

{kind=link}
Introduction
Read this article on machine learning model deployment using serverless deployment. Serverless compute abstracts away provisioning, managing
severs and configuring software, simplifying model deployment.
Aimed towards becoming a Full Stack Data Scientist.
What is a serverless deployment?
Serverless is the next step in Cloud Computing. This means that servers are simply hidden from the picture. In serverless computing, this separation of server and application is managed by using a platform. The responsibility of the platform or serverless provider is to manage all the needs and configurations for your application. These platforms manage the configuration of your server behind the scenes. This is how in serverless computing, one can simply focus on the application or code itself being built or deployed.
Machine Learning Model Deployment is not exactly the same as software development. In ML models a constant stream of new data is needed to keep models working well. Models need to adjust in the real world because of various reasons like adding new categories, new levels, and many other reasons. Deploying models is just the beginning, as many times models need to retrain and check their performance. So, using serverless deployment can save time and effort and for retraining models every time, which is cool!
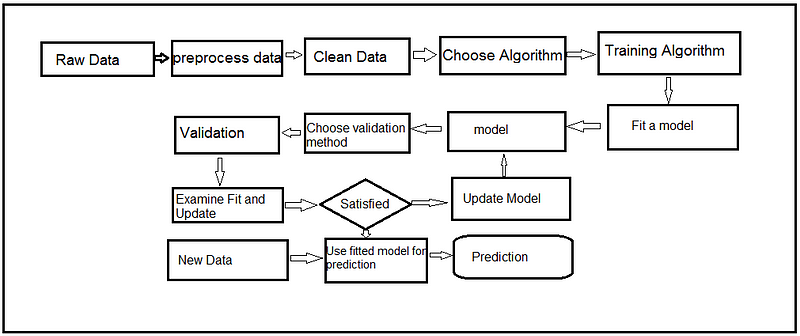
Fig: ML Workflow
Models are performing worse in production than in development, and the solution needs to be sought in deployment. So, it’s easy to deploy ML models through serverless deployment.
Prerequisites to understand serverless deployment
- Basic understanding of cloud computing
- Basic understanding of cloud functions
- Machine Learning
Serverless Deployment Models for prediction
We can deploy our ML model in 3 ways:
- web hosting frameworks like Flask and Django, etc.
- Serverless compute AWS lambda, Google Cloud Functions, Azure Functions
- Cloud Platform specific frameworks like AWS Sagemaker, Google AI Platform, Azure Function
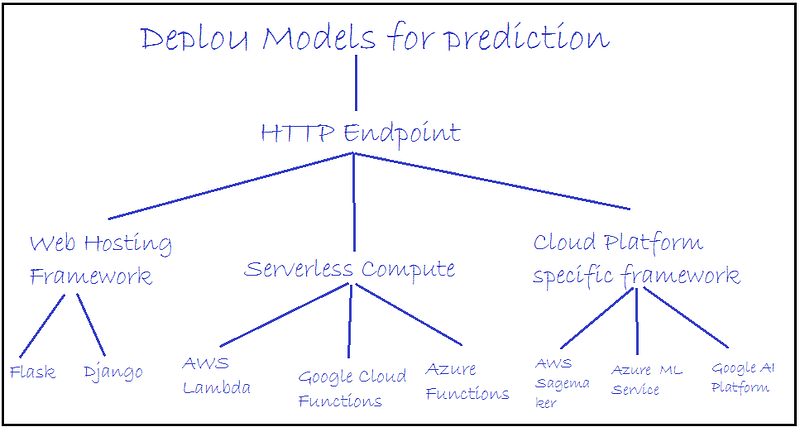
Fig: Types of ML model deployment
Serverless deployment architecture overview
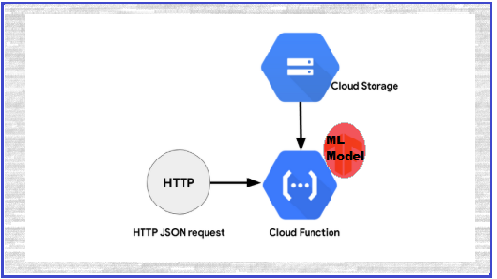
Fig: A Image is taken from google search and modified
Store models in Google Cloud Storage buckets then write Google Cloud Functions. Using Python for retrieving models from the bucket and by using HTTP JSON requests we can get predicted values for the given inputs with the help of Google Cloud Function.
