



{kind=link}
Introduction
Bayesian Networks or statistics form an integral part of many statistical learning approaches. It involves using new evidence to modify the prior probabilities of an event. It uses conditional probabilities to improve the prior probabilities, which results in posterior probabilities. In simple terms, suppose you want to ascertain the probability of whether your friends will agree to play a match of badminton given certain weather conditions. Similarly, Bayes Inference forms an integral part of Bayesian Networks as a tool for modeling uncertain beliefs. In this article, we explore one type of Bayesian Networks application, a Probabilistic Neural Network(PNN), and learn in-depth about its implementation through a practical example.
Learning Objectives
- Understanding PNN and its related concepts
- Concepts of Parzen Window or KDE(kernel density estimate)
- Kernel functions as non-parametric method to a certain data distribution through an example.
- Implementation of PNN using python for classification tasks
This article was published as a part of the Data Science Blogathon.
Table of Contents
What is Bayesian Network?
A Bayesian Network uses the Bayes theorem to operate and provides a simple way of using the Bayes Theorem to solve complex problems. In contrast to other methodologies where probabilities are determined based on historical data, this theorem involves the study of probability or belief in a result.
Although the probability distributions for the random variables (nodes) and the connections between the random variables (edges), which are both described subjectively, are not perfectly Bayesian by definition, the model can be considered to embody the “belief” about a complex domain.
In contrast to the frequentist method, where probabilities are solely dependent on the previous occurrence of the event, bayesian probability involves the study of subjective probabilities or belief in an outcome.
A Bayesian network captures the joint probabilities of the events the model represents.
What is Probabilistic Neural Network(PNN)?
A Probabilistic Neural Network (PNN) is a type of feed-forward ANN in which the computation-intensive backpropagation is not used It’s a classifier that can estimate the pdf of a given set of data. PNNs are a scalable alternative to traditional backpropagation neural networks in classification and pattern recognition applications. When used to solve problems on classification, the networks use probability theory to reduce the number of incorrect classifications.

Source: Paper by Specht 1990
The PNN aims to build an ANN using methods from probability theory like Bayesian classification & other estimators for pdf. The application of kernel functions for discriminant analysis and pattern recognition gave rise to the widespread use of PNN.
Concepts of Probabilistic Neural Networks (PNN)
An accepted norm for decision rules or strategies used to classify patterns is that they do so in a way that minimizes the “expected risk.” Such strategies are called “Bayes strategies” and can be applied to problems containing any number of categories/classes.
In the PNN method, a Parzen window and a non-parametric function approximate each class’s parent probability distribution function (PDF). The Bayes’ rule is then applied to assign the class with the highest posterior probability to new input data. The PDF of each class is used to estimate the class probability of fresh input data. This approach reduces the likelihood of misclassification. This Kernel density estimation(KDE) is analogous to histograms, where we calculate the sum of a gaussian bell computed around every data point. A KDE is a sum of different parametric distributions produced by each observation point given some parameters. We are just calculating the probability of data having a specific value denoted by the x-axis of the KDE plot. Also, the overall area under the KDE plot sums up to 1. Let us understand this using an example.
By replacing the sigmoid activation function, often used in neural networks, with an exponential function, a probabilistic neural network ( PNN) that can compute nonlinear decision boundaries that approach the Bayes optimal is formed.
Parzen Window
The Parzen-Rosenblatt window method, also known as the Parzen-window method, is a well-liked non-parametric approach for estimating a probability density function p(x) for a particular point p(x) from a sample p(xn), which does not necessitate any prior knowledge or underlying distribution assumptions. This process is also known as kernel density estimation.
Estimating the class-conditional density (“likelihoods”) p(x|wi) in classification using the training dataset where p(x) refers to a multi-dimensional sample that belongs to a particular class wi is a prominent application of the Parzen-window technique.
For detailed description of Parzen windows, refer to this link.
Understanding Kernel Density Estimation
Kernel density estimation(KDE) is analogous to histograms, where we calculate the sum of a gaussian bell computed around every data point. A KDE is a sum of different parametric distributions produced by each observation point given some parameters. We are just calculating the probability of data having a specific value denoted by the x-axis of the KDE plot. Also, the overall area under the KDE plot sums up to 1. Let us understand this using an example.


Now we will see a distribution of the “sepal length” feature of Iris Dataset and its corresponding kde.

