



{kind=link}
This article was published as a part of the Data Science Blogathon.
Introduction
In this article, I have curated a list of 15 data science questions including a challenging problem that helps you while you are targeting to crack Data Science Jobs. These data science questions are based on my experience on appearing various interviews.
This article contains Data Science Questions based on:
– Probability, Statistics and Linear Algebra in Data Science
– Different algorithms of Machine Learning
What’s so special about this article?
In this article, I have given a challenging Data Science Problem which makes your thinking broad about the Data Science concepts.
Objective Data Science Questions
1. From the given principal components, which of the following can be the first 2 principal components after applying Principal Component Analysis(PCA)?
(a) [1,2] and [2,-1]
(b) [1/2,√3/2] and [√3/2,-1/2]
(c) [1,3] and [2,3]
(d) [1,4] and [3,5]
Answer: Option-(b)
Principal Component Analysis(PCA) finds the direction that is having a maximum variance of data. It finds directions that are mutually orthogonal and the calculated principal components are normalized. So, for all the given options only option-b will be going to satisfy all the properties of principal components in the PCA algorithm.
2. We cannot apply Independent Component Analysis(ICA) for which of the following probability distributions?
(a) Uniform distribution
(b) Gaussian distribution
(c) Exponential distribution
(d) None of the above
Answer: Option-(b)
We cannot apply Independent Component Analysis(ICA) to Gaussian or Normal variables since these distributions are symmetrical. Basically, this is the kind of constraint that we have to keep in mind while applying the Independent Component Analysis(ICA) algorithm.
3. Choose the correct option in the case of Linear Discriminant Analysis(LDA):
(a) LDA maximizes the distance between classes and minimizes distance within a class
(b) LDA minimizes both between and within a class distance
(c) LDA minimizes the distance between classes and maximizes distance within a class
(d) LDA maximizes the distance between and within the class distance
Answer: Option-(a)
LDA tries to maximize the between-class variance and minimize the within-class variance, through a linear discriminant function. It assumes that the data in every class are described by a Normal Distribution having the same covariance.
4. Consider the following statements about categorical variables:
Statement 1: A Categorical variable has a large number of categories
Statement 2: A Categorical variable has a small number of categories
Which of the following is true?
(a) Gain ratio is preferred over information gain for 1st statement
(b) Gain ratio is preferred over information gain for 2nd statement
(c) Category does not decide preference of gain ratio and information gain
(d) None of the above
Answer: Option-(a)
When we have a large number of features, then what happens is that we have a lot of computation to be done to compute the information gain whereas on the other side, for gain ratio we have to simply calculate the ratio instead of calculating the things individually. Therefore, for a large number of features in our hands, we are preferring the Gain ratio while using a decision tree-related machine learning algorithm for categorical variables.
5. Consider 2 features: Feature 1 and Feature 2 having values as Yes and No
Feature 1: 9 Yes and 7 No
Feature 2: 12 Yes and 4 No
For all these 16 instances which feature will have more entropy?
(a) Feature 1
(b) Feature 2
(c) Feature 1 and feature 2 both have the same entropy
(d) Insufficient data to decide
Answer: Option-(a)
For a two-class problem, the entropy is defined as:
Entropy = -(P(class0) * log2(P(class0)) + P(class1) * log2(P(class1)))
Now, we have a total of 7 no and 9 yes present in that feature X. So, by putting the values of 7/16 and 9/16 in the above formula, we get the value of entropy to be 0.988.
Similarly, we can calculate for the other feature also, and then we can easily compare.
6. Which of the following is/are true when bagging is applied to regression trees:
S1: Each tree has high variance with low bias
S2: We take an average of all the regression trees
S3: There are n regression trees for n bootstrap samples
(a) S1 and S3 are correct
(b) Only S2 is correct
(c) S2 and S3 are correct
(d) All correct
Answer: Option-(d)
Bagging is a type of ensemble technique in which we are forming the bootstrap samples from our training data and for each sample, we train a weak classifier, and finally, for the predictions on the test dataset, we combine the results of all the weak learners. Averaging of results helps us to reduce the variance while keeping bias approximate constant.
7. Determine entropy of a feature (X) having following values:
X = [0, 1, 0, 0, 1, 0, 1, 0, 1, 0, 1, 1, 1, 0, 1, 1 ]
(a) -0.988
(b) 0.988
(c) -0.05
(d) 0.05
Answer: Option-(b)
For a two-class problem(say A and B), the entropy is defined as:
Entropy = -(P(class-A) * log2(P(class-A)) + P(class-B) * log2(P(class-B)))
Now, we have a total of 7 zeroes and 9 ones present in that feature X. So, by putting the values of 7/16 and 9/16 in the above formula, we get the value of entropy to be 0.988.
