

{kind=link}
Generative image and language models promise to change how businesses approach design, support, development, and more. This blog focuses on the infrastructure challenges for supporting workloads production deployments around foundation models, and how Ray, a leading solution for scaling ML workloads, tackles these challenges. We finish with a roadmap for improvements we’re undertaking to make things even easier.
Today, Ray is used by leading AI organizations to train large language models (LLM) at scale (e.g., by OpenAI to train ChatGPT, Cohere to train their models, EleutherAI to train GPT-J, and Alpa for multi-node training and serving). However, one of the reasons why these models are so exciting is that open-source versions can be fine-tuned and deployed to address particular problems without needing to be trained from scratch. Indeed, users in the community are increasingly asking how to use Ray to orchestrate their own generative AI workloads, building off foundation models trained by larger players.
In the table below, we highlight common “production-scale” needs (which typically span from 1-100 nodes) in green. This includes questions such as:
- How do I scale batch inference to terabytes of unstructured data?
- How do I create a fine-tuning service that can spin up new jobs on demand?
- How do I deploy a model that spans multiple GPUs on multiple nodes?
In this blog post, we will focus primarily on these green-highlighted workloads.
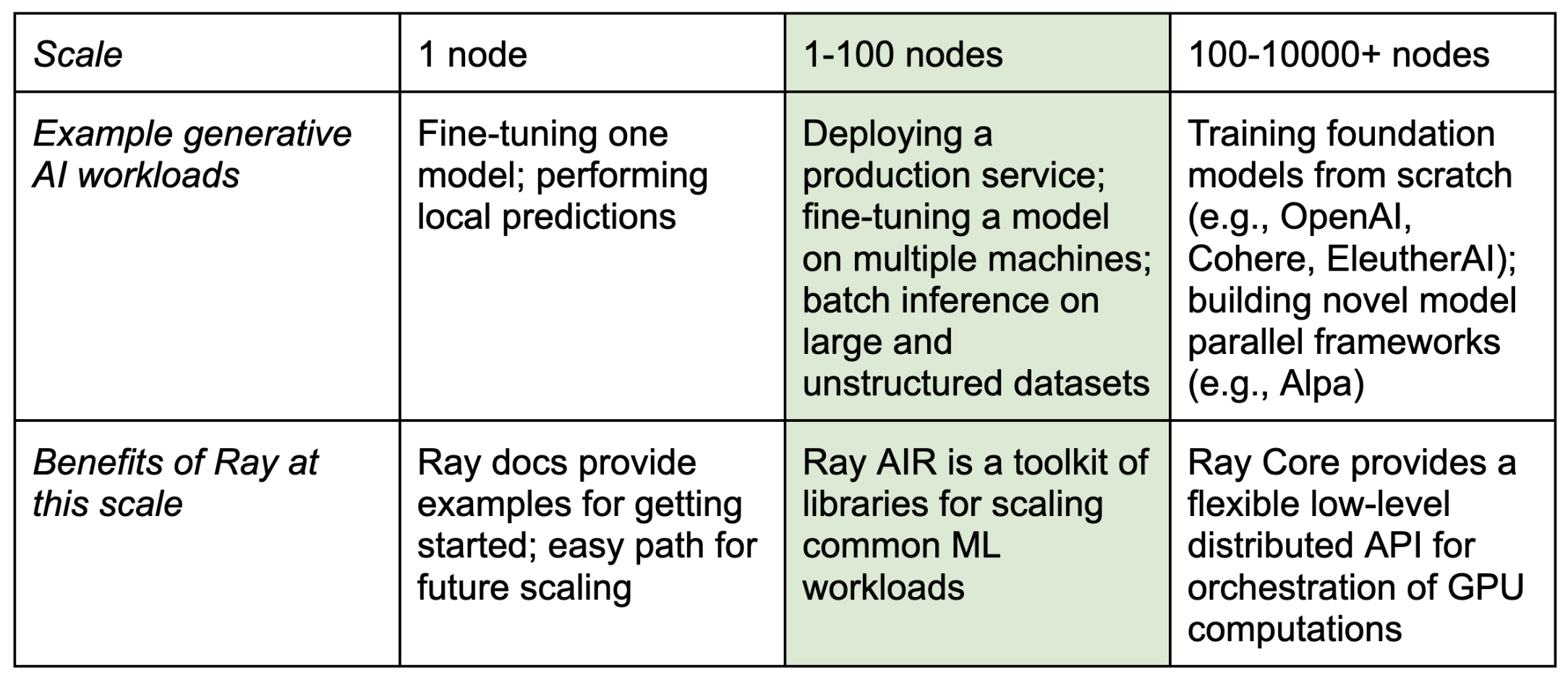
Different scale workloads for generative AI.