Now using the above-mentioned kernel functions, we will try to build kernel density estimate for sepal length for different values of smoothing parameter(bandwidth).
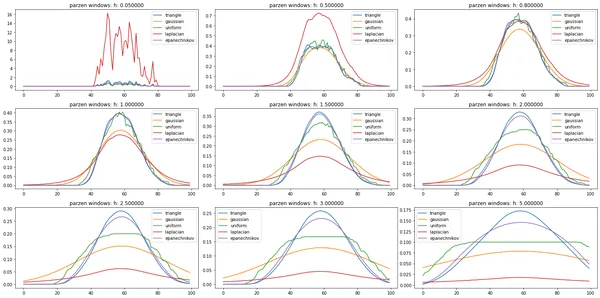
As we can see, triangle, gaussian, and epanechnikov give better approximations at 0.8 and 1.0 bandwidth values. As we increase, the bandwidth curve becomes more smooth and flattened, and if we decrease, the bandwidth curve becomes more zigzag and sharp-edged. Thus, bandwidth in PNN can be considered similar to the k value in KNN.
KNN and Parzen Windows
Parzen windows can be considered a k-Nearest Neighbour (KNN) technique generalization. Rather than choosing k nearest neighbors of a test point and labeling it with the weighted majority of its neighbors’ votes, one can consider all observations in the voting scheme and assign their weights using the kernel function.
In the Parzen windows estimation, the interval’s length is fixed, but the number of samples that fall within an interval changes over time. For the k nearest neighbor density estimate, the opposite is true.
Architecture of PNN
The below image describes the architecture of PNN, which consists of four significant layers, and they are:
- Input Layer
- Pattern Layer
- Summation Layer
- Output Layer
Let us now try to understand each layer one by one.

Input Layer
In this layer, each feature variable or predictor of the input sample is represented by a neuron in the input layer. For example, if you have a sample with four predictors, the input layer should have four neurons. If the predictor is a categorical variable with N categories, then we convert it to an N-1 dummy and use N-1 neurons. We also normalize the data using suitable scalers. The input neurons then send the values to each of the neurons in the hidden layer, the next pattern layer.
Pattern Layer
This layer has one neuron for each observation in the training data set. A hidden neuron first determines the Euclidean distance between the test observation and the pattern neuron to apply the radial basis kernel function. For the Gaussian kernel, the multivariate estimates can be expressed as,

where,
For each neuron “i” in the pattern layer, we find the Euclidean distance between the test input and the pattern.
Sigma = Smoothing parameter
d= each feature vector size
x = test input vector
xi = pattern ith neuron vector
Summation Layer
This layer consists of 1 neuron for each class or category of the target variable. Suppose we have three classes. Then we will have three neurons in this layer. Each Type of pattern layer neuron is joined to its corresponding Type neuron in the summation layer. Neurons in this layer sum and average the values of pattern layer neurons attached to it. vi is the output of each neuron here.

Output Layer
The output layer predicts the target category by comparing the weighted votes accumulated in the pattern layer for each target category.
Algorithm of PNN
The following are the high-level steps of the PNN algorithm:
1. Standardize the input features and feed them to the input layer.
2. In the pattern Layer, each training observation forms one neuron and kernel with a specific smoothing parameter/bandwidth value used as an activation function. For each input observation, we find the kernel function value K(x,y) from each pattern neuron, i.e., training observation.
3. Then sum up the K(x,y) values for patterns in the same class in the summation layer. Also, take an average of these values. Thus, the number of outputs for this layer equals the number of classes in the “target” variable.
4. The final layer output layer compares the output of the preceding layer, i.e., the summation layer. It checks the maximum output for which class label is based on average K(x,y) values for each class in the preceding layer. The predicted class label is assigned to input observation with the highest value of average K(x,y).
Code Example on Iris Dataset
The following is a python code example of implementing PNN on the iris dataset and predicting labels for the test set. We will go through each step presented in the algorithm, so open your notebook and start coding!
Step 1 – Load the dataset and import libraries
Importing important libraries
from sklearn.datasets import load_iris
import numpy
import pandas
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score,f1_scoreLoading iris dataset from sklearn.datasets.
iris = load_iris();
data = pd.DataFrame(data= np.c_[iris['data'], iris['target']],
columns= iris['feature_names'] + ['target']);
data.head(5)

