



{kind=link}
This article was published as a part of the Data Science Blogathon.
Introduction
In this article, we will introduce you to the big data ecosystem and the role of Apache Spark in Big data. We will also cover the Distributed database system, the backbone of big data.

In today’s world, data is the fuel. Almost every electronic device collects data that is used for business purposes. Imagine how we work on a big volume of data. Of course, we need powerful computers to work on this amount of data, but it’s unpractical.
Processing petabytes of data is impractical for a single computer; hence big data technologies come into the picture.
Big data is the domain where we deal with many data using different big data tools and cloud systems.
Processing Big Data
Big data processing requires parallel computation since loading petabytes of data in a single or a very high-end computer is impossible. This technique of using parallel computation is known as distributed computing.
A single computer in a distributed system is known as a node, and each node uses its computing resources.
A master node is responsible for dividing the word load among various nodes, and if a work node fails, it stops delivering the load to the failed node.
A cluster is a collection of nodes, including the master node that words in synchronization.
Big Data EcoSystem:
Many open-source tools comprise the big data ecosystem. Open-source tools are generally used in Big data because these tools are more transparent and free to use, so there is no need to worry about the data leaking.
Popular big data open source tools are Apache Spark, Hadoop, Map-Reduce, Hive, Impala, etc.
Tools Category:
- Programming Tools
- Business Intelligence tools
- Analytics and visualization
- Databases (NoSql and SQL )
- Cloud Technologies
- Data Technologies
Hadoop Ecosystem:
Hadoop Ecosystem consists of various open-source tools that fall under the Apache project. These tools are made for big data workloads. All the components work dependently in the Hadoop ecosystem.
- Ingest Data( Flume , Sqoop)
- Access Data ( Impala, Hue)
- Process and Analyze Data (Pig & Hive, Spark)
- Store Data (HDFS, HBase)
What is Apache Spark?
Spark is a distributed in-memory data processing tool. Spark is a replacement for Apache Map-Reduce.
Spark is a powerful replacement for Apache Map-Reduce. Spark is faster than Map reduce because of in-memory computation, making it highly capable and always up for a high volume of data processing.
In-memory computation takes the help of an individual system ram for computation instead of the disk, which makes spark powerful.
Top Features of Apache Spark:
- Fast Processing
We have already discussed the impact of using in-memory computation on big data processing. Due to its computation power, Spark has been the only choice for big data processing. - Supports various APIs
Spark supports JAVA, PYTHON, and SCALA programming languages. Spark was written on Scala, and it supports other programming language APIs.
Spark core handles jobs using SCALA.
Spark Core is fault-tolerant, so if any node goes down, processing will not stop. - PowerFul Libraries
Spark Supports Various 3rd party libraries as well. Spark comes with a wide range of libraries for specific tasks.
ML-lib in the spark is natively built for machine learning tasks. It also supports streaming machine learning pipelines. - Compatibility and Deployment
The biggest advantage of using Spark is that it doesn’t require huge tedious dependencies. Spark can run on any cloud cluster and can be easily scaled. Spark runs on Kubernetes, Mesos, Hadoop, and other cloud notebooks. - Real-Time Processing
Spark also supports the conventional Hadoop Map-Reduce, which leads Spark to process data from HDFS file format. Spark can easily work on the HDFS cluster without any dependency conflicts.
Apache Spark Architecture
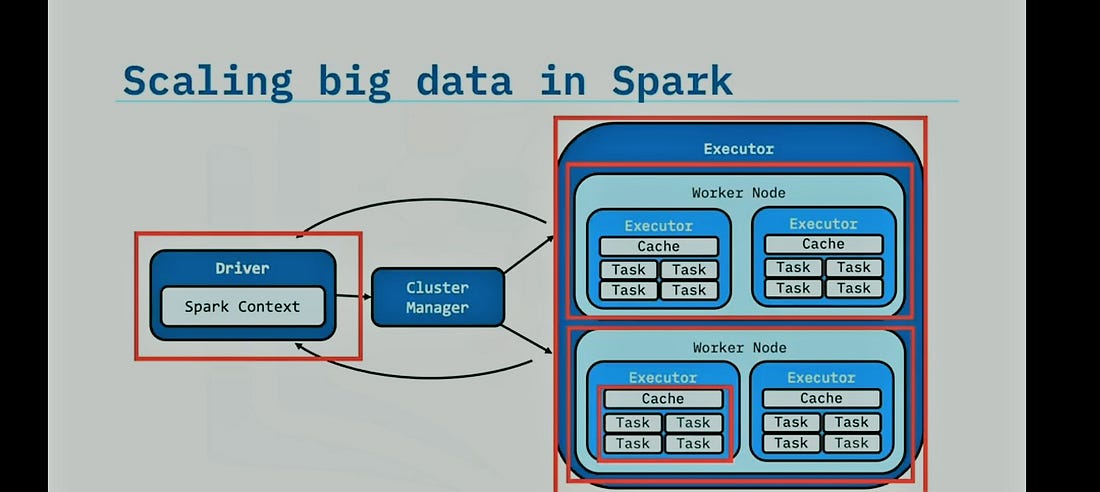
Apache Spark Core engine consists of 3 components
- Spark Driver
- Executors
- Cluster Manager
Spark Driver is responsible for spark context (code we write). It translates the spark context and sends the information to the cluster manager, which creates clusters, and the executor handles worker nodes and assigns tasks to them.
Getting Started with Spark with Python
Spark applications can be written in Python. Python uses py4j in the backend to handle the java codes.
Objectives
- Setting Up Pyspark
- Creating Context and Session
- Spark RDD
- Transformation and actions
Setting Up Pyspark
Pyspark in spark API built for python. It lets us create a spark application in Python. It uses py4j in the backend.
Spark can be run natively on any python environment. We can also build spark clusters on cloud notebooks. Popular python environment for running spark in data bricks, providing some databases to work on.
Here is a guide on running spark clusters on data bricks for free.
Installing required packages.
For Running spark in python, we need pyspark module and findspark.
!pip install pyspark !pip install findspark
Findspark It generates startup files to the current Python profile and prepares the spark environment. Find spark locates the spark startup files.
import findspark findspark.init()
Spark Session and Context
Spark session Spark Session keeps track of our application. Spark Session must be created before working on spark and loading the data.
SparkContext Spark context is an entry point to the spark application, and it also concludes some RDD functions likeparallelize().
# Initialization spark context class
sc = SparkContext()
# Create spark session
spark = SparkSession
.builder
.appName("Application name ")
.config("spark.some.config.option", "somevalue")
.getOrCreate()
getOrCreate Creates a new session if the named session doesn’t exist.
spark

