

{kind=link}
Designing a Distributed Key-Value Store (Step-by-Step)
A key-value store is a simple type of database where data is stored as {key: value} pairs. Clients can retrieve or update values by providing the corresponding key, similar to how a hash table works.
A distributed key-value store takes this concept a step further. Instead of storing all the data on a single machine, it spreads the data across multiple servers (or nodes).
This distribution enables the system to scale horizontally, handling large volumes of data and user requests, while maintaining low latency and high reliability.
But this also introduces a new set of challenges like:
-
How do we efficiently store and retrieve data?
-
How do we persist data to prevent loss during node crashes?
-
How do we evenly distribute data across multiple nodes?
-
How do we keep the data consistent across nodes?
-
How do we detect and recover from node failures?
In this article, we’ll walk through how to design a distributed key-value store from the ground up, one that is capable of handling large-scale workloads with low latency, high availability, and fault tolerance.
We’ll begin by identifying the functional requirements (what the system should do) and non-functional requirements (how the system should behave).
Then, we’ll start with a single-node setup and progressively evolve it into a fully distributed system, one building block at a time.
Along the way, we’ll explore key system design concepts such as:
-
Data partitioning
-
Consistent hashing
-
Replication
-
Leader election
-
The CAP theorem
-
Consistency models (strong, eventual, causal)
-
Storage Engine Design
By the end of this post, you’ll have a solid understanding of what it takes to build a production-grade distributed key-value store and the trade-offs involved at each stage of the design.
Requirements
1. Functional Requirements
At its core, our key-value store must support basic CRUD operations focused on keys:
-
PUT (key, value) – Insert a new key-value pair or update the value if the key already exists. This is the primary write operation.
-
GET (key) – Retrieve the value associated with a given key. If the key doesn’t exist, return an appropriate result (e.g. null or error).
-
DELETE (key) – Remove the key and its associated value from the store. After deletion, a subsequent GET on that key should indicate that it no longer exists.
2. Non-Functional Requirements
To be usable at scale, our distributed store must meet several critical non-functional goals:
-
Scalability: The system should scale horizontally to handle massive amounts of data and traffic as demand grows.
-
High Availability: The store must remain accessible with minimal downtime, even in the face of server failures. There should be no single point of failure.
-
Low Latency: Operations like GET and PUT should return results quickly—ideally within a few milliseconds.
-
High Throughput: The system should support a large number of operations per second and serve many concurrent clients without significant performance degradation.
Step-by-Step Architecture
1. Start Simple – A Single Node Key-Value Store
Before jumping into a fully distributed setup, it’s important to understand the basics. Let’s start with the simplest version of a key-value store: one that runs on a single machine.

At this stage, the entire system consists of just one server responsible for handling all client requests.
The design is straightforward:
-
The server stores data in memory, using a hash map or dictionary-like structure.
-
It exposes basic operations:
-
PUT(key, value) – Add a new entry or update an existing one
-
GET(key) – Retrieve the value for a key
-
DELETE(key) – Remove a key and its value
-
Here’s a basic Java-like pseudocode for the core logic:
Map<String, String> store = new HashMap<>();
void put(String key, String value) {
store.put(key, value);
}
String get(String key) {
return store.getOrDefault(key, null);
}
void delete(String key) {
store.remove(key);
}Clients send HTTP requests (or use some lightweight protocol), and the server responds accordingly.
For example:
-
PUT /set?key=user1&value=John -
GET /get?key=user1 -
DELETE /delete?key=user1
This setup works perfectly for simple use cases, small-scale prototypes, or local development environments but this architecture breaks down quickly in real-world scenarios:
-
No Fault Tolerance: If the server crashes, the data is lost, and the system becomes unavailable.
-
Limited Capacity: You’re constrained by the memory, CPU, and storage of a single machine.
-
No Scalability: The system can’t handle growing traffic or data volume. There’s no way to scale out by adding more machines.
-
Single Point of Failure: One bug, hardware issue, or network failure can bring the entire system down.
2. Add Persistence – Don’t Lose Data on Restart
Our single-node key-value store works, but only until the server crashes or restarts. Once that happens, everything in memory is wiped out. All the data is gone.
To make our store useful in the real world, we need persistence, a way to ensure data survives restarts, crashes, or power failures.
Let’s walk through how we can add persistence without complicating the system too much.
Write-Ahead Log (WAL)
The most common and reliable approach is to use a Write-Ahead Log. Before making any change to the in-memory data, we append the operation to a file on disk.
