

{kind=link}
Our world is constantly changing and what’s considered true and obvious today may not be so tomorrow. This is particularly true in the world of machine learning models.
The objective of machine learning models is to extract patterns from past data and use them to predict future behavior for unseen instances. These patterns, also referred to as “concepts,” represent the relationships between variables.
When these relations change in the real world, the patterns our model learned may be invalid and thus limit the predictive power of the model. This phenomenon is called “concept drift” and occurs when data experiences a change – usually in a live production environment – in the distribution of a single feature, a combination of features, or the class boundaries.
As more and more machine learning models are deployed and used in live environments for real-world applications, concept drifts are becoming a major issue. Given their ability to negatively impact the models’ accuracy and reliability, especially in our digital and big data era where it is unrealistic to expect that data distributions stay stable over a long period of time, drifts are a top concern for data science teams scaling their use of ML. Indeed, the amount of time spent maintaining models by detecting changes and their impacts on the model’s health is exponential and is definitely a core – and painful – part of the day-to-day of any team maintaining models in a live production environment.
There are multiple, sometimes inconsistent, definitions and terminologies to the ‘concept drift’ term and to the different types of drifts. In this article, we discuss the concept drift phenomenon and analyze the different types of drifts and common causes. This piece is part of a series that extends to how to detect drift and what to do once detected.
Concept Drift types
While ‘Concept drift’ is sometimes used as a generic term to describe changes in the statistical properties of the data or for the specific change of ![]() , the relation between the predictors and the target variable, the common formal definition is: “a change in the joint probability distribution, i.e.
, the relation between the predictors and the target variable, the common formal definition is: “a change in the joint probability distribution, i.e. ![]() [1, 2, 4], , and is also referred to as ‘dataset shift’. Since the joint probability
[1, 2, 4], , and is also referred to as ‘dataset shift’. Since the joint probability ![]() can be decomposed into smaller components, concept drift can be triggered by changes in the components of this relation:
can be decomposed into smaller components, concept drift can be triggered by changes in the components of this relation:
– Covariate shift ![]() – aka as Input drift, data drift or population drift, refers to changes in the distribution of the input variables (i.e., features). This may happen due to technical reasons, such as a change of data sources pipeline or sensors that become inaccurate over time, due to changes in the population like new types of customers or changes in the real world like users’ preferences.
– aka as Input drift, data drift or population drift, refers to changes in the distribution of the input variables (i.e., features). This may happen due to technical reasons, such as a change of data sources pipeline or sensors that become inaccurate over time, due to changes in the population like new types of customers or changes in the real world like users’ preferences.
– Prior probability shift ![]() – aka as label drift, unconditional class shift or prior probability shift, refers to changes in the distribution of the class variable (y). Two typical examples are spam and fraud detection models where the proportion of spam emails / frauds may significantly vary over time.
– aka as label drift, unconditional class shift or prior probability shift, refers to changes in the distribution of the class variable (y). Two typical examples are spam and fraud detection models where the proportion of spam emails / frauds may significantly vary over time.
– Posterior class shift ![]() – aka as conditional change, concept shift or ‘real concept drift’ – refers to changes in the relationship between the input variables and target variables, which presents the hardest type of drift to detect among the different types. The term ‘concept drift’ is often used interchangeably with a posterior class shift in reference to change in the relation between the predictors and the target variable
– aka as conditional change, concept shift or ‘real concept drift’ – refers to changes in the relationship between the input variables and target variables, which presents the hardest type of drift to detect among the different types. The term ‘concept drift’ is often used interchangeably with a posterior class shift in reference to change in the relation between the predictors and the target variable ![]() , as it is the most dramatic drift which can lead to changes in the decision boundary and requires to update the model.
, as it is the most dramatic drift which can lead to changes in the decision boundary and requires to update the model.
Some researchers distinguish between ‘real’ and ‘virtual’ concept drifts, where real concept drift usually refers to change in ![]() , while virtual drift refers to change in
, while virtual drift refers to change in ![]() or
or ![]() that does not affect the decision boundaries or the posterior probabilities
that does not affect the decision boundaries or the posterior probabilities ![]() . However, while some changes may be “virtual” and theoretically do not affect
. However, while some changes may be “virtual” and theoretically do not affect ![]() and/or the decision boundary, in most cases these changes are interrelated and it’s hard to imagine a real-world application that
and/or the decision boundary, in most cases these changes are interrelated and it’s hard to imagine a real-world application that ![]() is changed without changing
is changed without changing ![]() [2].
[2].
While the distinction between real and virtual drifts may be necessary in the research, in real-world applications it is important to monitor all types of drifts for three main reasons:
1. Each drift may lead to non-optimal performance, i.e.: when an increase in the frequency of specific types of cases (i.e., changes in p(x) or p(y)) may increase the importance of classifying these cases correctly.
2. Drifts may impact the application or it’s downstream consumers, in and out of the model context.
3. Each drift reveals different aspects of a (potentially) complex drift and helps us diagnose the root cause of a given model issue.
Causes for drifts
There are multiple possible causes for drifts. We categorize the causes into two main groups, Unrepresentative training data and non-stationary environment, and mention some of the most common causes in each group.
– Unrepresentative training data
– Sample selection bias – happens when the training data have been obtained through a biased and flawed method, and thus do not represent reliably the operating environment where the model is to be deployed [3]
– Changes in hidden variables – A difficult problem with learning in many real-world domains is the existence of a hidden variable, which cannot be measured directly, and that has a causal influence on some of the observed variables [7]. Hence, a change in this hidden variable will change the data we observe. Note that in this case, there might be no actual drift in the data source, but since we observe only a partial view, such a change will look like a concept drift.