Spark RDDs
Spark RDD ( Resilient distributed datasets) are fundamental data structures on a spark, which is an immutable distributed object.RDDs are super fast, and the Core Engine of Spark supports RDDs.
RDDs in Spark can only be created by parallelizing or referencing the other datasets.
RDDS works in a distributed fashion, meaning the dataset in RDD is divided into logical partitions, computed by different assigned nodes by cluster. Spark RDDs are fault tolerant; in spark, other datasets are based on RDDs.
RDD accepts the following types of datatypes —
- Parquet, Text, Hadoop inputs, Avro, Sequence Files, etc.
- Amazon S3, Cassandra, HBase, HDFS, etc.
In RDD, data is distributed across multiple nodes, making it work in a distributed manner.
RDD supports lazy evaluation, which means it doesn’t compute anything until the value is required.
sc.parallelizeIt transforms a series into an RDD.
Series to RDD transformation.
data = range(1,30) # print first element of iterator print(data[0]) len(data) xRDD = sc.parallelize(data, 5)
RDD Transformations
Transformations are the rules that must be followed for the computation.RDDs are lazy evaluations that indicate that no calculations will be performed until the actions are called.
This transformation will be stored as a set of rules and implemented at the action stage.
# Reduces each number by 2 sRDD = xrangeRDD.map(lambda x: x-2)
# selects all number less than 20 filteredRDD = sRDD.filter(lambda x : x<20)
RDD Actions
Actions are the actual computation process. after applying the transformation, we need to call actions whenever we need the values. It helps in data integrity.
print(filteredRDD.collect())
filteredRDD.count()
Output:

Conclusion
In this article, we talked about the ecosystem of Big Data and the various types of tools the Big data Ecosystem is made up of.
We talked about the role of distributed systems and how Spark works in Big data.
Spark Architecture contains a driver node, context reader, and node manager. Spark works in a distributed manner, the same as Hadoop, but alike Hadoop, it uses In-memory computation instead of disk.
We discussed RDD and Transformations and actions.
- Spark RDDs can’t be modified only can be replaced.
- Spark RDDs are lazy evaluated, which helps in data integrity and doesn’t let data corrupt.
- Spark Supports distributed SQL that is built on top of RDDs
- Spark Supports various machine learning models, including CNN as well as NLPs.
Thanks for reading this article
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.