If you are interested in taking a look at the code examples of using Ray for generative AI workloads, check out our examples page.
Generative models: the latest evolution of ML workloads
Fig. Based on the latest deep learning models, the compute requirements of generative AI mirror those of traditional ML platforms, only greater.
We think of generative model workloads as magnifying the inherent computational challenges behind ML workloads. This comes along two axes:
- Cost: Generative models are larger and more computationally expensive to train and serve. For example, an XGBoost / scikit-learn model may take 1-10ms per record, while the most basic inference on these generative models will take 1000ms or more— a factor of >100x. This change in cost makes going distributed a default requirement for companies that want to use generative models in production.
- Complexity: In part because of cost, new computational requirements such as model parallel serving or incremental status updates (i.e., reporting partial results) emerge from use cases such as text generation and image diffusion.
Let’s also break down this trend more specifically by workload. The following table summarizes common AI workloads, and how infrastructure requirements have evolved over time for these different use cases:
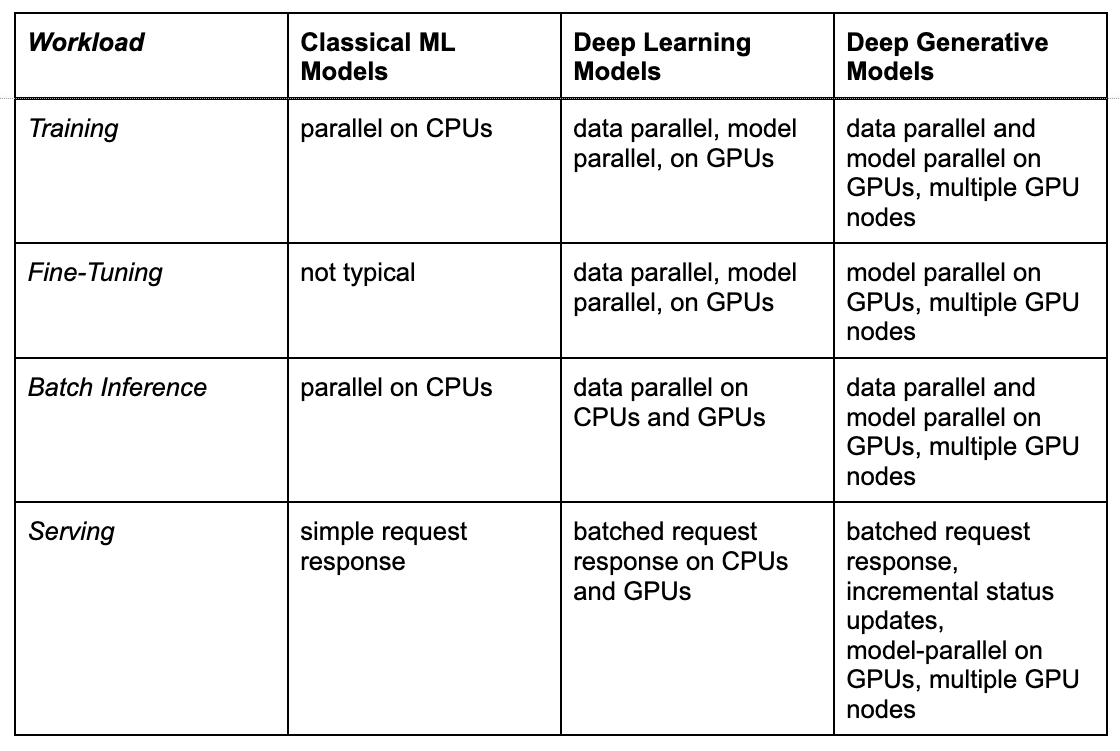
As the table shows, the cost and complexity of these workloads have grown over time— and this is in spite of the rapid improvements in GPU hardware in the industry. Let’s dive next into the challenges practitioners may face with using generative AI for these workloads.
Challenges in Generative AI Infrastructure
Generative AI infrastructure presents new challenges for distributed training, online serving, and offline inference workloads.
Distributed training
Some of the largest scale generative model training is being done on Ray today:
- OpenAI uses Ray to coordinate the training of ChatGPT and other models.
- The Alpa project uses Ray to coordinate the training and serving of data, model, and pipeline-parallel computations with JAX as the underlying framework.