– For example, let’s say we want to predict the number of visitors to an amusement park. We might look at the weather, the day of the week, holidays, etc. but an important factor can be the general economic situation in the public or the general public mood, which can change due to tragedy or a happy occasion (like winning an important sports competition). These factors, which cannot be measured directly, might have a crucial effect on the number of visitors (our target) or on some of our observed features.
– Non-stationary environments
– Dynamic environment – the more basic and intuitive case of non-stationarity where data and relations change is in the domain’s inherent nature. Some examples are:
– Any system following users’ personal interests, like an advertisement, where users change their preferences.
– Use-cases that are affected by weather, like traffic predictions, where models might be trained on data from the recent months before seasonal changes.
– Competitor moves who may change their pricing/offers or new competitors appearance, which may change the market dynamic.
– Regulations changes
– Technical issue – broken pipeline or changes in one of the values of the feature – either due to bug or deliberate unannounced schema change or even a change in the default value – in the upstream data source.
– Adversarial classification problems – Some common examples are spam filtering, network intrusion detection or fraud detection where attackers are changing their methods in order to bypass the model.
– Deliberate business actions – i.e.: the launch of a marketing campaign that attracts new types of users or change in a website which may (or may not) affect the users behavior.
– Domain shift – Refers to changes in the meaning of values or terms. For example, Inflation reduces the value of money, thus an item price or a person’s income will have different effects in different times. Another example is change of terms meaning, ‘corona’ web-search would retrieve completely different results in 2020 compared to 2019.
– Hidden feedback loops – In many cases, deploying a model in a live environment inevitably changes that environment and invalidates the assumptions of the initial model in the process
Change patterns
The word ‘drift’ may imply a gradual change over time, but actually, these changes in data distribution over time may manifest in different forms. Patterns of changes can be categorized according to the transition speed from one concept to another:
– Sudden – A drift may happen suddenly/abruptly by switching from one concept to another, e.g., replacement of a sensor with another sensor that has a different calibration.
– Incremental (/stepwise) – consists of a sequence of small (i.e., not severe) changes. As each change is small, the drift may be noticed only after a long period of time, even if each small change occurs suddenly, e.g., a sensor slowly wears off and becomes less accurate
– Gradual – referring to a transition phase when both concepts are active. As time passes, the probability of sampling from the initial concept decreases and the probability of sampling from the new concept increases. For example,
– Blip – One of the challenges for concept drift handling algorithms is not to mix the true drift with an outlier or noise which refers to a once-off random deviation or anomaly

Another type of drift pattern is recurrent drifts – That is when a previously active concept reappears after some time. It differs from the common seasonality notion in a way that it is not certainly periodic, it is not clear when the source might reappear.
Sub-population change
Typically, concept drift refers to changes in the general population but more often than not such changes take place in the form of sub-concept change (also referred to as subconcept drift or intersected drift) where drift is limited to a subspace of the domain. For example, a change in users’ behaviors can occur only for a specific user segment like users from a specific country or in some age range. Subconcept drifts, not only are they more common, but they are also harder to detect as you need to monitor each subpopulation separately.
In the figure below, taken from superwise.ai monitoring solution, each row shows a measure of the statistical distance of the input over time relative to its training set. Wherever the line is higher, the data differs from the training set. The top strip is the level of distribution change, relative to the training data for the entire population and the strips below are the change level for specific segments (subpopulation) defined by the customer. One can see that there is clear seasonality and that in the past, major global events occurred that impacted all segments. In the period framed in blue though, we can see Segment A experienced a significant change which only slightly affected the general population measurement.
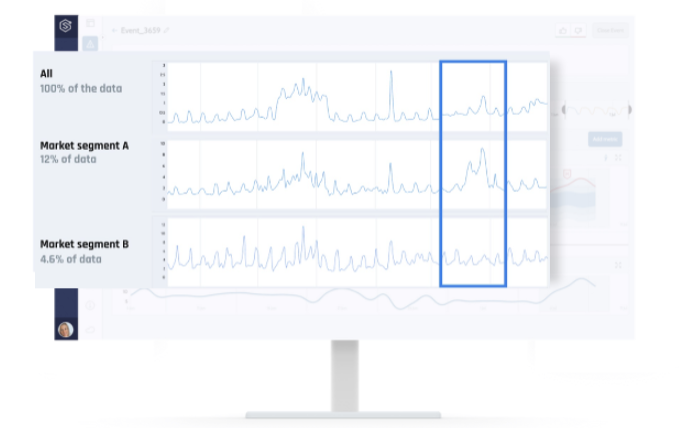
Picture taken from superwise.ai solution
Final thoughts on Concept Drift
The “Concept Drift” phenomenon, where data changes over time in unforeseeable ways and which can occur due to exogenous or endogenous factors, is a major issue that greatly impacts the performance of the models in many real-world applications. This problem intensifies as organizations scale their use of ML by managing multiple models for different use cases, and where manually supervising the models in production is no longer feasible. Understanding and detecting drifts is a nontrivial task and should be part of the strategic discussions dedicated to the formation and selection of an optimal MLOps infrastructure. In this post, we have clarified and categorized the different types of drifts and their common causes. In our upcoming part II, we will focus on how to detect them.
References on Concept Drift
1. A Survey on Concept Drift Adaptation
2. Ensemble learning for data stream analysis: A survey
3. A unifying view on dataset shift in classification
4. Learning under Concept Drift: A Review
5. Characterizing Concept Drift
6. Understanding Concept Drift
7. The problem of concept drift: definitions and related work
About the author on concept drift: Liran Nahum (MSc Applied Statistics & Machine Learning), has over 7 years of data science experience in enterprise and startups, researching and participating in AI activities across several verticals and functions. Currently leading the research at superwise.ai, the leading AI Assurance platform.