

{kind=link}
Designing Social Media News Feed System
When you open your favorite social media app like Instagram, Facebook, LinkedIn or Twitter, you’re instantly shown a personalized stream of posts.
These can include text updates, photos and videos from the people and pages you follow or from posts your friends have engaged with.
This seamless and engaging experience is made possible by the news feed system, one of the core features of any modern social platform.
But building a system that delivers this experience to 100 million+ daily active users (DAUs) is anything but simple.
It brings up several complex challenges like:
-
How do we process and store the massive volume of new posts generated every second?
-
How do we efficiently support rich media like high-quality images and videos?
-
How do we ensure each user’s feed updates in near real-time?
-
How do we handle the “celebrity” problem, where one post needs to reach millions of followers quickly?
-
How do we personalize the feed beyond simply showing the latest posts?
-
How do we avoid showing the same post to a user repeatedly?
In this article, we’ll start with a basic version of a news feed system and evolve it step by step into a robust, scalable and reliable distributed architecture.
Requirements
Before we jump into the design, let’s define what our “news feed” system needs to support, both functionally and non-functionally.
Functional Requirements:
-
Users can create posts containing text, images, or videos.
-
Users can follow other users (friends or connections)
-
Users can view a personalized news feed consisting of relevant and recent posts from people they follow
-
Users can like and comment on posts.
-
New posts should appear in a user’s feed within a few seconds
-
The system must handle users with very large followings, such as celebrities or influencers
Non-Functional Requirements:
-
Scalability: Support extremely high read (news feed fetches) and write (post creations, likes, comments). The system should scale horizontally to handle growth.
-
Availability: Ensure high availability (99.99% or higher), even under heavy load or partial system failures.
-
Low Latency: Serve news feed requests quickly (e.g. under 500ms). New posts should propagate to followers’ feeds within a few seconds.
-
Eventual Consistency: The system can tolerate slightly stale data (e.g., a like count that lags by a few seconds) in favor of availability and performance.
-
Reliability: Guarantee that no posts, likes, or comments are lost.
With these requirements in mind, we’ll now design the system in stages, starting from a naive version and incrementally adding the necessary components and optimizations.
Note: This article focuses on how such a system might actually be built and evolved over time in the real world. However, in system design interviews, time is limited. You’re not expected to cover every small detail or go step by step—just make sure your design reflects the key requirements and trade-offs.
