



{kind=link}
This article was published as a part of the Data Science Blogathon.
Introduction
Computer Vision is evolving from the emerging stage and the result is incredibly useful in various applications. It is in our mobile phone cameras which are able to recognize faces. It is available in self-driving cars to recognize traffic signals, signs, and pedestrians. Also, it is in industrial robots to monitor problems and navigating around co-workers.
The main purpose of Computer Vision is to make computers see and clarify the world like humans or maybe better than us. Computer Vision often uses programming languages like C++, Python, and MATLAB. It is an important technique for Augmented Reality. The Popular Computer Vision tools needed to learn is OpenCV, Tensorflow, Gpu, YOLO, Keras, etc., The field of Computer Vision heavily includes concepts from areas like Digital Signal Processing, Neuroscience, Image Processing, Pattern Recognition, Machine Learning (ML), Robotics, and Artificial Intelligence (AI).
Here I am going to explain the detailed structure of “Computer Vision Pipeline”.
Before going to that let’s understand what exactly Computer Vision is:
Computer vision is the field of having a computer understand and label what is present in an image.
For example, look at the image given below:

From the above image, To interpret what a Dress is or what a shoe is, It’s not easy to elaborate about clothing who had never seen it before. It’s the same problem with Computer Vision.
To solve the problem, we need to use a lot of pictures of clothing, shoes, and handbags and tell the computer what’s that picture is, and then have the computer figure out the patterns that give you the difference between a dress, shoe, shirt, and handbags.
Computer Vision Applications:
Computer Vision has been used widely in various sectors. Here are a few examples:
-
Recognize objects and behavior
-
Self-driving cars
-
Medical Image Analysis & Diagnosis
-
Photo Tagging
-
Face Recognition
Computer Vision Pipeline:
A Computer Vision Pipeline is a series of steps that most computer vision applications will go through. Many vision applications start by acquiring images and data, then processing that data, performing some analysis and recognition steps, then finally performing an action.
The General Pipeline is pictured below:
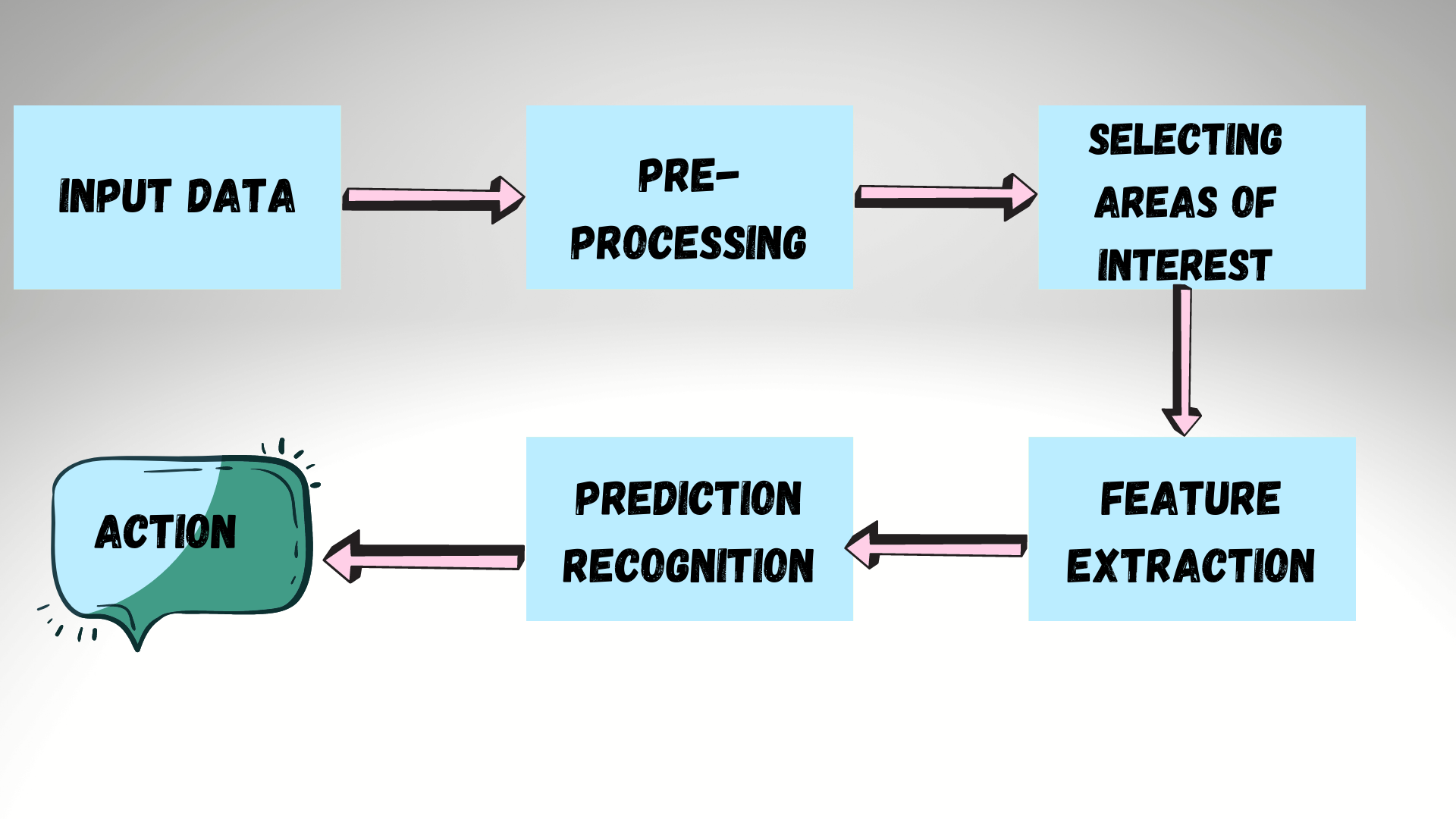
To know how practically pipelining works. Let us see for Facial Recognition Pipeline as follows:
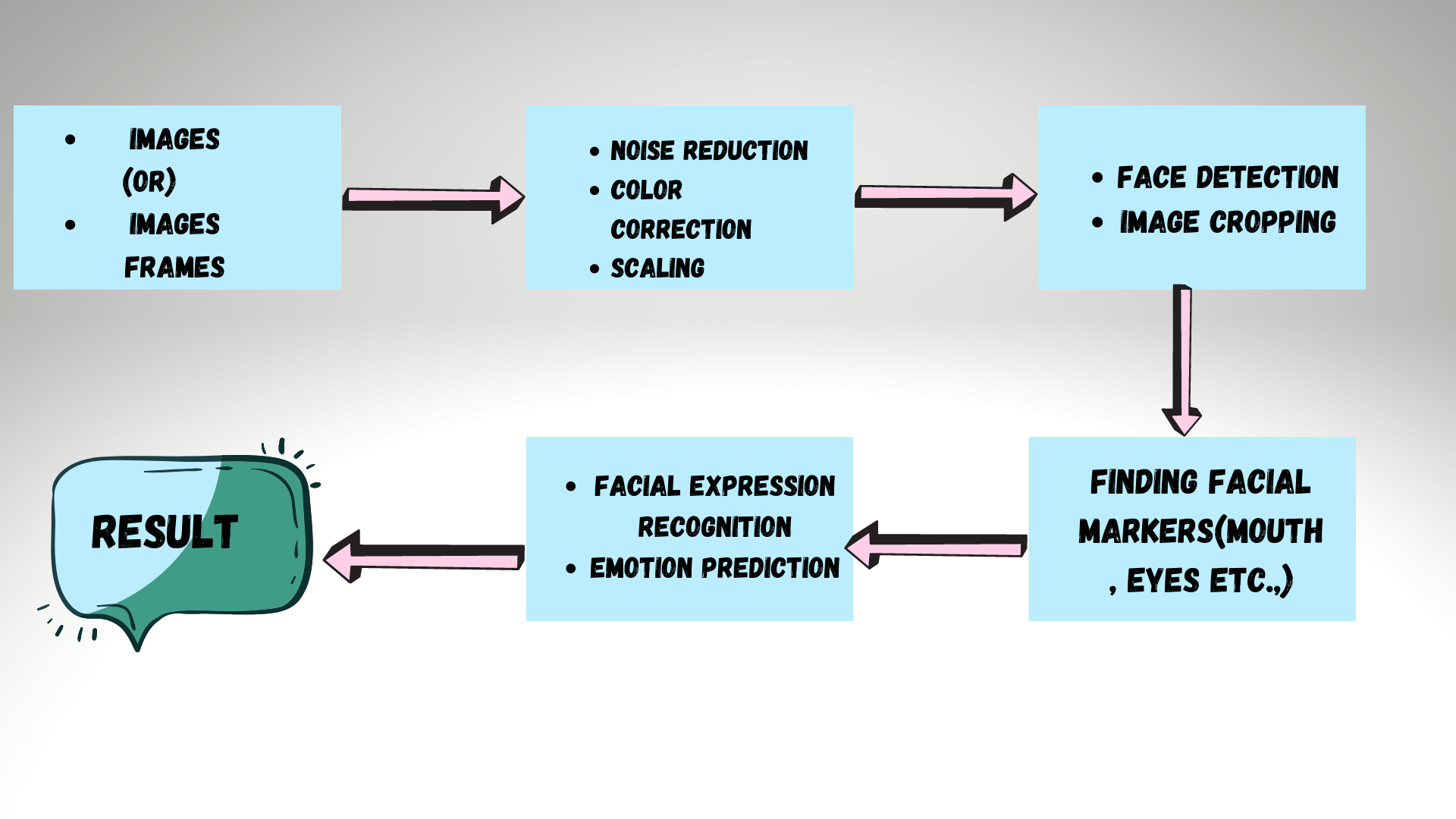
The main step or first step is all about standardizing Data. So Let’s know about Standardizing Data.
Standardizing Data:
Pre-processing images is all about standardizing input images so that you can move further along the pipeline and analyze images in the same way. In machine learning tasks, the pre-processing step is often one of the most important.
For example, imagine that you have created a simple algorithm to distinguish between red roses and other flowers:
The algorithm counts up the number of red pixels in a given image and if there are enough of them, it classifies as a red rose. In this example, we are just extracting a color feature.
