



{kind=link}
Introduction
Attention models, also known as attention mechanisms, are input processing techniques used in neural networks. They allow the network to focus on different aspects of complex input individually until the entire data set is categorized. The goal is to break down complex tasks into smaller areas of attention that are processed sequentially. This approach is similar to how the human mind solves new problems by breaking them down into simpler tasks and solving them step by step. Attention models can better adapt to specific tasks, optimize their performance, and improve their ability to attend to relevant information.
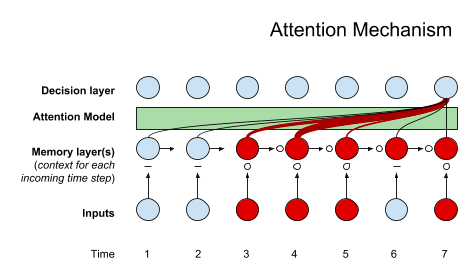
The attention mechanism in NLP is one of the most valuable developments in deep learning in the last decade. The Transformer architecture and natural language processing (NLP) such as Google’s BERT have led to a recent surge of progress.
Learning Objectives
- Understand the need for attention mechanisms in deep learning, how they work, and how they can improve model performance.
- Get to know the types of attention mechanisms and examples of their use.
- Explore your application and the pros and cons of using the attention mechanism.
- Get hands-on experience by following an example of attention implementation.
This article was published as a part of the Data Science Blogathon.
When to Use the Attention Framework?
The attention framework was initially used in encoder-decoder-based neural machine translation systems and computer vision to enhance their performance. Traditional machine translation systems relied on large datasets and complex functions to handle translations, whereas attention mechanisms simplified the process. Instead of translating word by word, attention mechanisms assign fixed-length vectors to capture the overall meaning and sentiment of the input, resulting in more accurate translations. The attention framework is particularly useful when dealing with the limitations of the encoder-decoder translation model. It enables precise alignment and translation of input phrases and sentences.
Unlike encoding the entire input sequence into a single fixed-content vector, the attention mechanism generates a context vector for each output, which allows for more efficient translations. It’s important to note that while attention mechanisms improve the accuracy of translations, they may not always achieve linguistic perfection. However, they effectively capture the intention and general sentiment of the original input. In summary, attention frameworks are a valuable tool for overcoming the limitations of traditional machine translation models and achieving more accurate and context-aware translations.
How do Attention Models Operate?
In broad terms, attention models make use of a function that maps a query and a set of key-value pairs to generate an output. These elements, including the query, keys, values, and final output, are all represented as vectors. The output is calculated by taking a weighted sum of the values, with the weights determined by a compatibility function that evaluates the similarity between the query and the corresponding key.
In practical terms, attention models enable neural networks to approximate the visual attention mechanism employed by humans. Similar to how humans process a new scene, the model focuses intensely on a specific point in an image, providing a “high-resolution” understanding, while perceiving the surrounding areas with less detail, akin to “low-resolution.” As the network gains a better understanding of the scene, it adjusts the focal point accordingly.
Implementing the General Attention Mechanism with NumPy and SciPy
In this section, we will examine the implementation of the general attention mechanism utilizing the Python libraries NumPy and SciPy.
To begin, we define the word embeddings for a sequence of four words. For the sake of simplicity, we will manually define the word embeddings, although in practice, they would be generated by an encoder.
import numpy as np
# encoder representations of four different words
word_1 = np.array([1, 0, 0])
word_2 = np.array([0, 1, 0])
word_3 = np.array([1, 1, 0])
word_4 = np.array([0, 0, 1])Next, we generate the weight matrices that will be multiplied with the word embeddings to obtain the queries, keys, and values. For this example, we randomly generate these weight matrices, but in real scenarios, they would be learned during training.
np.random.seed(42)
W_Q = np.random.randint(3, size=(3, 3))
W_K = np.random.randint(3, size=(3, 3))
W_V = np.random.randint(3, size=(3, 3))We then calculate the query, key, and value vectors for each word by performing matrix multiplications between the word embeddings and the corresponding weight matrices.
query_1 = np.dot(word_1, W_Q)
key_1 = np.dot(word_1, W_K)
value_1 = np.dot(word_1, W_V)
query_2 = np.dot(word_2, W_Q)
key_2 = np.dot(word_2, W_K)
value_2 = np.dot(word_2, W_V)
query_3 = np.dot(word_3, W_Q)
key_3 = np.dot(word_3, W_K)
value_3 = np.dot(word_3, W_V)
query_4 = np.dot(word_4, W_Q)
key_4 = np.dot(word_4, W_K)
value_4 = np.dot(word_4, W_V)Moving on, we score the query vector of the first word against all the key vectors using a dot product operation.
