



{kind=link}
This article was published as a part of the Data Science Blogathon.
Introduction
Apache SQOOP is a specialized tool that facilitates seamless data transfer between HDFS and various structured data repositories. These repositories could include relational databases, enterprise data warehouses, and NoSQL systems. SQOOP operates through a connector architecture, which employs plugins to enhance data connections with external systems, ensuring efficient data migration.
What is Apache Sqoop?
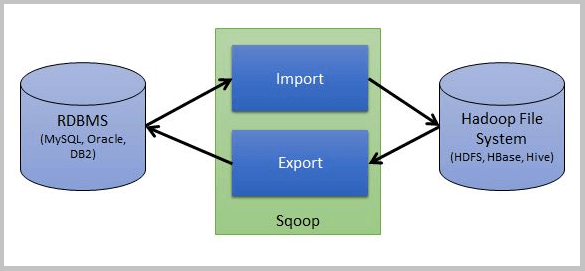
Apache Sqoop, a command-line interface tool, moves data between relational databases and Hadoop. It is used to export data from the Hadoop file system to relational databases and to import data from relational databases such as MySQL and Oracle into the Hadoop file system.
Why Use Sqoop?
A component of the Hadoop ecosystem is Apache Sqoop. There was a need for a specialized tool to perform this process quickly because a lot of data needed to be moved from relational database systems onto Hadoop. This is when Apache Sqoop entered the scene and is now widely used for moving data from RDBMS files to the Hadoop ecosystem for MapReduce processing and other uses.
(Source: https://www.freecodecamp.org/news/an-in-depth-introduction-to-sqoop-architecture-ad4ae0532583/)
Data must first be fed into Hadoop clusters from various sources to be processed using Hadoop. However, it turned out that loading data from several heterogeneous sources was a challenging task. The issues that administrators ran with included:
- Keeping data consistent
- Ensuring effective resource management
- Bulk data loading into Hadoop was not possible.
- Data loading with scripts was sluggish.
The data stored in external relational databases cannot be accessed directly by the MapReduce application. This approach puts the system in danger of having cluster nodes generate too much stress. Sqoop was the answer. The difficulties of the conventional method were completely overcome by using Sqoop in Hadoop, which also made it simple to load large amounts of data from RDBMS into Hadoop.
Most of the procedure is automated by Sqoop, which relies on the database to specify the data import’s structure. Sqoop imports and exports data using the MapReduce architecture, which offers a parallel approach and fault tolerance. Sqoop provides a command line interface to make life easier for developers. Simple details like source, destination, and database authentication information are all that developers need to include in the sqoop command. Sqoop handles the remaining portion.
Important Features of Apache Sqoop
Apache Sqoop has many essential features. Some of them are discussed here:
- Sqoop uses the YARN framework to import and export data. Parallelism is enhanced by fault tolerance in this way.
- We may import the outcomes of a SQL query into HDFS using Sqoop.
- For several RDBMSs, including MySQL and Microsoft SQL servers, Sqoop offers connectors.
- Sqoop supports the Kerberos computer network authentication protocol, allowing nodes to authenticate users while securely communicating across an unsafe network.
- Sqoop can load the full table or specific sections with a single command.
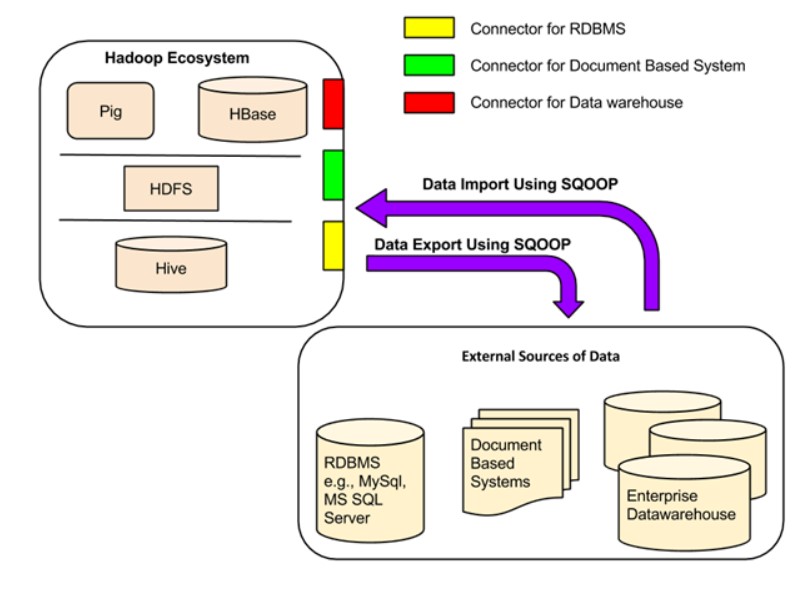
Sqoop Architecture
Using its connectors, sqoop facilitates data migration between Hadoop and external storage systems. These connectors enable Sqoop to work with various widely-used relational databases, such as MySQL, PostgreSQL, Oracle, SQL Server, and DB2. Each connector establishes communication with the corresponding DBMS it is associated with. A generic JDBC connector is also available for connecting to any database that adheres to the JDBC standard. Furthermore, Sqoop Big Data offers specialized connectors optimized for PostgreSQL and MySQL, leveraging database-specific APIs for enhanced performance.