Note: If the images are different sizes or even cropped differently then this counting tactic will likely fail! So it is essential to pre-process the images so that they are standardized before they move along the pipeline.
Images as Numerical Data:
Every pixel in an image is just a numerical value and we can also change these pixel values. We can multiply every single one by a scalar to change how bright the image is, we can shift each pixel value to the right, and many more operations.
Treating images as grids of numbers is the basis for many image processing techniques. Most color and shape transformations are done just by mathematically operating on an image and changing it pixel by pixel.
Training a neural network:
To train a neural network, we typically provide sets of labeled images, which we can compare to the predicted output label or recognition measurements. The neural network then monitors any errors it makes and corrects for them by modifying how it finds and prioritizes patterns and differences among the image data.
Gradient Descent is a mathematical way to minimize errors in neural networks.
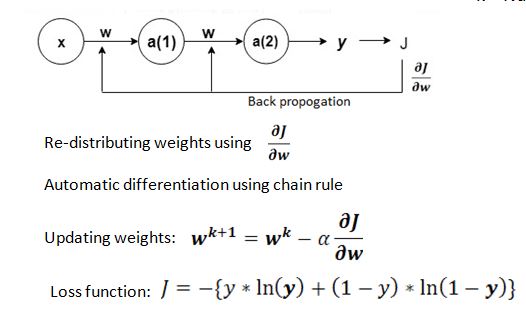
X =Input
a = Activation function
W = weights in CNN
J = Loss function
Alpha = Learning rate
y = ground truth
y = Prediction
k = Number of iteration
Convolutional neural networks are a specific type of neural network that is commonly used in computer vision applications. They learn to recognize patterns among a given set of images.
To refer to a few more articles, Follow the mentioned link below:
https://medium.com/@likhithakakanuru