

{kind=link}
One of the most common operation for any analyst is merging datasets. As per my estimate, an analyst spends at least 10 – 20% of his productive time joining and merging datasets. If you spend so much time doing joins / merges, it is extremely critical that you join datasets in most efficient manner. This is the thought behind this post.
Traditionally, databases have been designed in a manner where tables capture details of individual functional area.
Example below shows two tables, one capturing patient details in a clinic (from one time registrations) and second table showing their appointment details.
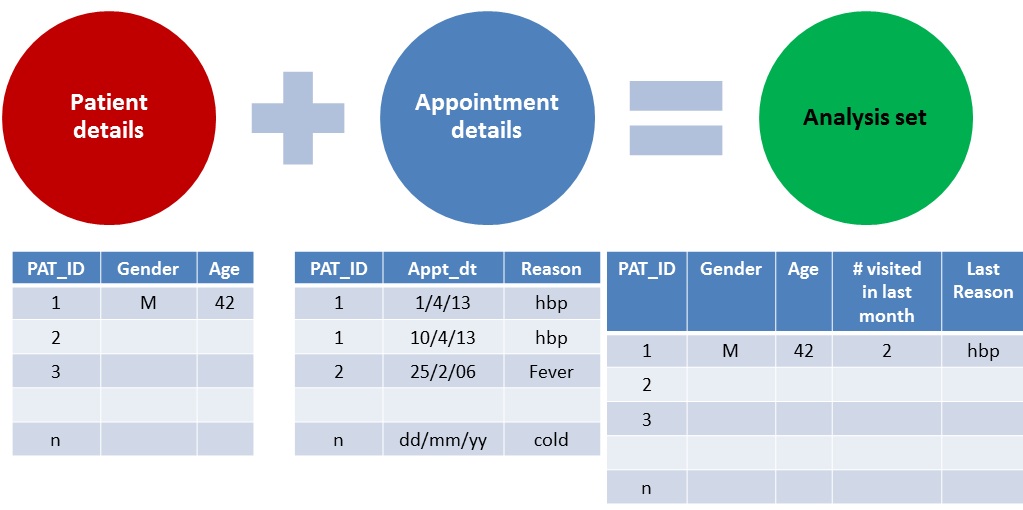
Example of data join
In order to analyze things like:
- Which customer has walked in how many times in last month?
- Which kind of customers have walked in more last month?
- What are the common reasons for people walking in?
we need to join the two tables.
I’ll cover various ways in which you can do this in SAS:
[stextbox id=”section”]1. Sort / sort / Merge:[/stextbox]
This is the most common approach used in SAS. In order to use data step command, we need to sort the datasets first and then merge using the common key:
[stextbox id=”grey”]
proc sort data=patient_details; by pat_id;
proc sort data=appointment_details; by pat_id;
data analysis_set;
merge patient_details (in=a) appointment_details (in=b);
by pat_id;
/* note by variables are in the same order as sort by */
if a and b; /* Control statement, other options: if a; if b; if not a; if not b;*/
[/stextbox]The control statement defines the kind of merge. By specifying “if a and b”, values present in both the tables will be picked.
[stextbox id=”section”]2. PROC SQL:[/stextbox]
If you are used to writing SQL, PROC SQL might be the easiest way to learn joins in SAS
[stextbox id=”grey”]
PROC SQL;
CREATE TABLE analysis_set0 AS
SELECT a.*, b.*
FROM patient_details a
INNER JOIN /* control statement*/
/*other options LEFT JOIN, RIGHT JOIN, OUTER JOIN*/
appointment_details b
ON a.pat_id=b.pat_id;
QUIT;
RUN;
[/stextbox]
[stextbox id=”section”]3. PROC FORMAT:[/stextbox]
This is one of the latest ways I have learnt, but the most efficient one. Using this method, we convert the smaller file into a format.
[stextbox id=”grey”]
DATA format1;
SET patient_details (keep = PAT_ID);
fmtname = '$pat_format';
label = '*';
RENAME pat_id=start;
RUN;
PROC SORT data=format1 nodupkey; by pat_id; RUN;
PROC FORMAT CNTLIN=format1; RUN;
[/stextbox]
The first step creates a dataset format1 from patient_details. PROC FORMAT then converts it into a format. Finally we use
[stextbox id=”grey”]
DATA analysis_set;
SET appointment_details;
if PUT(pat_id,$pat_format.) = '*';
RUN;
[/stextbox]
This way to join datasets typically takes 30 – 40% lower computation time compared to the two approaches mentioned above.
Since this might look advanced SAS, I will devote one more post explaining formats in more details.
In the meanwhile, if you know of any other way to join tables, please let me know.
If you like what you just read & want to continue your analytics learning, subscribe to our emails or like our facebook page
Kunal is a post graduate from IIT Bombay in Aerospace Engineering. He has spent more than 10 years in field of Data Science. His work experience ranges from mature markets like UK to a developing market like India. During this period he has lead teams of various sizes and has worked on various tools like SAS, SPSS, Qlikview, R, Python and Matlab.