( Source: https://www.guru99.com/introduction-to-flume-and-sqoop.html)
Furthermore, Sqoop for big data is compatible with various third-party connectors for data storage, encompassing enterprise data warehouses and NoSQL stores like Netezza, Teradata, and Oracle (e.g., Couchbase). To use these connectors, users need to download them separately and integrate them into an existing Sqoop installation; they are not included in the default Sqoop bundle.
What happens when you run Sqoop on the back end is fairly simple. The transferred dataset is divided into various divisions, and a map-only job is created with distinct mappers in charge of transferring each partition. Sqoop uses the database information to deduce the data types, handling each data record in a type-safe manner.
How does Sqoop work?
Let us look in detail at the two main operations of Sqoop:
Sqoop Import :
The procedure is carried out with the aid of the sqoop import command. We can import a table from the Relational database management system to the Hadoop database server with the aid of the import command. Each record loaded into the Hadoop database server as a single record is kept in text files as part of the Hadoop framework. While importing data, we may also load and split Hive. Sqoop also enables the incremental import of data, which means that if we have already imported a database and want to add a few more rows, we can only do it with the aid of these functions, not the entire database.
Sqoop Export:
The Sqoop export command facilitates the execution of the task with the aid of the export command, which performs operations in reverse. Here, we can transfer data from the Hadoop database file system to the relational database management system with the aid of the export command. Before the operation is finished, the data that will be exported is converted into records. Two processes are involved in the export of data: the first is searching the database for metadata, and the second is moving the data.
Advantages of using Sqoop
Using Apache Sqoop has a lot of advantages. They are:
- It entails data transfer from numerous structured sources, like Oracle, Postgres, etc.
- Due to the parallel data transport, it is quick and efficient.
- Many procedures can be automated, which increases efficiency.
- Integration with Kerberos security authentication is feasible.
- Direct data loading is possible from HBase and Hive.
- It is a powerful tool with a sizable support network.
- As a result of its ongoing development and contributions, it is frequently updated.
Limitations of Using Sqoop
Just like the advantages, there are some limitations of using Sqoop; they are:
Conclusion
Massive amounts of data must be loaded into Hadoop clusters for analytical processing using Hadoop. Several difficulties are involved with loading heterogeneous bulk data sources into Hadoop and processing it. Before choosing the best strategy for data load, it is important to maintain and ensure data consistency and optimal resource utilization. To summarise the operation of Sqoop:
- Sqoop is used in the Hadoop cluster.
- HDFS receives data imports from RDBMS or NoSQL databases.
- The data is loaded into HDFS after being divided into several forms using mappers.
- Sqoop exports data back into the RDBMS while ensuring the database’s data schema is maintained and followed.
In the modern world, where data needs to be moved from multiple sources and in various forms onto Hadoop and subsequently moved back to relational database systems, Apache Sqoop is a valuable tool. With the release of its most recent versions, Apache Sqoop will only increase due to the growing importance of big data in all business sectors in a world driven by technology.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Prateek is a final year engineering student from Institute of Engineering and Management, Kolkata. He likes to code, study about analytics and Data Science and watch Science Fiction movies. His favourite Sci-Fi franchise is Star Wars. He is also an active Kaggler and part of many student communities in College.