scores = np.array([np.dot(query_1,key_1),
np.dot(query_1,key_2),np.dot(query_1,key_3),np.dot(query_1,key_4)])To generate the weights, we apply the softmax operation to the scores.
weights = np.softmax(scores / np.sqrt(key_1.shape[0]))Finally, we compute the attention output by taking the weighted sum of all the value vectors.
attention=(weights[0]*value_1)+(weights[1]*value_2)+(weights[2]*value_3)+(weights[3]*value_4)
print(attention)For a faster computation, these calculations can be performed in matrix form to obtain the attention output for all four words simultaneously. Here’s an example:
import numpy as np
from scipy.special import softmax
# Representing the encoder representations of four different words
word_1 = np.array([1, 0, 0])
word_2 = np.array([0, 1, 0])
word_3 = np.array([1, 1, 0])
word_4 = np.array([0, 0, 1])
# word embeddings.
words = np.array([word_1, word_2, word_3, word_4])
# Generating the weight matrices.
np. random.seed(42)
W_Q = np. random.randint(3, size=(3, 3))
W_K = np. random.randint(3, size=(3, 3))
W_V = np. random.randint(3, size=(3, 3))
# Generating the queries, keys, and values.
Q = np.dot(words, W_Q)
K = np.dot(words, W_K)
V = np.dot(words, W_V)
# Scoring vector query.
scores = np.dot(Q, K.T)
# Computing the weights by applying a softmax operation.
weights = softmax(scores / np.sqrt(K.shape[1]), axis=1)
# Computing the attention by calculating the weighted sum of the value vectors.
attention = np.dot(weights, V)
print(attention)Types of Attention Models
- Global and Local Attention (local-m, local-p)
- Hard and Soft Attention
- Self-Attention
Global Attention Model
The global attention model considers input from every source state (encoder) and decoder state prior to the current state to compute the output. It takes into account the relationship between the source and target sequences. Below is a diagram illustrating the global attention model.
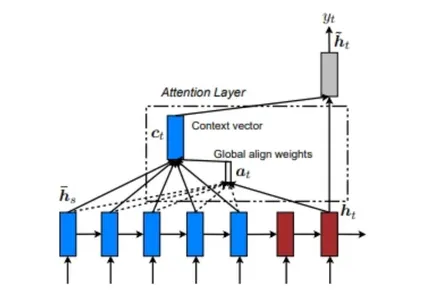
In the global attention model, the alignment weights or attention weights (a<t>) are calculated using each encoder step and the decoder’s previous step (h<t>). The context vector (c<t>) is then calculated by taking the weighted sum of the encoder outputs using the alignment weights. This reference vector is fed to the RNN cell to determine the decoder output.
Local Attention Model
The Local attention model differs from the Global Attention Model in that it only considers a subset of positions from the source (encoder) when calculating the alignment weights (a<t>). Below is a diagram illustrating the Local attention model.

The Local attention model can be understood from the diagram provided. It involves finding a single-aligned position (p<t>) and then using a window of words from the source (encoder) layer, along with (h<t>), to calculate alignment weights and the context vector.
There are two types of Local Attention: Monotonic alignment and Predictive alignment. In monotonic alignment, the position (p<t>) is simply set as “t”, while in predictive alignment, the position (p<t>) is predicted by a predictive model instead of assuming it as “t”.
Hard and Soft Attention
Soft attention and the Global attention model share similarities in their functionality. However, there are distinct differences between hard attention and local attention models. The primary distinction lies in the differentiability property. The local attention model is differentiable at every point, whereas hard attention lacks differentiability. This implies that the local attention model enables gradient-based optimization throughout the model, while hard attention poses challenges for optimization due to non-differentiable operations.
Self-Attention Model
The self-attention model involves establishing relationships between different locations in the same input sequence. In principle, self-attention can use any of the previously mentioned score functions, but the target sequence is replaced with the same input sequence.
Transformer Network
The transformer network is built entirely based on self-attention mechanisms, without the use of recurrent network architecture. The transformer utilizes multi-head self-attention models.

Advantages and Disadvantages of Attention Mechanisms
Attention mechanisms are a powerful tool for improving the performance of deep learning models and have several key advantages. Some of the main advantages of the attention mechanism are:
- Enhanced Accuracy: Attention mechanisms contribute to improving the accuracy of predictions by enabling the model to concentrate on the most pertinent information.
- Increased Efficiency: By processing only the most important data, attention mechanisms enhance the efficiency of the model. This reduces the computational resources required and enhances the scalability of the model.