Step-by-Step Design
1. Basic Design – Monolithic Feed Generation
Let’s start with the simplest version of a news feed system.
In this basic design, everything runs through a single application server. The same server handles post creation, following, feed generation, likes, and comments. All data is stored in one relational database. Users can only post text based content.
Architecture Overview
The basic setup includes three main components:
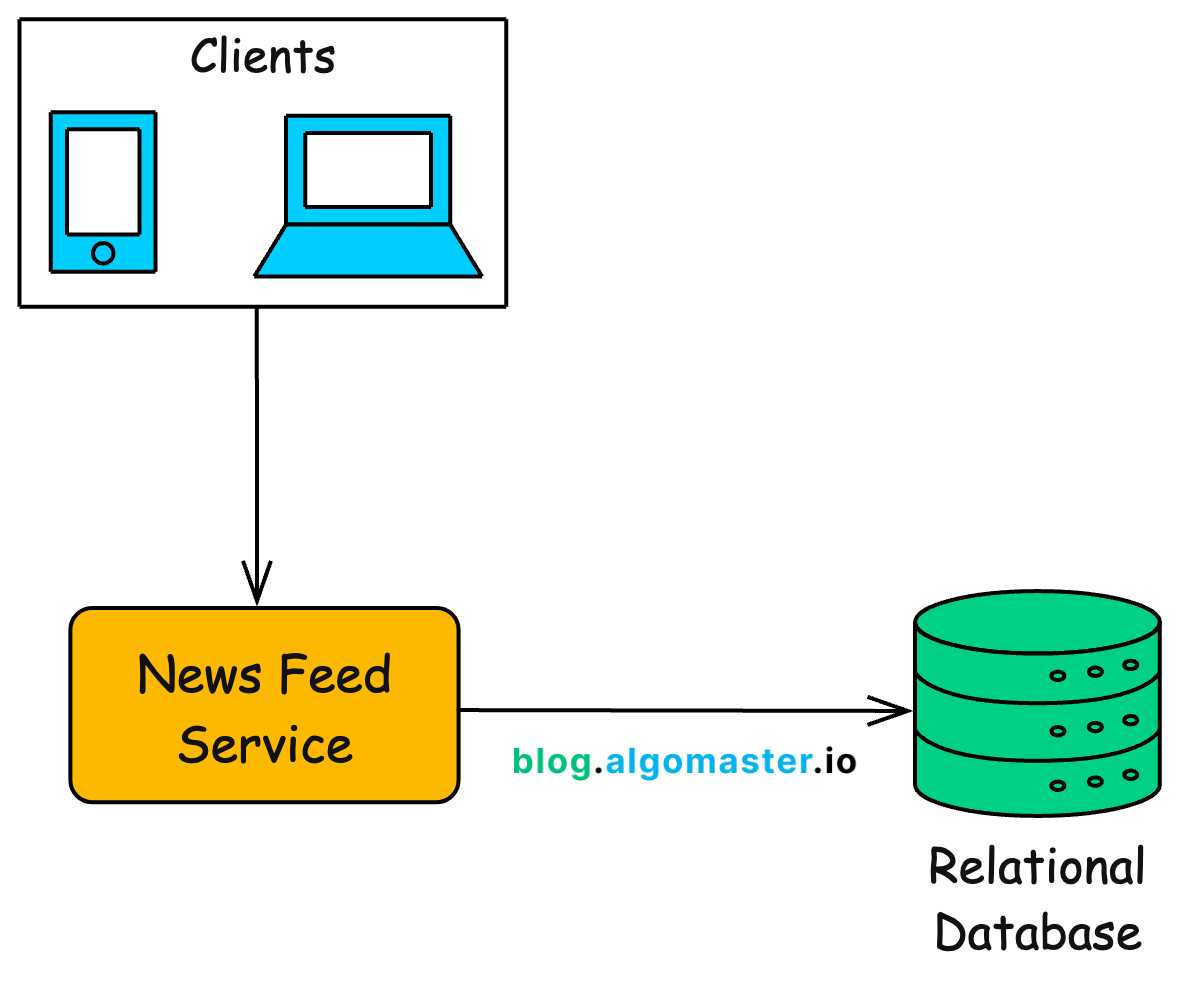
-
Clients: Mobile apps and web clients talk to the server using REST APIs.
-
News Feed Service: A single server handles HTTP requests and serves all APIs.
-
Relational Database: A single database (like PostgreSQL or MySQL) that stores all users, posts, follows, likes, and comments.
Data Model
To support core functionality of our news feed system, we maintain several key entities (tables) in the database. These form the foundation for features like post creation, following, liking, commenting, and feed generation.
-
Users: Stores user profile information.
-
Schema:
user_id, name, bio, profile_pic_url
-
-
Posts: Stores individual posts created by users.
-
Schema:
post_id, author_id, content, timestamp, like_count, comment_count
-
-
Follows: Represents the social graph, who follows whom.
-
Schema:
follower_id, followee_id
-
-
Likes: Tracks which user liked which post, along with the timestamp of the action.
-
Schema:
post_id, user_id, timestamp
-
-
Comments: Stores comments added to posts. Each comment is associated with a specific post and user.
-
Schema:
comment_id, post_id, user_id, content, timestamp
-
All of this is stored in a relational database such as PostgreSQL or MySQL.
We add indexes on commonly queried fields like user_id, post_id, and timestamp to support efficient lookups, sorting, and joins.
API Endpoints
Here are the core APIs that power the system’s basic functionality:
-
POST /posts– Create a new post -
GET /feed– Fetch a user’s personalized news feed -
POST /posts/{id}/like– Like or unlike a post -
POST /posts/{id}/comment– Add a comment to a post -
GET /posts/{id}/comments– Retrieve paginated comments for a post
These APIs form the base upon which we will later build more advanced features like media handling, feed ranking, real-time updates, and more.
User information is typically passed to APIs via authentication tokens, not raw user IDs in the request.
Example Request:
POST /posts/12345/like
Authorization: Bearer eyJhbGciOi...Like Flow
When a user likes a post:
-
A record is inserted into the
Likestable to record the interaction -
The
like_countfield in thePoststable is incremented -
These updates are done in a single transaction for strong consistency.
BEGIN; -- 1. Insert into Likes table INSERT INTO Likes (post_id, user_id, timestamp) VALUES (123, 'user_456', NOW()); -- 2. Increment like count UPDATE Posts SET like_count = like_count + 1 WHERE post_id = 123; COMMIT;
The feed includes the updated like count when the post is fetched.