Steps to start serverless model deployment
1. About Data, code, and models
Taking the movie reviews datasets for sentiment analysis, see the solution here in my GitHub repository and data, models also available in the same repository.
2. Create a storage bucket
By executing the “ServerlessDeployment.ipynb“ file you will get 3 ML models: Decision Classifier, LinearSVC, and Logistic Regression.
Click on the Browser in Storage option for creating a new bucket as shown in the image:
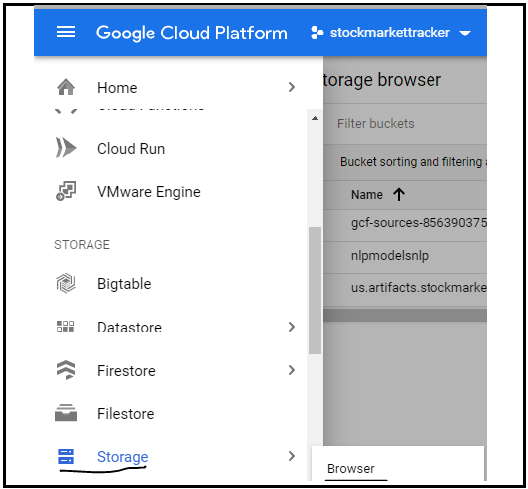
Fig: click Store option from GCP
3. Create a new function
Create a new bucket, then create a folder and upload the 3 models in that folder by creating 3 subfolders as shown.
Here models are my main folder name and my subfolders are:
- decision_tree_model
- linear_svc_model
- logistic_regression_model
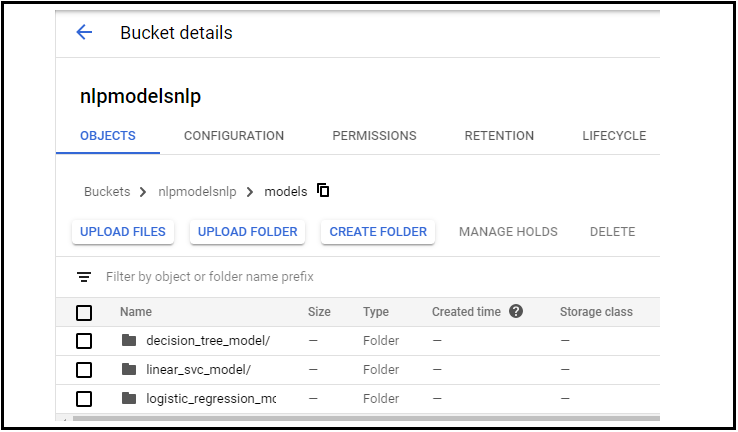
Fig: Folders at Storage
4. Create a function
Then go to Google Cloud Functions and create a function, then select trigger type as HTTP and select language as Python (you can choose any language):
Fig: Select Cloud Function option from GCP
5. Write cloud function in the editor
Check the cloud function in my repository, here I have imported required libraries for calling models from google cloud bucket and other libraries for HTTP request GET method used to test the URL response and POST method delete default template and paste our code then pickel is used for deserialized our model google.cloud — access our cloud storage function.
If the incoming request is GET we simply return “welcome to classifier”.
If the incoming request is POST access the JSON data in the body request get JSON gives us to instantiate the storage client object and access models from the bucket, here we have 3 — classification models in the bucket.
If the user specifies “Decision Classifier” we access the model from the respective folder respectively with other models.
If the user does not specify any model, the default model is the Logistic Regression model.
The blob variable contains a reference to the model.pkl file for the correct model.
We download the .pkl file on to the local machine where this cloud function is running. Now every invocation might be running on a different VM and we only access /temp folder on the VM that’s why we save our model.pkl file.
We desterilize the model by invoking pkl.load access the prediction instances from the incoming request and call model.predict on the prediction data.
The response that will send back from the serverless function is the original text that is the review that we want to classify and our pred class.
