



{kind=link}
This article was published as a part of the Data Science Blogathon.
Introduction
AdaBoost is a boosting algorithm used in data science. It is one of the best-performing and widely used algorithms. In data science interviews, there are lots of questions asked related to the AdaBoost algorithm, whether a working mechanism, the mathematics behind it, or the graphical intuition. In this article, we will cover some of the most asked questions related to the AdaBoost algorithm in data science Interviews.
Read more articles on the AdaBoost algorithm.

Let’s start solving the questions by going through them one by one.
What are Weak Learners and Decision Stumps in Machine Learning?
Weak Learners in Machine Learning are ML algorithms with very low accuracy, almost just above 50% almost all the time. It means it performs poorly in the test dataset and gives unreliable results.
Decision Stumps are a type of decision tree having a maximum depth of one. Here we can clearly understand that decision trees having maximum depth will have very low accuracy; hence it is also the type of weak learner.
Hence the decision stumps are weak learners. They will have only one split geometrically in the dataset, and the split will be based on accuracy.
However, combining multiple weak learners gives higher and more reliable accuracies, so in AdaBoost, multiple weak learners are trained. In the end, we get a strong learner having higher accuracies. In AdaBoost, any algorithm can be selected for being a weak learner. However, in AdaBoost, decision stumps are often chosen for a weak learner.
Choosing decision trees as a weak learner is for getting higher accuracies and to see what the model is doing in the backend while training and when trained.
Why is AdaBoost known as Stagewise Additive Method?
As AdaBoost is a boosting algorithm, it adds the results of multiple weak learners to get the final strong learner. Hence it is known as the additive method.
Here the term stagewise means that in AdaBoost, one weak learner is trained, now whatever the errors that are present in the first stage while training, the first weak learner will pass to the second weak learner while training to avoid the same error in the future stages of training weak learners. Hence it is a Stagewise method.
Here we can see the stagewise addition of weak learners scenario in SdaBoost hence it is known as the Stagewise Addition method.
How does AdaBoost Works? Explain the Core Intuition of the Algorithm with Decision Stumps as Weak Learners.
If decision stumps are the weak learners for the AdaBoost algorithm, then there will be decision trees with max depth one and learning algorithms.
In the first stage, the first weak learner will be taken, and they will split the dataset into two parts by splitting. Here the splitting will be done based on accuracy. Once the first weak learners have done the split, it will have many errors as it was only a decision tree with max depth one.
Now, whatever errors are in the first stage will be passed to the 2nd stage for training the second weak learner. While training the second weak learner, the errors made during the first stage will be taken care of.
So in every stage, the error term will be calculated, which will reduce as we move to the further stages by avoiding the mistakes made by the previous weak learners.
What is the Alpha Term in AdaBoost? How does it work?
In AdaBoost, multiple weak learners are trained to get the strong learner. As a result, hence calculating the error term of every weak learner is essential to know which weak learner is performing best and which is not.
The term Alpha is a parameter that indicates the weight that should be given to a particular weak learner algorithm. If the value of the term Alpha for a particular algorithm is high, that indicates that the model is performing best and the error rate for the same is low.
The formula to calculate the Alpha term is related to the error term, which is as follows.
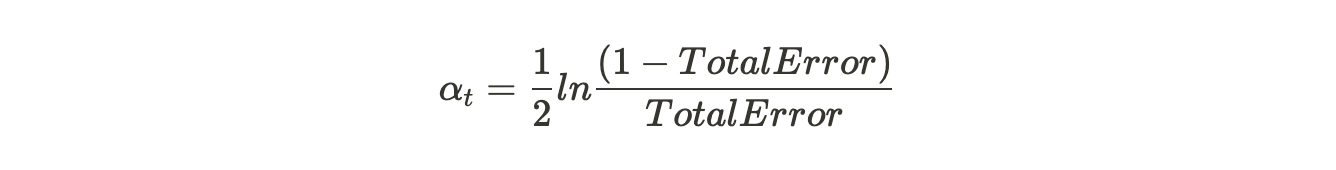
Here in the above image, we can see that the Alpha term is completely dependent on the error rate of the particular weak learner, which means that the more the error less the alpha term value and hence less the weight to the algorithm.
How are Weights Updated in AdaBoost?
In AdaBoost, whatever mistakes the previous weak learners make errors are passed to the next weak learners to avoid the same mistake. Now, to inform the next weak learner about the previous weak learner’s mistake, we will increase the weightage of the samples on which the mistakes (misclassification) are made by performing the upsampling.
Now here, the aim is to increase the weight of misclassified points to update the weight properly.
For Correctly classified points, in which the algorithm makes no mistake, the weight updation formula will be as follows.
 For Incorrectly classified points in which the algorithm makes a mistake, the weight updation formula would be:
For Incorrectly classified points in which the algorithm makes a mistake, the weight updation formula would be:
Conclusion
In this article, the interview questions related to AdaBoost algorithms are discussed with the core intuition, the mathematics, and the core formulas with good reasoning of all questions. Practising these questions would not only help one to develop an idea about the algorithm but will also help one to answer the questions in a better way with mathematical formulations and theoretical knowledge.
Some key takeaways from this article are:
1. AdaBoost is a boosting algorithm known as the stagewise additive method, as it follows weak learners’ addition in subsequent training stages.
2. Most of the time, decision stumps are used as weak learners in AdaBoost for getting an idea about the backend of the algorithm and higher accuracies.
3. In AdaBoost, the error rate is less than the Alpha term, hence less weightage to the weak learner. So in the weight updation, weak learners who make mistakes will be given higher weightage through the Alpha term.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
UG (PE) @PDEU | 25+ Published Articles on Data Science | Data Science Intern & Freelancer | Amazon ML Summer School ’22 | AI/ML/DL Enthusiast | Reach Out @portfolio.parthshukla.live