8. Which of the following options is true for the Independent Component Analysis(ICA) estimation?
(a) Negentropy and mutual information of the variables are always non-negative.
(b) For statistically independent variables, mutual information is zero.
(c) For statistically independent variables, mutual information should be minimum and
negentropy should be maximum
(d) All of the above.
Answer: Option-(d)
The following things are true wrt ICA Algorithm:
– For any variables that are involved in our algorithm, the sign of negentropy and mutual information is always non-negative.
– But if we have statistically independent variables, then mutual information is zero.
– Also, for statistically independent variables, the value of mutual information will be minimum whereas, on the other hand, the negentropy should be maximum.
9. In the case of Principal Component Analysis(PCA), if all eigenvectors are the same then we can not choose principal components because,
(a) All principal components are zero
(b) All principal components are equal
(c) Principal components can not be determined
(d) None of the above
Answer: Option-(b)
In the case PCA Algorithm, which is an unsupervised machine learning algorithm, if all eigenvectors are the same then we are unable to choose principal components as in that case all the principal components become equal.
Subjective Data Science Questions
10. A society has 70% male and 30% female. Each person has a ball having either red or blue color. It is known that 5% of males and 10% of females have red-colored balls. If a person is selected at random and found to have blue balls. Calculate the probability that the person is a Male.
Solution: (0.711)
Here we use the concept of Conditional Probabilities.
P(b|m)*P(m)/[P(b|m)*P(m) + P(b|f)*p(f)] = 0.95*0.7 / (0.95*0.7+0.9*0.3) = 0.711
11. You are working on a spam classification system using Support Vector Machines(SVM). “Spam” is a positive class(y=1) and “not spam” is the negative class(y=0). You have trained your classifier and there are m=1000 examples in the validation set. The confusion matrix of the predicted class vs actual class is presented in the following chart:
| Actual Class: 1 | Actual Class: 0 | |
| Predicted Class: 1 | 85 | 890 |
| Predicted Class: 0 |
15 |
10 |
What is the average accuracy and class-wise accuracy of the classifier(based on the above confusion matrix)?
Hint: Average Classification Accuracy: (TP+TN)/(TP+TN+FP+FN)
Class-wise classification accuracy: [TN/(TN+FP)+TP/(TP+FN)]/2
where, TP = True positive, FP = False positive, FN = False negative, and TN = True negative.
Comprehension Type Questions
Consider a set of 2-D data points having coordinates {(-3,-3), (-1,-1),(1,1),(3,3)}. We want to reduce the dimensionality of these points by 1 using the Principal Component Analysis(PCA) algorithm. Assume the value of sqrt(2)=1.414. Now, Answer the following questions:
12. Find the eigenvalue of the data matrix XXT(XT represents the transpose of X matrix)
13. Find the weight matrix W.
14. Find the reduced dimensionality of the given data.
Solution: Here the original data resides in R2 i.e, two-dimensional space, and our objective is to reduce the dimensionality of the data to 1 i.e, 1-dimensional data ⇒ K=1
We try to solve these set of problem step by step so that you have a clear understanding of the steps involved in the PCA algorithm:
Step-1: Get the Dataset
Here data matrix X is given by [ [ -3, -1, 1 ,3 ], [ -3, -1, 1, 3 ] ]
Step-2: Compute the mean vector (µ)
Mean Vector: [ {-3+(-1)+1+3}/4, {-3+(-1)+1+3}/4 ] = [ 0, 0 ]
Step-3: Subtract the means from the given data
Since here the mean vector is 0, 0 so while subtracting all the points from the mean we get the same data points.
Step-4: Compute the covariance matrix
Therefore, the covariance matrix becomes XXT since the mean is at the origin.
Therefore, XXT becomes [ [ -3, -1, 1 ,3 ], [ -3, -1, 1, 3 ] ] ( [ [ -3, -1, 1 ,3 ], [ -3, -1, 1, 3 ] ] )T
= [ [ 20, 20 ], [ 20, 20 ] ]
Step-5: Determine the eigenvectors and eigenvalues of the covariance matrix
det(C-λI)=0 gives the eigenvalues as 0 and 40.
Now, choose the maximum eigenvalue from the calculated and find the eigenvector corresponding to λ = 40 by using the equations CX = λX :
Accordingly, we get the eigenvector as (1/√ 2 ) [ 1, 1 ]
Therefore, the eigenvalues of matrix XXT are 0 and 40.