Comment Flow
When a user adds a comment:
-
A record is added to the
Commentstable -
The
comment_countfield in thePoststable is incremented
For simplicity, we assume that comments are text-only and do not support replies or likes.
Comments are typically not fetched as part of the feed. Instead:
-
The feed may include one or two recent comments as a preview
-
The full list of comments is retrieved separately via a paginated endpoint
Comments are usually sorted by timestamp, with the most recent comments shown first. If needed, we can extend this to support “top” comments based on likes or relevance later.
Feed Generation: Naive Pull-Based Approach
In this model, the news feed is generated on-the-fly every time a user opens the app.
Here’s how it works:
-
Lookup followees: The system first retrieves the list of users that the requesting user follows.
-
Fetch recent posts: Then it fetches recent posts from those users, sorted by timestamp. This is done using a SQL query like:
SELECT post_id, author_id, content, media_url, timestamp FROM Posts WHERE author_id IN ( SELECT followee_id FROM Follows WHERE follower_id = :current_user ) ORDER BY timestamp DESC LIMIT 100; -
Return feed to client: The server returns the top 100 most recent posts as a JSON response. The client displays them in the feed UI.
This approach is called fan-out-on-read, because the feed is computed at read time by querying posts from all followed users.
Why This Design Breaks at Scale
This approach is simple and works well for a small number of users, but it quickly becomes inefficient as the system scales.
Let’s look at the key limitations:
-
High read latency: If a user follows thousands of people, the system must scan, sort and merge a large number of posts for every feed request. This slows down response times.
-
Database bottleneck: At scale, the database cannot keep up with read traffic. For example, with 100 million daily active users, if each user fetches their feed five times a day, that’s over 500 million feed queries daily, or nearly 6,000 queries per second. A single database cannot handle this kind of load.
-
No real-time updates: In this setup, new posts only appear when the user actively pulls the feed. There is no push mechanism. That means updates may feel delayed and feeds may appear stale.
This monolithic design is a good starting point. It satisfies the basic functionality and is easy to build. But it does not scale.
As traffic increases and features grow more complex, this architecture will struggle to meet the expectations for speed, reliability, and real-time updates.
Before we begin evolving the system into a more scalable and distributed architecture, let’s first look at how we can efficiently support media content like images and videos—an essential part of any modern social feed.
2. Supporting Images and Videos
In modern social platforms, posts are rarely just text. Users frequently upload images and videos. But supporting them introduces new challenges around storage, bandwidth, and delivery speed.
Let’s explore how to store, serve, and deliver media without overwhelming our core systems.
Media in the Data Model
We don’t store raw image or video files inside our main database. Instead, we treat media as external assets and store only references to them in the post metadata.
For example:
-
A
Postrecord includes a field likemedia_urlpointing to the uploaded file. -
If we want to support multiple media files per post, we could introduce a separate
Mediatable with fields likemedia_id,post_id,media_url, andmedia_type.
For simplicity, lets assume that each post can contain at most one media file. In this case, we simply add a media_url field to the Posts table.
If the post has no media, the media_url field can simply be NULL or an empty string
The actual media files are stored in external object storage like Amazon S3, Google Cloud Storage, or an internal distributed file system and ideally served through a CDN.