After main.py write requirement.txt with required libraries and versions
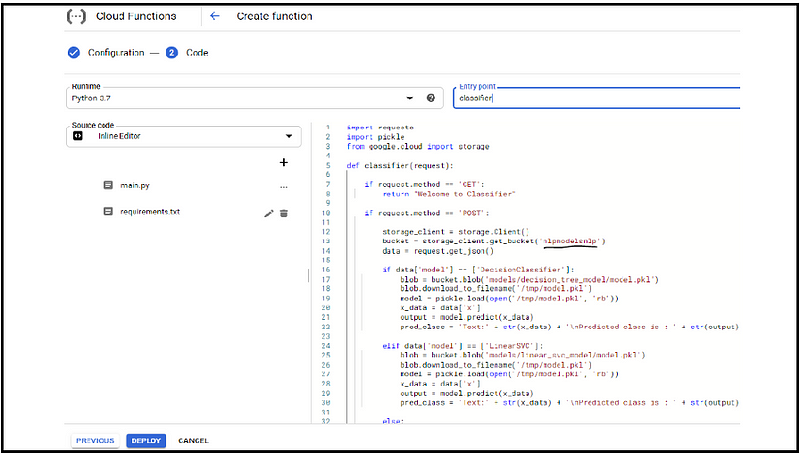
Fig : Google Cloud Function(find detailed code in my github page)
5. Deploy the model

Fig : Green tick represent successful model deployment
6. Test the model
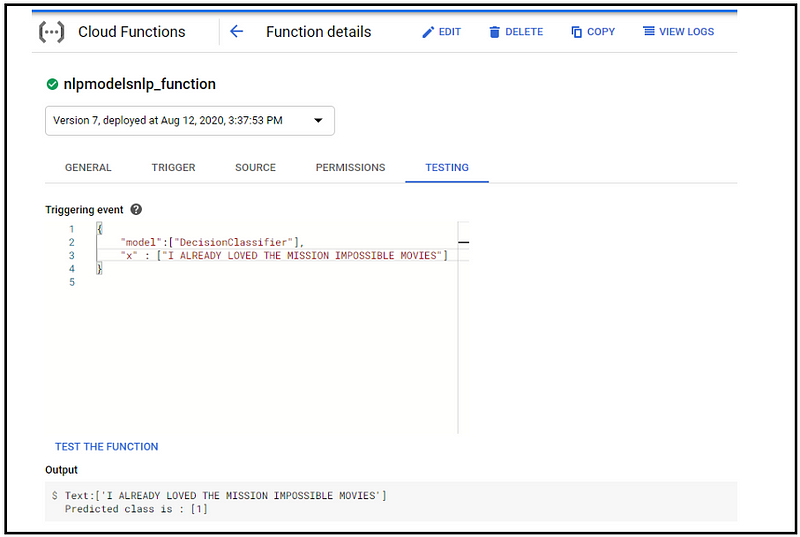
Fig : Give model name and review(s) for testing
Test function with other model
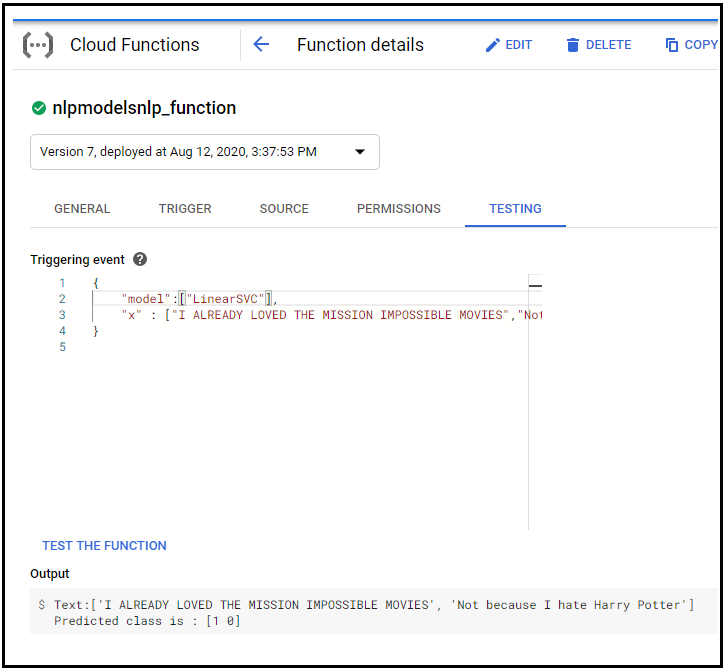
Fig : Test the model
Code References:
My GitHub Repository : https://github.com/Asha-ai/ServerlessDeployment
Become a Full Stack Data Scientist by learning various ML Model deployments and reason behind this much explanation at initial days I struggle a lot for learning ML Model deployment, So I decided my blog should useful to data science freshers end to end
will meet you with my next blog : Deploy ML Model using “Web Hosting Framework – Flask“