

{kind=link}
This article was published as a part of the Data Science Blogathon.
Introduction
Search engines make use of keywords for search optimization. It is the best way to help users get the most out of their search. Bloggers and content writers use keywords to target their audience.
Keyword extraction is important because it gives you the most dominant keywords in a text or article and helps marketers get in front of customers that need their product or service once the keywords are used. They also push trends. Once an algorithm can determine which words keep showing up in posts, that word becomes a trend and can be used as a hashtag.

In this article, we will extract keywords from a popular news API. First, we get the news, get the content or headline, put it in a tabular format, and analyze it using natural language processing (NLP) to determine the most popular keywords that make the news.
Getting Started
We will start by collecting the news with News API. News API is a simple HTTP Rest API for searching and retrieving live articles over the web. You give the search parameter a niche or list of niches, and you can get news about it from a list of sites or one site — if you indicate the domain you want the news from.
News API also requires an API key; you can only get this by signing up. It doesn’t take much to sign up from the website newsapi.org. So sign up and check your profile for your key.
To start, install newsapi and import it.
pip install newsapi-python from newsapi.newsapi_client import NewsApiClient
News API has three endpoints — everything and top headlines, each with different parameters. You can get this from the documentation on the website. We’ll use all endpoint parameters, including q, language, page size, domain sources, category, etc.
q is the most important parameter. It is the keyword or phrase to search for in the title or body of the news. If you need business news, q = ‘business.’ If you need technology news, q = ‘tech’.
Each news extracted has a source, title, description, URL, urltoImage, published, and content. Our code did not specify a domain_source so news can be gotten from any source.
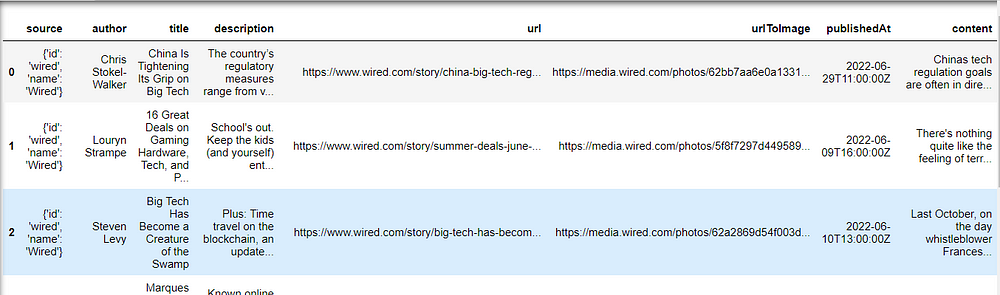
We only want to extract keywords from the title. We are interested in knowing which keywords are used frequently in tech news. The title column needs to be converted to a string for further processing with NLP.
#The column we need is the title. we will highlight it.
col = df[‘title’] text = col.to_string(index = False) #index = false removes the row number print(text)
Output:
Tech Resources That Help Kids Navigate Puberty What Twitter’s Move to Shutter Offices Signals ... Apple's iPad drops to $299, plus the rest of th... 'Under the Waves' leverages Quantic Dream's tec... Google's Pixel Buds Pro drop to $175, plus the ... The Senate gets one precious step closer to app...
Natural Language Processing with NLTK
Natural language Processing (NLP) is a subgenre of computer linguistics concerned with computers’ interactions with human language. A computer or program can hear, read, and interpret a text with NLP.
NLTK (The Natural Language Toolkit) is the most common suite of libraries used for statistical and symbolic language processing. It comes with many trained models, corpora, and has packages like tokenization, lemmatization, stopwords, and stemming, which helps machines process words.
To install NLTK for mac and Linux users:
pip install — user -U nltk
For Windows users:
pip install nltk
nltk.download()
When nltk.download() is run, a new window is opened showing the NLTK downloader. Finish the download and install all listed packages.
Then import it
import nltk
NLTK performs language tasks like tokenization. Tokenization is when a program attempts to split into individual units the words or phrases given to it. These individual units of a sentence are called tokens.
We must import the word_tokenize function from the nltk_tokenize class to tokenize a sentence. We have the text we need in a variable called text — the title column converted to a string.
from nltk.tokenize import word_tokenize
#we already have our text in the text variable. We just proceed to tokenize it
word_token = word_tokenize(text) print(word_token)