Updated Architecture
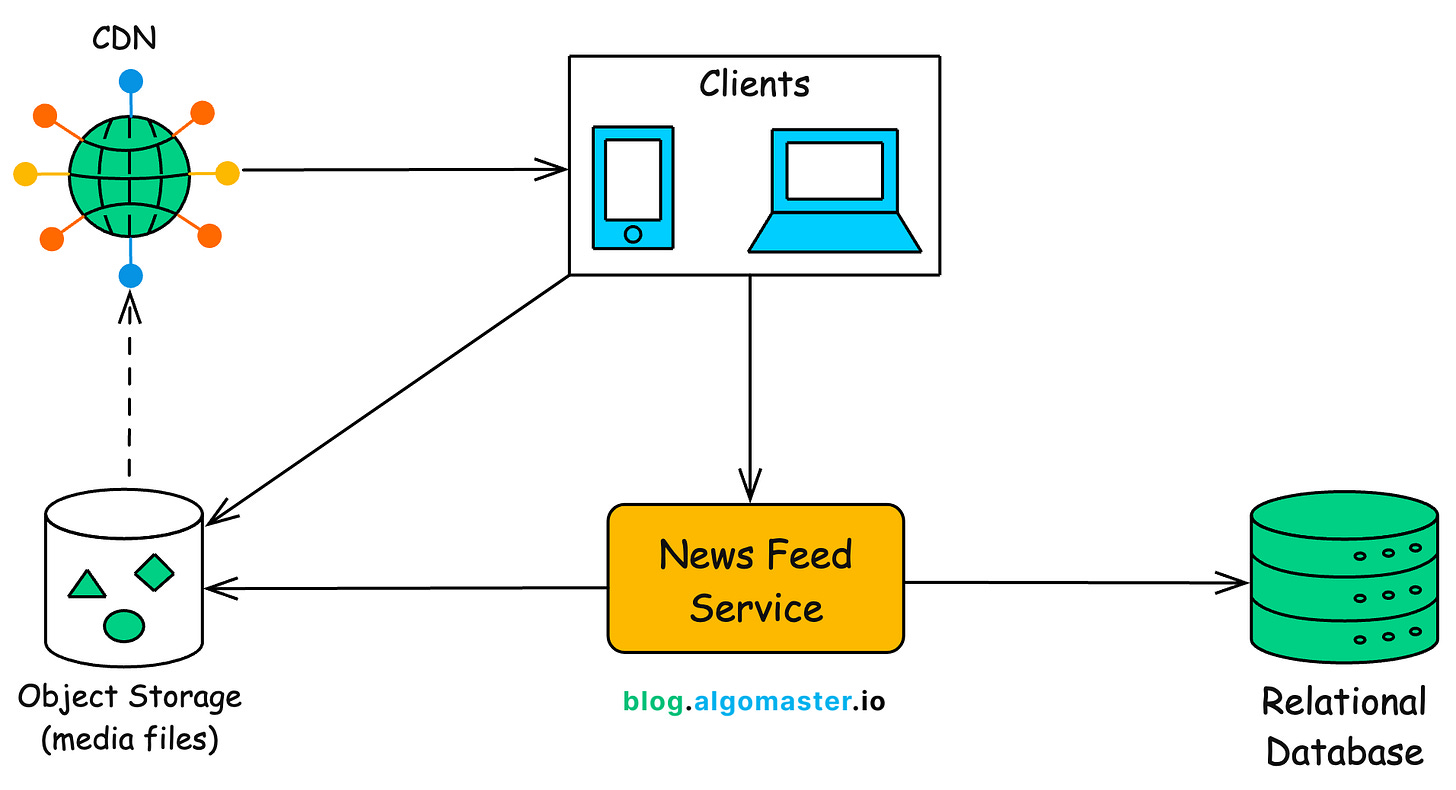
How Media Upload Works
Let’s walk through what happens when a user creates a post with an image or video.
-
Client requests upload URL: The client requests the backend (Post Service) to provide a secure upload URL. The server responds with a pre-signed URL from object storage provider and derives a CDN-accessible URL from the storage path.
{ "upload_url": "https://s3.amazonaws.com/bucket/posts/123456.jpg", "media_url": "https://cdn.myapp.com/posts/123456.jpg" } -
Client uploads media directly: Using the pre-signed
upload_url, the client uploads the file directly to object storage. This reduces load on our servers since media never passes through them. -
Client creates the post: After the upload completes, the client sends a
POST /postsrequest with the post text, timestamp, and media URL. The Post Service saves the new post in the database with themedia_urlincluded.
How Media is Delivered
When a user fetches their feed (via GET /feed), the server includes the media_url for each post in the response. The client then fetches the image or video directly from that location.
Since images and videos are large and bandwidth-intensive, we deliver them through a Content Delivery Network (CDN).
A CDN is a network of globally distributed edge servers that cache content close to end users. When a user views their feed:
-
Text and metadata come from our backend servers
-
Images and videos are fetched in parallel from the nearest CDN edge node
This improves page load time, reduces latency, and takes the pressure off our origin servers.
To further optimize:
-
Images can include a thumbnail version for faster loading during scrolling
-
Videos can be streamed using protocols like HLS or DASH, enabling progressive playback and adaptive quality based on the user’s connection
With media support in place, users can now post photos and videos, and see them quickly in their feed.
Our system now supports:
-
Basis feed generation
-
Rich media posts with images and videos
However, the architecture is still monolithic. All logic runs in a single backend service, and all data lives in one relational database.
The core system is not yet ready to handle large-scale traffic.
To scale further, we need to break the system into independent services and distribute our database across multiple servers.