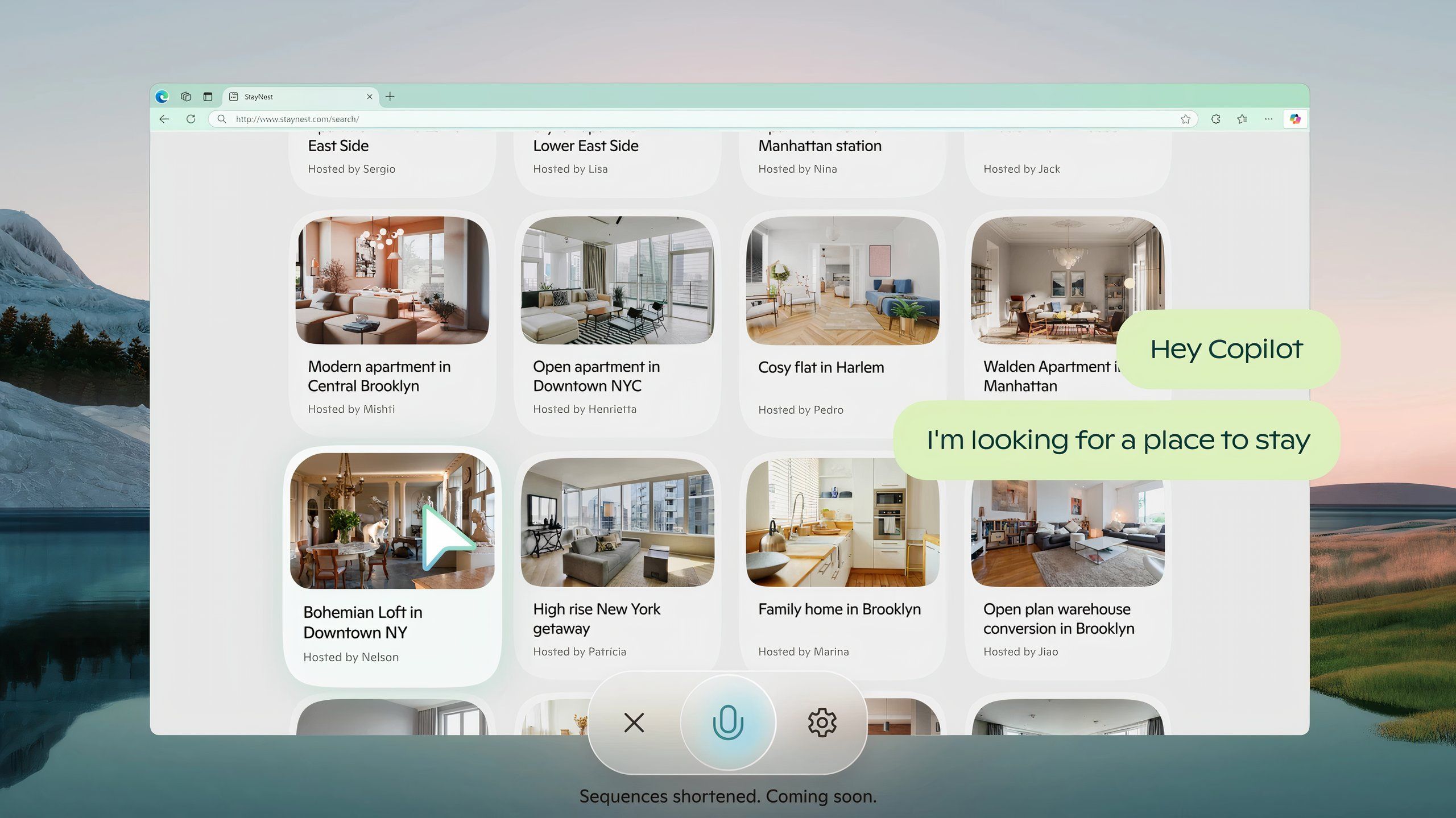
Microsoft has started to take those basic ideas even further in the Edge browser. It’s new experimental Copilot Vision feature lets you talk to the AI assistant while you’re browsing and answer questions about whatever you’re looking at. The feature is limited and capable of producing errors in much the same way a normal text chat with Copilot can, but it represents what I think might be the sweet spot for these kinds of AI features.
You can ask for basic recommendations that you could probably answer for yourself just by exploring a website more thoroughly, but also make more specific requests, even letting Copilot help you cheat on a round of Geoguesser.
The number of websites you can use Copilot Vision on is deliberately limited for now, which Microsoft says is part of the considerations for security and copyright it’s making, but there are plans to expand. Any data connected to what you actually say during a Copilot Vision session, or the contextual website information connected to those questions and requests, isn’t saved after you’ve turned off Copilot Vision.
It seems like an even more natural way of getting help than Circle to Search or Pixel Screenshots, and I wouldn’t be surprised if it became the norm across all the major AI platforms. Or at least the ones integrated into operating systems or web browsers.
