
{kind=link}

How amazing would be a model that can answer questions from any paragraph by extracting word(s) from the paragraph that are most relevant. Deep learning has made this possible!
See below a demo for such a question-answer super model. In this demo you can put in any context up to 300 words and ask any type of question from it. The model is hosted on AWS from where the results are returned. I apologise for the demo being a bit slow since I didn’t yet get a chance to optimize this model for deployment.
DEMO Link: http://www.deeplearninganalytics.org/demos
This model is very versatile and can have many practical applications. For example — as a bot it can be linked to any webpage so user can ask questions and it can search the page for answer. Another idea that I personally find very useful is to link to contractual terms that most people just click I agree without reading. What if user could ask questions that are important and they don’t need to read a whole bunch of legal mumbo-jumbo. See a small example below:
Context: Conversion clauses are often found in ARM contracts. This feature allows you to convert the ARM to a fixed-rate mortgage at a designated time. The terms and conditions vary from lender to lender. Generally, though, you must give your lender 30 days’ notice before converting. You must also pay a fee, usually $250 to $500. Some lenders specify when a conversion can be made, while others allow it any time during the first three to five years of the loan.
Question: What is the fee associated with a conversion clause?
Answer from the Model : $250 to $500
See how the model is able to relate that the last sentence that talks about the fee is related to conversion clause even though the exact term “conversion clause” is only mentioned once in the beginning. It can do co reference resolution meaning it can associate pronouns like it/them correctly to the entity.
A few amazing things about this model:
- It has been trained on Wikipedia data and is quite versatile in types of text it can make sense of. I have tried a variety of subjects from news, sports, contractual terms, property data and it truly works
- Works on different kinds of questions — Who, When, What, How etc
- The answers it returns are from the paragraph as it is coded to find the subset of words in the paragraph that are most relevant
But it is not perfect. Main drawbacks are:
- Currently it is programmed to return an answer even if a totally random question is asked. One enhancement possible is training it to not return an answer if confidence associated with the answer is low
- Model accuracy while quite good is not perfect and models will improve over time as deep learning research results in most robust methodologies
You can find the code for the model on my Github.
Now if you are curious about how this model works, I have shared details about it on my blog here.
A brief summary is:
Dataset
This model has been built on Stanford Question Answering Dataset (SQuAD1.1) dataset consisting of questions posed by crowdworkers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the corresponding reading passage. With 100,000+ question-answer pairs on 500+ articles, SQuAD is significantly larger than previous reading comprehension datasets.
Key Features of SQuAD:
i) It is a closed dataset meaning that the answer to a question is always a part of the context and also a continuous span of context
ii) So the problem of finding an answer can be simplified as finding the start index and the end index of the context that corresponds to the answers
iii) 75% of answers are less than equal to 4 words long
Model
This implementation of the model uses the BiDAF attention module with a few enhancements. The main layers in the model are:
- Input context and questions are pre-processed, converted into raw words and these words are converted into word embeddings using the pre-trained Glove model
- A bi-directional LSTM layer encodes the context and questions separately creating hidden representations that look at words before and after a given word to create an understanding of the text
- Now that we have context and question representations we need to look at them together to find answer. This is done through attention. This model uses the BiDAF attention which allows attention to flow both ways from context to question and question to context. And these 2 attentions are concatenated to create the final vector. See screenshot below
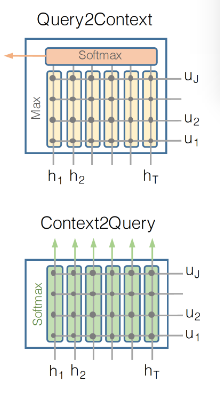
4. We also borrowed the idea of modeling layer from BiDAF using a bi-directional LSTM to learn the interaction among the query-aware
context word representations coming from the attention layer
5. The final layer of the model is a softmax output layer that helps us decide the start and the end index for the answer span. We combine the context hidden states and the attention vector from the previous layer to create blended reps. These blended reps become the input to a fully connected layer which uses softmax to predict the probability of the start and end index
Give me a clap if you liked this post:) Hope you pull the code and try it yourself. Also please play around with the demo and share any feedback you have.
Other writings: http://deeplearninganalytics.org/blog
PS: I have my own deep learning consultancy and love to work on interesting problems. I have helped several startups deploy innovative AI based solutions. Check us out at — http://deeplearninganalytics.org/.
If you have a project that we can collaborate on, then please contact me through my website or at priya.toronto3@gmail.com
References:
Original Source