- Cohere and EleutherAI use Ray to train their large language models at scale along with PyTorch and JAX.
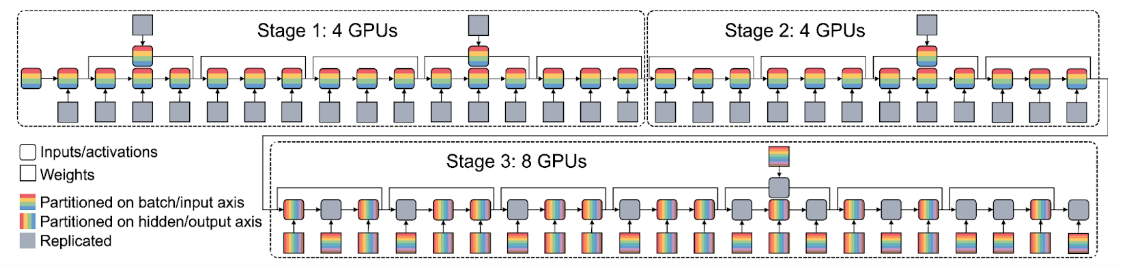
Fig. Alpa uses Ray as the underlying substrate to schedule GPUs for distributed training of large models, including generative AI models.
Common challenges for distributed training for generative models include:
- How to effectively partition the model across multiple accelerators?
- How to setup your training to be tolerant of failures on preemptible instances?
In an upcoming blog, we will cover how projects are leveraging Ray to solve challenges for distributed training.
Online serving and fine-tuning
We are also seeing a growing interest in using Ray for generative AI workloads at medium scales (e.g., 1-100 nodes). Typically, users at this scale are interested in using Ray to scale out existing training or inference workloads they can already run on one node (e.g., using DeepSpeed, Accelerate, or a variety of other common single-node frameworks). In other words, they want to run many copies of a workload for purposes of deploying an online inference, fine-tuning, or training service.
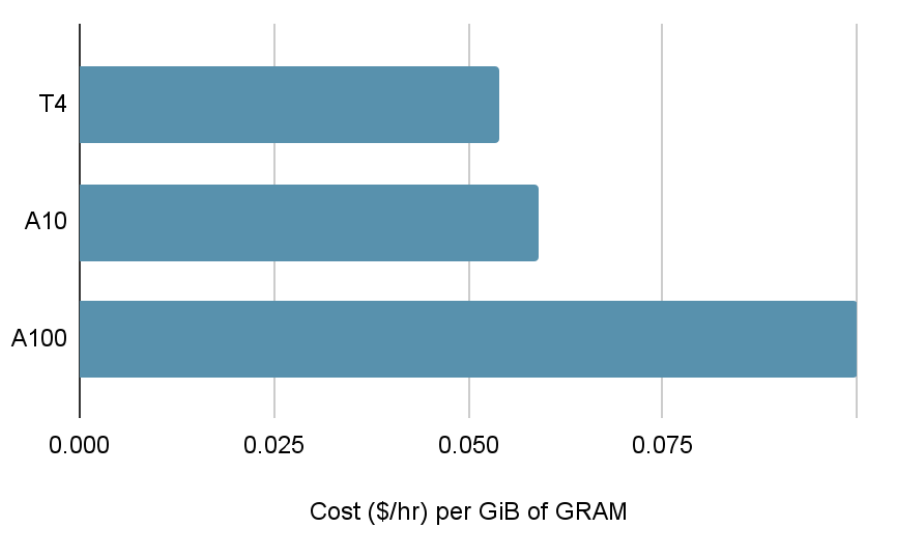
Fig. A100 GPUs, while providing much more GRAM per GPU, cost much more per gigabyte of GPU memory than A10 or T4 GPUs. Multi-node Ray clusters can hence serve generative workloads at a significantly lower cost when GRAM is the bottleneck.
Doing this form of scale-out itself can be incredibly tricky to get right and costly to implement. For example, consider the task of scaling a fine-tuning or online inference service for multi-node language models. There are many details to get right, such as optimizing data movement, fault tolerance, and autoscaling of model replicas. Frameworks such as DeepSpeed and Accelerate handle the sharding of model operators, but not the execution of higher-level applications invoking these models.