Step 2- Build Input Layer
We standardize the dataset and split it into test and train
# Standardise input and split into train and test sets
X = data.drop(columns='target',axis=1);
Y = data[['target']]
scaler = StandardScaler();
X_scaled = scaler.fit_transform(X);
X_train,X_test,Y_train,Y_test = train_test_split(X,Y,train_size=0.8,random_state=12);
Step 3 – Construct Kernel functions
uniform = lambda x,b: (np.abs(x/b) <= 1) and 1/2 or 0
triangle = lambda x,b: (np.abs(x/b) <= 1) and (1 - np.abs(x/b)) or 0
gaussian = lambda x,b: (1.0/np.sqrt(2*np.pi))* np.exp(-.5*(x/b)**2)
laplacian = lambda x,b: (1.0/(2*b))* np.exp(-np.abs(x/b))
epanechnikov = lambda x,b: (np.abs(x/b)<=1) and ((3/4)*(1-(x/b)**2)) or 0
Step 4 – Build Pattern Layer
def pattern_layer(inp,kernel,sigma):
k_values=[];
for i,p in enumerate(X_train.values):
edis = np.linalg.norm(p-inp); #find eucliden distance
k = kernel(edis,sigma); #pass values of euclidean dist and
#smoothing parameter to kernel function
k_values.append(k);
return k_values;
Step 5 – Build Summation Layer
def summation_layer(k_values,Y_train,class_counts):
# Summing up each value for each class and then averaging
summed =[0,0,0];
for i,c in enumerate(class_counts):
val = (Y_train['target']==class_counts.index[i]).values;
k_values = np.array(k_values);
summed[i] = np.sum(k_values[val]);
avg_sum = list(summed/Y_train.value_counts());
return avg_sumStep 6 – Build Output Layer
def output_layer(avg_sum,class_counts):
maxv = max(avg_sum);
label = class_counts.index[avg_sum.index(maxv)][0];
return labelStep 7- Bringing together all layers under PNN Model
## Bringing all layers together under PNN function
def pnn(X_train,Y_train,X_test,kernel,sigma):
# Initialising variables
class_counts = Y_train.value_counts()
labels=[];
#Passing each sample observation
for s in X_test.values:
k_values = pattern_layer(s,kernel,sigma);
avg_sum = summation_layer(k_values,Y_train,class_counts);
label = output_layer(avg_sum,class_counts);
labels.append(label);
print('Labels Generated for bandwidth:',sigma);
return labels;
Step 8 – Generating Predictions
#Candidate Kernels
kernels = ['Gaussian','Triangular','Epanechnikov'];
sigmas = [0.05,0.5,0.8,1,1.2];
results = pd.DataFrame(columns=['Kernel','Smoothing Param','Accuracy','F1-Score']);
for k in kernels:
if k=='Gaussian':
k_func = gaussian;
elif k=='Triangular':
k_func = triangle;
else:
k_func = epanechnikov;
for b in sigmas:
pred = pnn(X_train,Y_train,X_test,k_func,b);
accuracy = accuracy_score(Y_test.values,pred);
f1= f1_score(Y_test.values,pred,average='weighted')
results.loc[len(results.index)]=[k,b,accuracy,f1];

Step 9 – Comparing scores of different kernels at different smoothing parameter values
plt.rcParams['figure.figsize'] = [10, 5]
plt.subplot(121)
sns.lineplot(y=results['Accuracy'],x=results['Smoothing Param'],hue=results['Kernel']);
plt.title('Accuracy for Different Kernels',loc='right');
plt.subplot(122)
sns.lineplot(y=results['F1-Score'],x=results['Smoothing Param'],hue=results['Kernel']);
plt.title('F1-Score for Different Kernels',loc='left');
plt.show()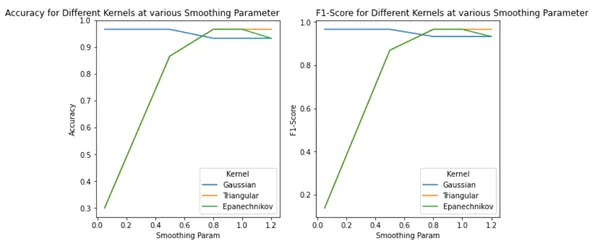
Conclusion
Thus, we saw using PNN; we get high accuracy and f1 score with based on optimal kernel and bandwidth selection. Also, the best-performing kernels were Gaussian, Triangular, and Epanechnikov kernels. The following are the key takeaways:
1. PNN enables us to build fast and less complex networks involving few layers.
2. We saw various combinations of kernel functions can be employed, and the optimal kernels can be chosen based on performance metrics.
3. PNN is less time-consuming as it does not involve complex computations.
4. PNN can capture complex decision boundaries due to nonlinearity introduced by kernels which are present as activation functions.
Thus, PNN has wide scope and implementations in various domains.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.