



Overview

So what does the newest release of PyTorch, i.e, 1.9 have to offer? Facebook’s PyTorch team has vastly amped up its support for accelerated implementations in the domain of distributed training and scientific computing. This release is composed of over 3,400 commits since version 1.8, made by 398 contributors. Let’s go over the new improvements:-
- Improved support towards scientific computing which includes the likes of the torch.linalg, torch.special.
- Major improvements to Autograd support over 98% of operators providing the functionality to calculate complex gradients and optimize real-valued loss functions with complex variables.
- TorchElastic has now been added to Pytorch Core for gracefully handle scaling events.
- Pytorch RPC now supports large scale distributed training with GPU support
- New APIs to optimize performance and packaging for model inference deployment
- Support for Distributed training, GPU utilization, and SM efficiency in the PyTorch Profiler
Well, there is a lot to cover here so strap in. Before we dive in, please note that some of these improvements are still in the beta phase while others are in stable condition.
Backward Incompatible changes
A few changes have been made with regard to backward compatibility. Let’s take a look at a few updates with Python API.
- torch.divide() function divides two tensors. It also consists of a rounding_mode function which when set to ‘floor’ returned the same non-finite values as other rounding modes when there is a division by zero, which means it would always result in a NaN value, but a non-zero number divided by zero should return +/- infinity. This behavior has been updated to incorporate +/- infinity when dealing with divide by zero.
a = torch.tensor([-1.0, 0.0, 1.0]) b = torch.tensor([0.0]) torch.divide(a, b, rounding_mode='floor') >> tensor([-inf, nan, inf])
Scientific Computing
With the release of version 1.9, Pytorch’s linear algebra module, torch.linalg is moving towards a stable release. linalg covers the common linear algebra operations which include Matrix Properties, Decompositions, Solvers, Inverses, Matrix Products, Tensor Operations, Experimental Functions.
The module extends PyTorch’s support for deep learning and scientific computation with implementations of every function from NumPy’s linear algebra module (now with support for accelerators and autograd). For Numpy veterans this is great news!
A few deprecation updates are:-
- torch.norm has been deprecated in favor of the new linalg module norm functions: torch.linalg.vector_norm, torch.linalg.matrix_norm, and torch.linalg.norm
- Older linear algebra operations have been deprecated in favor of their new linalg module counterparts.
Complex Autograd
This feature is also moved to stable in 1.9, which was in beta from 1.8. Since the beta release, it has extended support for Complex Autograd for over 98% of operators in PyTorch 1.9, which has improved testing for complex operators. What exactly is complex autograd?
When you use PyTorch to differentiate any function f(z) with complex domain and/or codomain, the gradients are computed under the assumption that the function is a part of a larger real-valued loss function g(input)=L The negative of gradient computed is the direction of steepest descent used in Gradient Descent algorithm. Thus, all the existing optimizers work out of the box with complex parameters. This convention matches TensorFlow’s convention for complex differentiation.
This is a required feature for multiple current and downstream prospective users of complex numbers in PyTorch like TorchAudio, ESPNet, Asteroid, and FastMRI.
Debugging
PyTorch 1.9 includes a torch.use_determinstic_algorithms option. This option works well with debugging and writing reproducible programs. To allow operations to run deterministically we set the option to true or throw a runtime error if they behave non-deterministically. That is algorithms that, given the same input, and when run on the same software and hardware, always produce the same output.
a = torch.randn(100, 100, 100, device='cuda').to_sparse() b = torch.randn(100, 100, 100,device='cuda') # We see batch matrix multiplication gives us False since Sparse-dense CUDA bmm is usually nondeterministic torch.bmm(a,b).eq(torch.bmm(a, b)).all().item() >> False # Here we see torch.bmm gives us the same results, but with reduced performance. torch.use_deterministic_algorithms(True) torch.bmm(a,b).eq(torch.bmm(a, b)).all().item() >> True
torch.nn
The nn.module now allows for parameterization of any parameter or buffer and constrains the space in which your parameters live without the need for special optimization methods.