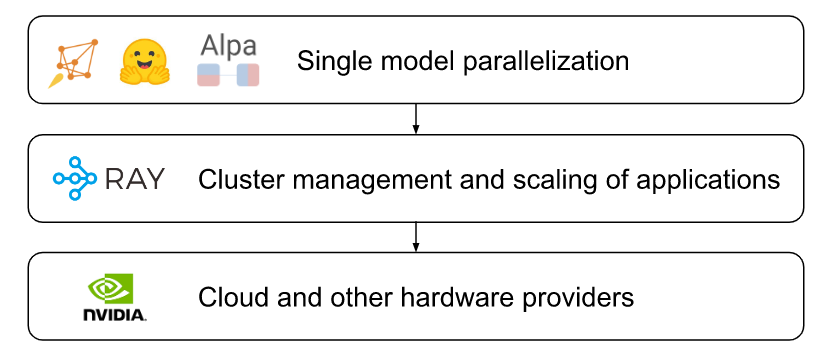
Fig. Layered stack diagram for deployments of generative model workloads.
Even for single-node workloads, users can often benefit from distribution as it is much cheaper to deploy a small cluster of GPUs than a single high-end device (e.g., A100 GPU) for hosting models. This is because lower-end GPUs typically cost less per gigabyte of memory. However, it is challenging to scale deployments involving many machines. It is also difficult to drive high utilization out of the box without libraries such as Ray Serve and Ray Data.
Offline batch inference
On the offline side, batch inference for these models also has challenges in requiring data-intensive preprocessing followed by GPU-intensive model evaluation. Companies like Meta and Google build custom services (DPP, tf.data service) to perform this at scale in heterogeneous CPU/GPU clusters. While in the past such services were the rarity, we are more and more often seeing users ask how to do this in the context of generative AI inference. These users must now tackle the distributed systems challenges of scheduling, observability, and fault tolerance.
How Ray addresses these challenges
Existing Ray Features
Ray Core scheduling: To orchestrate the large-scale distributed computations required for training generative models from scratch, Ray Core has flexible support for scheduling tasks and actors on CPUs and GPUs. This capability is especially useful for those using Ray for large-scale model training. Placement groups enable users to reserve groups of GPU or CPU resources to place replicas of large models for multi-node fine-tuning, inference, or training.
Ray Train: Ray’s Train library provides out-of-the-box Trainer classes that can run popular frameworks such as distributed TensorFlow, Torch, XGBoost, Horovod, and more. To make it easier to get started with generative models, we are adding integrations with popular frameworks such as HuggingFace Accelerate, DeepSpeed, and Alpa to Train, as well as RLHF support.
Ray Serve: Ray Serve provides a first-class API for scaling model deployment graphs. Because Serve runs within Ray, it also has a great degree of flexibility in running ad-hoc or auxiliary computations. For example, users have launched Ray sub-tasks from Serve to fine-tune models, and coordinated the return of incremental results through named actors also running in Ray.
Upcoming Features
Ray Data streaming backend: To make large-scale batch inference on mixed CPU and GPU node clusters easier to run at scale, we’re working on adding first-class streaming inference support to Ray Data: https://github.com/ray-project/enhancements/pull/18
Async requests in Ray Serve: We are looking to enhance Ray Serve to natively handle long-running async jobs such as fine-tuning requests. These requests typically take minutes to run, much longer than normal ML inference jobs of <10s, which often means users have to turn to using an external job queue: https://github.com/ray-project/ray/issues/32292
New examples we’re releasing
Of course, a big difference exists between workable in theory and working in practice. To bridge this gap, we’re also announcing the initial release of several generative AI examples, which we will expand over time as new models and frameworks emerge.
The linked examples may require you to use a nightly version of Ray — links and examples will be available on a stable version of Ray with Ray 2.4.
- Stable Diffusion
- Fine-Tuning
- Serving
- Batch Prediction
- Streaming Batch Prediction: coming in Ray 2.5
- GPT-J
- Fine-Tuning
- Serving
- Batch Prediction
- Streaming Batch Prediction: coming in Ray 2.5
- OPT-66B
- Fine-Tuning: coming in Ray 2.5
- Serving: coming in Ray 2.5
- Batch Prediction: coming in Ray 2.5
- Streaming Batch Prediction: coming in Ray 2.5
Conclusion
In summary, we believe generative models accelerate the need for a flexible, unified framework such as Ray for running ML computations. The Ray team plans to add enhanced APIs for working with these types of expensive models at scale and examples and integrations with popular models and community frameworks to make it easy to get started. Get started with Ray ML use cases here, and take a look at our code examples of using Ray for generative AI workloads on our examples page.
Article originally posted here by the Ray team. Reposted with permission.