It displays as a list of single words.
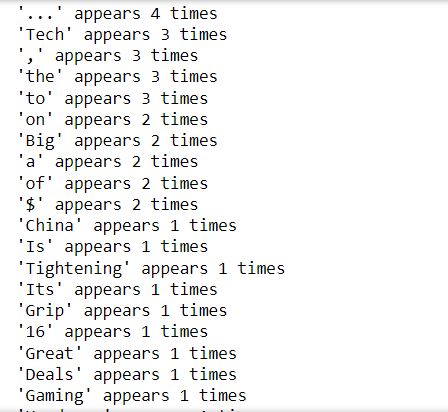
NLTK has a function called freqdist. Freqdist gives users the frequency distribution of all words in a text. A handy skill in probability calculation. It has methods like most_common(). We can check how many times a word appears in a text like this,
#importing freqdist from nltk.probability import FreqDist
#using freqdist to get the frequency of each word
new_text = FreqDist(word_token)
for countt in new_text:
print(f”’{countt}’ appears {new_text[countt]} times”)
#to get the frequency of single word
print(new_text[‘Tech’])
To get the most common words, consider using most_common() method
# using .most_common() method to get the top 10 reoccurring words wordcount_10 = new_text.most_common(10) print(wordcount_10)
Output:
[('...', 5), ('to', 4), ("'s", 3), ('the', 3), ('$', 2), (',', 2), ('plus', 2), ('Tech', 1), ('Resources', 1), ('That', 1)]
Although we have the top 10 most common words, the answer is vague. The way keywords are analyzed using a TF/IDF definition, the more common the words in a text, the lower the score. The more frequent it appears, the higher the score.
Words like ‘The’ are common words. They are just fillers and cannot tell anything about an article. They only take up space. We will remove them with stopwords.
Stopwords are words that are commonly used but do not influence a piece of text. Invariably, they are useless to search engines. Words like ‘the’, ‘is’, ‘an’, ‘his’ etc. are examples of stopwords. Removing stopwords from a text gives us a better context of what that text is about because the program focuses on the important text.
To use stopwords, we will import the stopword collection from the nltk.collection from nltk.corpus module.
from nltk.corpus import stopwords
A quick example shows there are over 179 stopwords for the English language in the stopword collection.
# to print the number of stop words print(len(stopwords.words(‘english’)))
Output:
179
When we implement stopwords, we compare our text with the entire stopword collection. If a word in our text matches a stopword from the collection, it removes it. Only words with no matches are left.
# removing stopwords
# specify the language stop_words = (stopwords.words(‘English’))
filtered_text = []
for sw in word_token: if sw not in stop_words: filtered_text.append(sw) print(filtered_text)
![]()
Using FreqDist most_common() function on the new text
#using freqdist on the filtered text
text_content = FreqDist(filtered_text) top_10 = text_content.most_common(10) print(top_10)

Conclusion
In conclusion, here are a few things to note while extracting keywords from NewsAPI:
- A larger text will give better output of keyword frequency. Small text will have a smaller set of words to pull from.
- Removing stopwords, fillers and punctuations is important. They only take up unnecessary space, leaving out the actual words we need.
- Use as many queries as possible to target more specific niches within the tech. You can have q = ‘tech’, ‘programming’, ‘natural language’.
- Read up on NewsAPI documentation to get a more robust knowledge of the scope of the API.
You can get the full code here on my Github.
You can also reach me on Twitter @barri_samb
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.