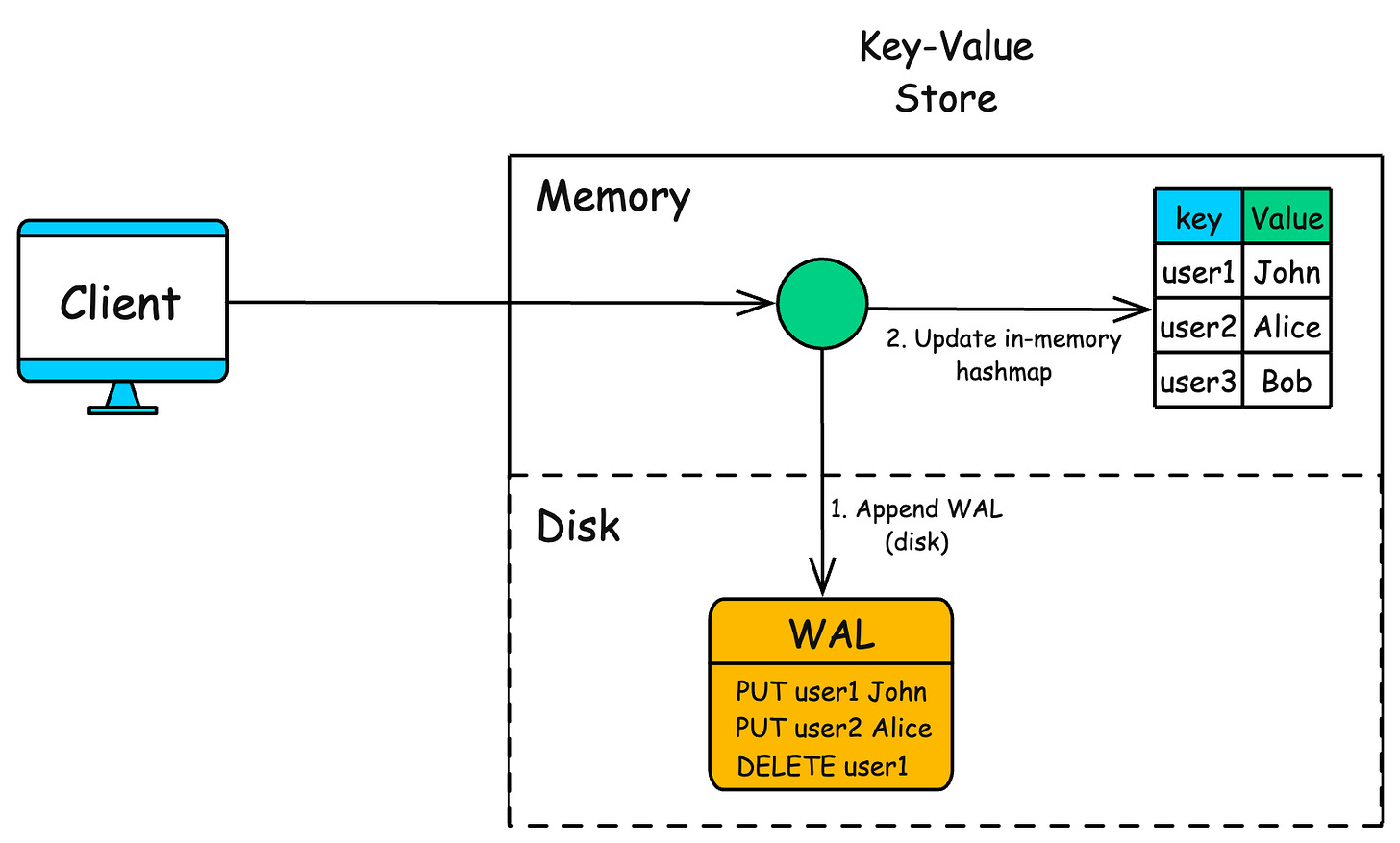
Every time a PUT or DELETE is issued, it’s logged to disk before applying it to the in-memory store.
Why this works:
-
If the server crashes, we can replay the log during startup to rebuild the state.
-
It ensures durability without relying entirely on memory.
Snapshotting – Speeding Up Recovery
Over time, the log file grows. Replaying thousands (or millions) of operations on startup can be slow.
To fix this, we periodically create snapshots, a full dump of the current in-memory key-value store to disk.
