{kind=link}
How to Handle Failures in Distributed Systems
In a distributed system, failures aren’t a possibility—they’re a certainty.
Your database might go down. A service might become unresponsive. A network call might time out. The question is not if these things will happen—but when.
As engineers, our job is to design systems that embrace this reality and gracefully handle failures.
In this article, we’ll cover:
-
Types of failures in distributed systems
-
12 best strategies for handling failures
Types of Failures in Distributed Systems
Distributed systems involve multiple independent components communicating over a network.
And each of these introduces potential failure points:
1. Network Failures
The network is the most unreliable component in any distributed architecture.
-
Packets get dropped
-
Connections time out
-
DNS resolution fails
-
Latency spikes suddenly
-
Firewalls misbehave
Even if two services are running in the same data center, network glitches can still occur.
2. Node Failures
A single machine (or container) can go down due to:
-
Power failure
-
OS crash
-
Disk corruption
-
Out-of-memory (OOM)
-
Hardware failure
In distributed systems, every node is potentially a single point of failure unless redundancy is built in.
3. Service Failures
A service may fail even if the machine it’s running on is healthy.
Common reasons:
-
Code bugs (null pointers, unhandled exceptions)
-
Deadlocks or resource exhaustion
-
Memory leaks causing the service to slow down or crash
-
Misconfigurations (e.g., bad environment variables)
4. Dependency Failures
Most services depend on:
-
Databases
-
Caches (like Redis or Memcached)
-
External APIs (payment gateways, 3rd-party auth providers)
-
Message queues (like Kafka, RabbitMQ)
If any of these are unavailable, misbehaving, or inconsistent, it can cause cascading failures across the system.
Example: Your checkout service calls the payment API, which calls a bank API, which calls a fraud-detection microservice. Each hop is a potential point of failure.
5. Data Inconsistencies
Data replication across systems (like DB sharding, caching layers, or eventual consistency models) can introduce:
-
Out-of-sync states
-
Stale reads
-
Phantom writes
-
Lost updates due to race conditions
Example: A user updates their address, but due to replication lag, the shipping system fetches the old address and sends the package to the wrong place.
6. Configuration & Deployment Errors
Failures aren’t always caused by bugs—they’re often caused by mis-configurations and human errors:
-
Misconfigured load balancers
-
Missing secrets in the environment
-
Incompatible library updates
-
Deleting the wrong database
-
Rolling out a new version without backward compatibility
According to multiple incident postmortems (e.g., AWS, Google), a large number of production outages are triggered by bad config changes—not code.
7. Time-Related Issues (Clock Skew, Timeouts)
Distributed systems often rely on time for:
-
Cache expiration
-
Token validation
-
Event ordering
-
Retry logic
But system clocks on different machines can drift out of sync (called clock skew), which can wreak havoc.
Example:
Machine A: 12:00:01
Machine B: 11:59:59A token generated on Machine B might be considered “expired” when validated by Machine A, even if it was just created.
12 Best Strategies for Handling Failures
Let’s look at the 12 best strategies that make your system resilient when parts of it inevitably fail.
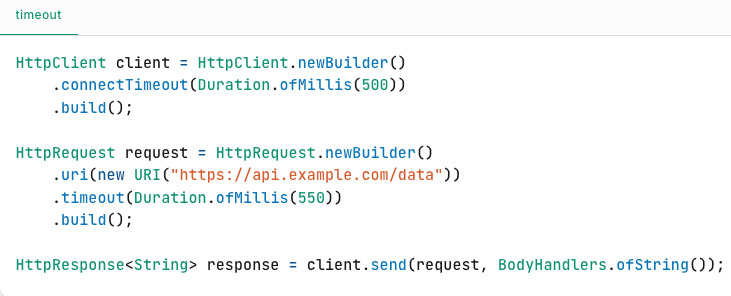
1. Set Timeouts for Remote Calls
A timeout is the maximum time you’re willing to wait for a response from another service. If a service doesn’t respond in that time window, you abort the operation and handle it as a failure.
Every network call whether it’s to a REST API, database, message queue, or third-party service should have a timeout.
Why?
Waiting too long can hog threads, pile up requests, and cause cascading failures. It’s better to fail fast and try again (smartly).
Timeout Best Practices
To be effective, timeouts should be:
-
Short enough to fail fast
-
Long enough for the request to realistically complete
-
Vary depending on the operation (e.g., reads vs writes, internal vs external calls)
A good practice is to base timeouts on the service’s typical latency (e.g., use the 99th percentile response time or service SLO, plus a safety margin).
Example:
If your downstream service has a p99 latency of 450ms:
Recommended Timeout = 450ms + 50ms buffer = 500msThis ensures most successful responses arrive before the timeout, while truly slow or hung requests get aborted.
What to Avoid:
-
Never use infinite or unbounded timeouts
-
Don’t assume the caller will enforce a timeout for you
Code Example