- Improved Interpretability: The attention weights learned by the model provide valuable insights into the most critical aspects of the data. This helps improve the interpretability of the model and aids in understanding its decision-making process.
However, the attention mechanism also has drawbacks that must be considered. The major drawbacks are:
- Training Difficulty: Training attention mechanisms can be challenging, particularly for large and complex tasks. Learning the attention weights from data often necessitates a substantial amount of data and computational resources.
- Overfitting: Attentional mechanisms can be susceptible to overfitting. While the model may perform well on the training data, it may struggle to generalize effectively to new data. Utilizing regularization techniques can mitigate this problem, but it remains challenging for large and complex tasks.
- Exposure Bias: Attention mechanisms can suffer from exposure bias issues during training. This occurs when the model is trained to generate the output sequence one step at a time but is evaluated by producing the entire sequence at once. This discrepancy can result in poor performance on test data, as the model may struggle to accurately reproduce the complete output sequence.
It is important to acknowledge both the advantages and disadvantages of attention mechanisms in order to make informed decisions regarding their usage in deep learning models.
Tips for Using Attention Frameworks
When implementing an attention framework, consider the following tips to enhance its effectiveness:
- Understand Different Models: Familiarize yourself with the various attention framework models available. Each model has unique features and advantages, so evaluating them will help you choose the most suitable framework for achieving accurate results.
- Provide Consistent Training: Consistent training of the neural network is crucial. Utilize techniques such as back-propagation and reinforcement learning to improve the effectiveness and accuracy of the attention framework. This enables the identification of potential errors in the model and helps refine and enhance its performance.
- Apply Attention Mechanisms to Translation Projects: They are particularly well-suited for language translations. By incorporating attention mechanisms into translation tasks, you can enhance the accuracy of the translations. The attention mechanism assigns appropriate weights to different words, capturing their relevance and improving the overall translation quality.
Application of Attention Mechanisms
Some of the main uses of the attention mechanism are:
- Employ attention mechanisms in natural language processing (NLP) tasks, including machine translation, text summarization, and question answering. These mechanisms play a crucial role in helping models comprehend the meaning of words within a given text and emphasize the most pertinent information.
- Computer vision tasks such as image classification and object recognition also benefit from attention mechanisms. By employing attention, models can identify portions of an image and focus their analysis on specific objects.
- Speech recognition tasks involve transcribing recorded sounds and recognizing voice commands. Attention mechanisms prove valuable in tasks by enabling models to concentrate on segments of the audio signal and accurately recognize spoken words.
- Attentional mechanisms are also useful in music production tasks, such as melody generation and chord progressions. By utilizing attention, models can emphasize essential musical elements and generate coherent and expressive compositions.
Conclusion
Attention mechanisms have gained widespread usage across various domains, including computer vision. However, the majority of research and development in attentional mechanisms has centered around Neural Machine Translation (NMT). Conventional automated translation systems heavily rely on extensive labeled datasets with complex features that map the statistical properties of each word.
In contrast, attentional mechanisms offer a simpler approach for NMT. In this approach, we encode the meaning of a sentence into a fixed-length vector and utilize it to generate a translation. Rather than translating word by word, the attention mechanism focuses on capturing the overall sentiment or high-level information of a sentence. By adopting this learning-driven approach, NMT systems not only achieve significant accuracy improvements but also benefit from easier construction and faster training processes.
Key Takeaways
- The attention mechanism is a neural network layer that integrates into deep learning models.
- It enables the model to focus on specific parts of the input by assigning weights based on their relevance to the task.
- Attention mechanisms have proven to be highly effective in various tasks, including machine translation, image captioning, and speech recognition.
- They are particularly advantageous when dealing with long input sequences, as they allow the model to selectively focus on the most relevant parts.
- Attention mechanisms can enhance model interpretability by visually representing the parts of the input the model is attending to.
Frequently Asked Questions
A. The attention mechanism is a layer added to deep learning models that assigns weights to different parts of the data, enabling the model to focus attention on specific parts.
A. Global attention considers all available data, while local attention focuses on a specific subset of the overall data.
A. In machine translation, the attention mechanism selectively adjusts and focuses on relevant parts of the source sentence during the translation process, assigning more weight to important words and phrases.
A. The transformer is a neural network architecture that heavily relies on attention mechanisms. It uses self-attention to capture dependencies between words in input sequences and can model long-range dependencies more effectively than traditional recurrent neural networks.
A. One example is the “show, attend, and tell” model used in image description tasks. It utilizes an attention mechanism to dynamically focus on different regions of the image while generating relevant descriptive captions.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.