



{kind=link}
Introduction
Apache Spark is an open-source unified analytics engine for large-scale data processing. Spark’s in-memory data processing capabilities make it 100 times faster than Hadoop. It has the ability to process a huge amount of data in such a short period. The most important feature of Spark is in-memory data processing. Here is a list of interview questions on Apache Spark.
This article was published as a part of the Data Science Blogathon.
Table of contents
- Introduction
- Apache Spark Interview Questions
- 1. What is the spark?
- 2. What is RDD in Apache Spark?
- 3. What is the Difference between SparkContext Vs. SparkSession?
- 4. What is the broadcast variable?
- 5. Explain Pair RDD?
- 6. What is the difference between RDD persist() and cache() methods?
- 7. What is Spark Core?
- 8. What is RDD Lineage?
- 9. What is the difference between RDD and DataFrame?
- 10. Explain Accumulator shared variables in Spark?
- Frequently Asked Questions
Apache Spark Interview Questions
Spark is one of the interviewer’s favorite topics in big data interviews, so in this blog, we’ll go over the most important and frequently asked interview questions about Apache Spark. Let’s begin…

1. What is the spark?
Spark is a general-purpose in-memory compute engine. You can connect it with any storage system like a Local storage system, HDFS, Amazon S3, etc. It also provides you the freedom to use a resource manager of your choice, whether Yarn, Mesos, Kubernetes, or standalone. It is designed to manage batch application workloads, iterative algorithms, interactive queries, and streaming. Spark supports high-level APIs such as Java, Scala, Python, and R. It is built in Scala language.
2. What is RDD in Apache Spark?
RDDs stand for Resilient Distributed Dataset. It is the most important building block of any spark application. It is immutable. RDD properties are:-
- Resilient:- It has fault tolerance properties and can quickly recover lost data.
- Distributed:- Data are distributed across multiple nodes for faster processing.
- Dataset:- Collection of data points on which we perform operations.
RDD provides fault tolerance through a lineage graph. A lineage graph keeps track of transformations to be executed after an action has been called. The Lineage graph helps to recompute any missing or damaged RDD because of node failures. RDDs are used for low-level transformations and actions.
3. What is the Difference between SparkContext Vs. SparkSession?
In Spark 1.x version, we must create different contexts for each API. For example:-
- SparkContext
- SQLContext
- HiveContext
While in the spark 2.x version, a new entry point named SparkSession was introduced, single-handedly covering all of the functionality. No need to create different contexts for the entry points.
SparkContext is the main entry point for accessing the spark functionalities. It represents a spark cluster’s connection which is useful in building RDDs, accumulators, and broadcast variables on the cluster. We can access the default object of SparkContext in spark-shell, which is present in a variable name “sc.”
SparkSession:- Before the spark 2.0 version, we need different contexts to access the different functionalities in spark. While in spark 2.0, we have a unified entry point named SparkSession. It contains SQLContext, HiveContext, and StreamingContext. No need to create separate ones. The APIs accessible in those contexts are likewise available in SparkSession, and SparkSession includes a SparkContext for real computation.
4. What is the broadcast variable?
Broadcast variables in Spark are a mechanism for sharing the data across the executors to be read-only. Without broadcast variables, we have to ship the data to each executor whenever they perform any type of transformation and action, which can cause network overhead. While in the case of broadcast variables, they are shipped once to all the executors and are cached over there for future reference.
Broadcast Variables Use case
Suppose we are doing transformations and need to look up a larger table of zipping codes/pin codes. It’s not feasible to send the data to each executor when needed, and we can’t query it each time to the database. So, in this case, we can convert this lookup table into the broadcast variables, and Spark will cache it in every executor.
5. Explain Pair RDD?
The Spark Paired RDDs are a collection of key-value pairs. There is two data item in a key-value pair (KVP). The key is the identifier, while the value is the data corresponding to the key value. A few special operations are available on RDDs of key-value pairs, such as distributed “shuffle” operations, grouping, or aggregating the elements by a key.
val spark = SparkSession.builder()
.appName("PairedRDDCreation")
.master("local")
.getOrCreate()
val rdd = spark.sparkContext.parallelize(List("Germany India USA","USA India Russia","India Brazil Canada China"))val wordsRdd = rdd.flatMap(_.split(" "))val pairRDD = wordsRdd.map(f=>(f,1))pairRDD.foreach(println)
Output:-
(Germany,1)
(India,1)
(USA,1)
(USA,1)
(India,1)
(Russia,1)
(India,1)
(Brazil,1)
(Canada,1)
(China,1)6. What is the difference between RDD persist() and cache() methods?
The persistence and caching mechanisms are the optimization techniques. It may be used for Interactive as well as Iterative computation. Iterative means to reuse the results over multiple computations. Interactive means allowing a two-way flow of information. These mechanisms help us to save the results so that upcoming stages can use them. We can save the RDDs either in Memory(most preferred) or on Disk((less Preferred because of its slow access speed).
Persist():- We know that RDDs are re-computable on each action due to their default behavior. To avoid the re-computation, we can persist with the RDDs. Now, whenever we call an action on RDD, no-re-computation takes place.