Step-6: Choosing Principal Components and forming a weight vector
Here, U = R2×1 and equal to the eigenvector of XXT corresponding to the largest eigenvalue.
Now, the eigenvalue decomposition of C=XXT
And W (weight matrix) is the transpose of the U matrix and given as a row vector.
Therefore, the weight matrix is given by [1 1]/1.414
Step-7: Deriving the new data set by taking the projection on the weight vector
Now, reduced dimensionality data is obtained as xi = UT Xi = WXi
x1 = WX1= (1/√ 2 ) [ 1, 1 ] [ -3, -3 ]T = – 3√ 2
x2 = WX2= (1/√ 2) [ 1, 1 ] [ -1, -1 ]T = – √ 2
x3 = WX3= (1/√ 2) [ 1, 1 ] [ 1, 1]T = – √ 2
x4 = WX4= (1/√ 2 ) [ 1, 1 ] [ 3, 3 ]T = – 3√ 2
Therefore, the reduced dimensionality will be equal to {-3*1.414, -1.414,1.414, 3*1.414}.
Challenging Problems
15. You are given a dataset having N data points and d=2 features consisting of the inputs X ∈ Rn×d, and labels y ∈ ( -1, 1 }N, as illustrated in the figure,
Suppose that we want to learn the (unknown) radius r of a circle centered at a given fixed point c, such that this circle separates the two classes with minimum error. To do so, we need to find the parameter r(radius) that minimizes some suitable cost function E(r). How would you design/define this cost function E(r)? Also, justify why/how you choose your cost function?
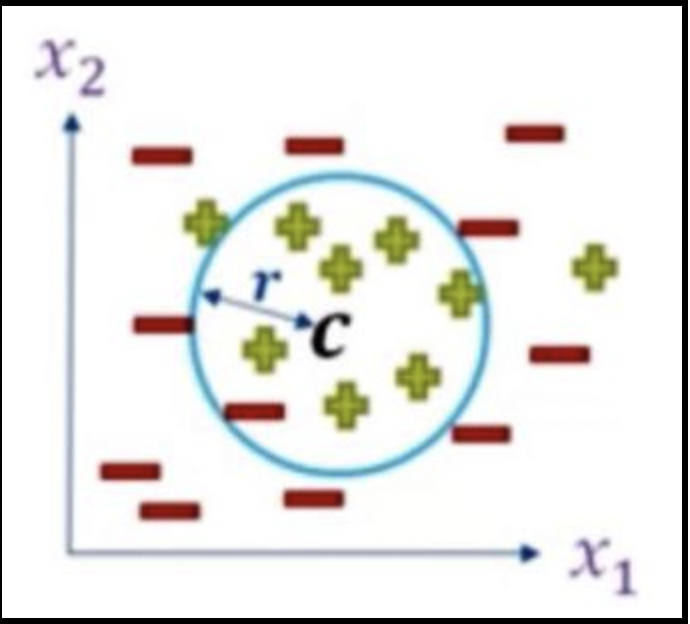
Image Source-1
E(r) = 1/N Σ max { ( ||x(i) – c|| – r ) y(i) , 0 }
Basically, in this possible solution, we are trying to find the distance of all the points wrt a particular center and then find the difference between that distance and radius of that mentioned circle, and then multiply it by the particular label of that data point and then try to find the maximum between this value and zero and then finally take the average of all the values which we got after sum up this for all the data points. This is a naive solution that we can think of for a given problem statement.
OPEN FOR DISCUSSION
Note: This problem is not having a unique answer. I put this question in this section so that all of you think about this problem and we will discuss this question in the comment box.
But, I have given one possible solution for this problem just for giving a path for thinking of some different solutions to a given problem.
Read more Data Science questions, here!
I hope that you have enjoyed this article on data science questions. If you like it, share it with your friends also. Something not mentioned or want to share your thoughts? Feel free to comment below And I’ll get back to you. 😉
Reference: Image Source 1- https://docs.google.com/document/d/1giE8zqn7O1LsM0CsXO9_QFdF4QW3VMQNEFlZsjY_QgA/edit?usp=sharing
I am currently pursuing my Bachelor of Technology (B.Tech) in Computer Science and Engineering from the Indian Institute of Technology Jodhpur(IITJ). I am very enthusiastic about Machine learning, Deep Learning, and Artificial Intelligence. Feel free to connect with me on Linkedin.