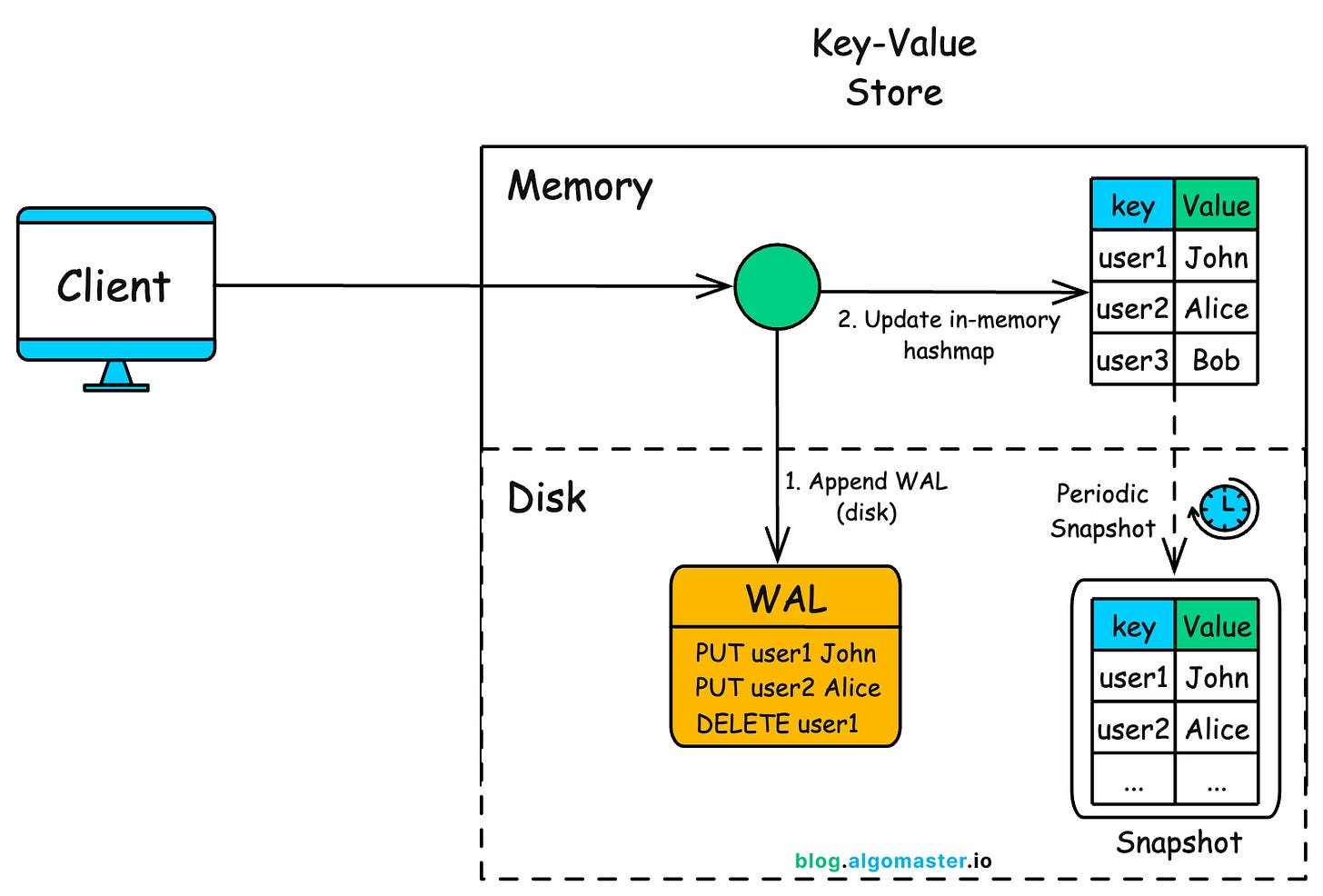
This way, on recovery:
-
Load the latest snapshot.
-
Replay only the log entries after the snapshot.
This reduces startup time while keeping the system durable.
By adding persistence, we’ve made our system:
-
Durable: Data won’t vanish after a restart.
-
Recoverable: We can rebuild state even after a crash.
-
More production-ready: Still basic, but safer.
At this point, we’ve built a durable single-node key-value store. It can survive crashes and restarts. But there’s one major problem we haven’t solved yet:
It doesn’t scale.
What happens when:
-
The amount of data exceeds the capacity of a single machine?
-
Traffic spikes and one server can’t keep up?
-
We want to support millions of users?
A single server also creates a single point of failure—any bug, hardware failure, or crash can bring the entire system down.
To overcome these limitations, we’ll move toward scaling horizontally by partitioning the data across multiple nodes.