Letting AI view your screen can have drawbacks
Device makers are in a unique position to guarantee users’ safety
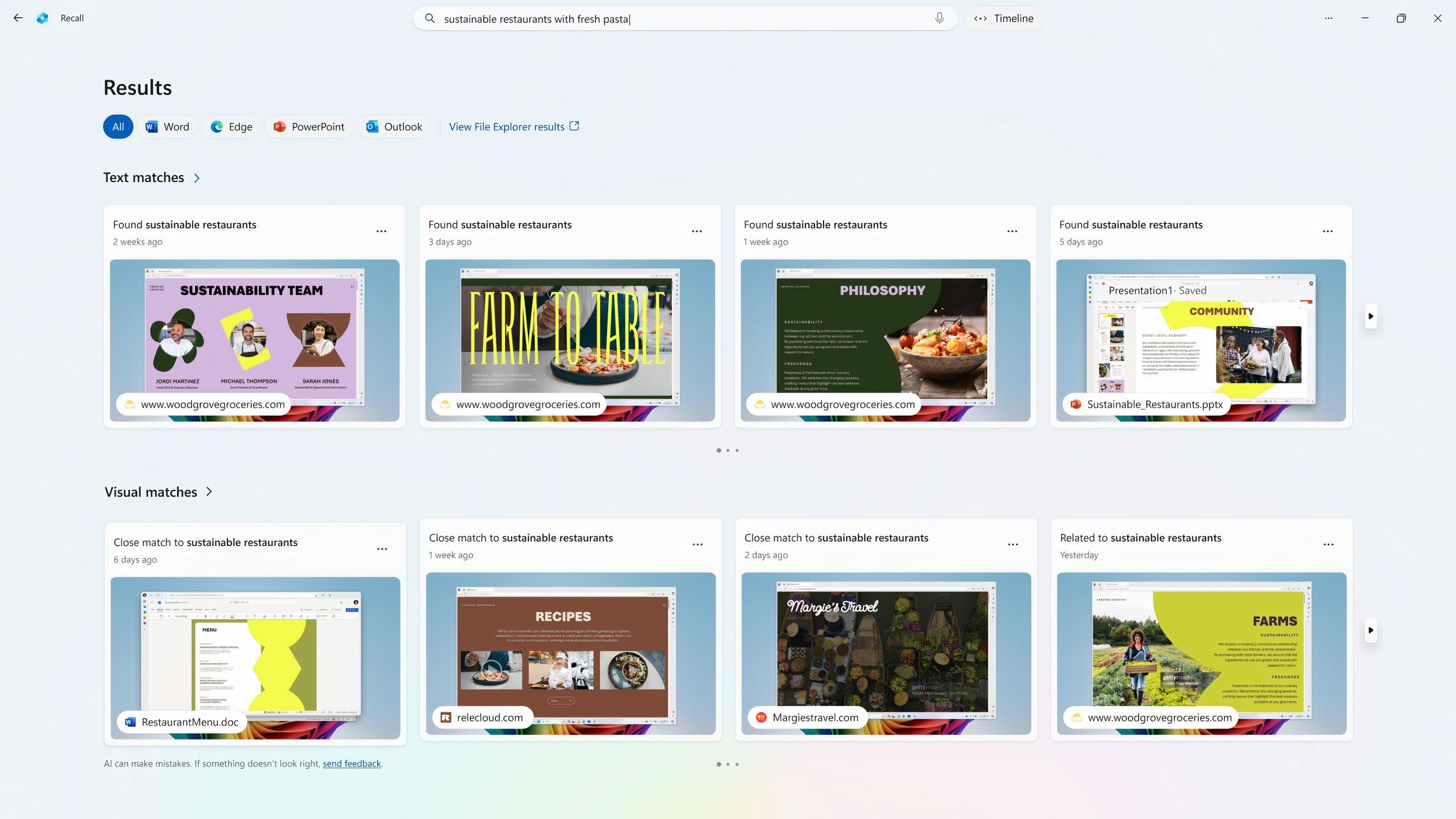
The problem with all of these screen sharing features is that people are often looking at things they wouldn’t want to share with Al. That’s why Microsoft insists that Copilot Vision doesn’t remember anything it “sees.” The company was heavily criticized for privacy issues with Windows Recall, which, unlike Pixel Screenshots, captures images of your screen without your input to create a timeline of everything you’ve done on your computer.
There were obvious problems with that idea — an AI shouldn’t capture a screenshot of your bank account or government ID — and Microsoft had to completely overhaul how Recall works and stores screenshots to get it in a position to be actually released.
The problem with all of these screen sharing features is that people are often looking at things they wouldn’t want to share with Al.
Owning an operating system and the hardware it runs on gives you a unique advantage with these kinds of AI features, because you can have precise control of what these models have access to and when. That’s a key element of Apple’s privacy-focused approach to AI on the iPhone, and one of several reasons it hasn’t released an updated version of Siri that can access your phone’s screen and apps.
An AI less focused on general knowledge is good

The large language models that power generative AI might be trained on a huge amount of data, but their ability to actually have a deep well of accurate knowledge is not guaranteed. They can come up with incomplete answers just as often as they can lie to a straightforward question.
The strength of AI apps like Google’s NotebookLM is that they make an AI model responsible for answering questions about a much smaller amount of information: whatever sources you upload yourself. Letting AI see your screen feels like the upper limit of that same kind of skill, where the limitation you’re providing is whatever you’re seeing.
It’s wider than a few PDFs or YouTube videos, but it’s much narrower than expecting an AI to be an answer machine for all human knowledge. That seems like the right level for a useful AI to be operating at.