In PyTorch 1.6, a regression was introduced that caused the bias flag of nn.MultiheadAttention only to apply to the input projection layer. causing the output projection layer to always include a bias parameter, even with bias = False specified.
# Pytorch 1.9 mha = torch.nn.MultiheadAttention(4, 2, bias=False) print(mha.out_proj.bias) >> None # Post Pytorch 1.6 mha = torch.nn.MultiheadAttention(4, 2, bias=False) print(mha.out_proj.bias) Parameter containing: tensor([0., 0., 0., 0.], requires_grad=True)
Pytorch Mobile
We see major improvements and support for iOS/Android applications. The newest release introduces the mobile interpreter which was one of the most requested features. It is a streamlined version of the Pytorch runtime. The Interpreter will execute PyTorch programs in edge devices, with a reduced binary size footprint.
There is also support for Pytorch’s Torchvision library on mobile apps. TorchVision ops and needs to be linked together with the main PyTorch library for iOS, for Android it can be added as a Gradle dependency. For those focused on deep learning on mobile and edge, devices will profit from the slimmed-down version of the PyTorch runtime is mainly meant to score with a reduced binary size.
Distributed Training
Torch Elastic has been moved into Pytorch core as of 1.9. It was previously utilized by Pytorch Lightning and Kubernetes CRD. PyTorch Elastic or TorchElastic is a framework that enables distributed training jobs to be executed in a fault-tolerant and elastic manner. It provides the primitives and interfaces for you to write your distributed PyTorch job in such a way that it can be run on multiple machines with elasticity. Some of its use cases are:-
- Fault tolerance
- Dynamic Capacity Management
Pytorch RPC now has CUDA support. Compared to CPU RPC, CUDA RPC is a much more efficient way for P2P Tensor communication. It is built on top of TensorPipe which can automatically choose a communication channel for each Tensor based on Tensor device type. The distributed RPC framework provides mechanisms for multi-machine model training through a set of primitives to allow for remote communication, and a higher-level API to automatically differentiate models split across several machines.
The RPC’s features can be broken down into 4 sets of Api’s:-
- Remote Procedure Call (RPC)
- Remote Reference (RRef)
- Distributed Autograd
- Distributed Optimizer
Pytorch Profiler
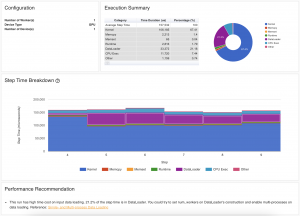
{kind=link}
The new PyTorch Profiler graduates to beta and leverages Kineto for GPU profiling, TensorBoard for visualization and is now the standard across our tutorials and documentation.
PyTorch Profiler is the new and improved performance debugging profiler for PyTorch. A PyTorch Profiler is a tool that allows the collection of performance metrics during the training and inference. Profiler’s context manager API can be used to better understand what model operators are the most expensive, examine their input shapes and stack traces, study device kernel activity, and visualize the execution trace.
PyTorch 1.9 extends support for the new torch.profiler API to more builds, including Windows and Mac. It also supports existing profiler features, integrates with CUPTI library (Linux-only) to trace on-device CUDA kernels, and provides support for long-running jobs.
A few of the changes and updates:-
- Expanded Kineto platform support
- Fixed intermittent CUDA activity flush issue
- Handled empty trace
- Added cuda synchronization points
- Fixed double printing of FLOPs
- Added CUDA event and profiler fallback
Ending Notes
With this release, users can fully harness Pytorch’s distributed training process. It also improves its overall support for mobile app deployment with the release of some of the State of the art models like Mask R-Cnn, DeiT, HuggingFace’s DistillBert, etc. While improving much of the pre-existing codebase it also brings stability to its features and modules.
Pytorch 1.9 provides a broad set of updates for the PyTorch community to benefit from!