In persist() method, computations results get stored in its partitions. The persistent method will store the data in JVM when working with Java and Scala. While in python, when we call persist method, the serialization of the data takes place. We can store the data either in memory or on the disk. A combination of both is also possible.
Storage levels of Persisted RDDs:-
1. MEMORY_ONLY(DEFAULT LEVEL)
2. MEMORY_AND_DISK
3. MEMORY_ONLY_SER
4. MEMORY_ONLY_DISK_SER
5. DISC_ONLY
Cache():- It is the same as the persist method; the only difference is cache stores the computations result in the default storage level i.e. Memory. Persist will work the same as a cache when the storage level is set to MEMORY_ONLY.
Syntax to un-persist the RDDs:-
RDD.unpersist( )
7. What is Spark Core?
Spark Core is the foundational unit of all spark applications. It performs the following functionalities: memory management, fault recovery, scheduling, distributing & monitoring jobs, and interaction with storage systems. Spark Core can be accessed through an application programming interface (APIs) built in Java, Scala, Python, and R. It contains APIs that help to define and manipulate the RDDs. This APIs help to hide the complexity of distributed processing behind simple, high-level operators. It provides basic connectivity with different data sources, like AWS S3, HDFS, HBase, etc.
8. What is RDD Lineage?
RDD Lineage (RDD operator graph or RDD dependency graph) is a graph that contains all the parent RDDs of an RDD.
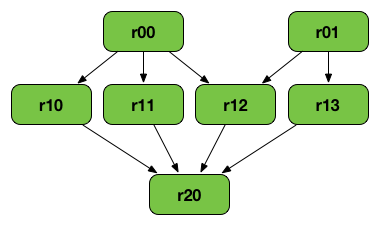
The following transformations can generate the above graph:-
val r00 = sc.parallelize(0 to 9) val r01 = sc.parallelize(0 to 90 by 10) val r10 = r00.cartesian(r01) val r11 = r00.map(n => (n, n)) val r12 = r00.zip(r01) val r13 = r01.keyBy(_ / 20) val r20 = Seq(r11, r12, r13).foldLeft(r10)(_ union _)
1. The RDD lineage gets created when we apply different types of transformations to an RDD, creating a so-called Logical Execution Plan.
2. The lineage graph contains information on all the transformations that need to be applied when action gets called.
3. A logical execution plan starts with the earliest RDD and finishes with the RDD, producing the final result on which action has been called.
9. What is the difference between RDD and DataFrame?
DataFrame:-
A data frame stores the data in tabular format. It is a distributed collection of data in rows and columns. The columns can store data types like numeric, logical, factor, or character. It makes the processing of larger datasets easier. Developers can impose a structure onto a distributed collection of data with the help of a data frame. It also provides a high-level abstraction over the distributed data.
RDD:-
RDD(Resilient Distributed Dataset) is a collection of elements distributed across multiple cluster nodes. RDDs are immutable and fault tolerant. RDDs, once created, can’t get changed, but we can perform several transformations to generate new RDDs from them.
10. Explain Accumulator shared variables in Spark?
Accumulators are read-only shared variables. They are only “added” through an associative and commutative operation. They can be used to implement counters (as in MapReduce) or sums. Spark natively supports accumulators of numeric types, and you can also add support for new types.
Accumulators are incremental variables. The tasks running on nodes can add to it while the driver program can read the value. Tasks running on different machines can increment their value, and this aggregated information is available back to the driver.
Frequently Asked Questions
A. To prepare for an Apache Spark interview, follow these steps:
1. Understand Spark’s architecture, components, and RDDs.
2. Master Spark transformations and actions.
3. Practice writing Spark code in languages like Scala or Python.
4. Learn about Spark SQL, data frames, and data manipulation techniques.
5. Gain hands-on experience with Spark by working on projects or exercises.
6. Study optimization techniques and performance tuning in Spark.
7. Stay updated with the latest advancements and trends in Spark technology.
A. To optimize performance in Apache Spark, you can consider the following techniques:
1. Use efficient data structures like DataFrames and Datasets.
2. Employ partitioning and caching to reduce data shuffling and improve data locality.
3. Utilize broadcast variables for small data sets.
4. Optimize the Spark execution plan by applying transformations and actions strategically.
5. Use appropriate hardware configurations and resource allocation.
6. Monitor and tune Spark configurations based on your workload.
Conclusion
In this article, we have discussed the most important and frequently asked interview questions on Apache Spark. We started our discussion with fundamental questions like what a spark is, RDD, Dataset, and DataFrame. Then, we move towards intermediate and advanced topics like a broadcast variable, cache and persist method in spark, accumulators, and pair RDDs. We have a different variety of questions related to spark.
Key takeaways from this article are:-
- 1. We learn the difference between the most used terms in Apache Spark, i.e., RDD, DAG, DataFrame, Dataset, etc.
- 2. We understood Structured APIs and how they are used to perform different operations on data.
- 3. We also learn about pair RDD, lineage, broadcast variables, and accumulators.
- 4. Other learnings are sparkcontext v/s sparksession, RDD v/s DataFrame, and Spark core.
I hope this article helps you in your interview preparation relating to Apache Spark. If you have any opinions or questions, then comment down below. Connect with me on LinkedIn for further discussion.
Keep Learning!!!
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.