



{kind=link}
This article was published as a part of the Data Science Blogathon.
Introduction
Stacking is one of the most used and best-performing ensemble techniques used in the field of machine learning. It is very similar to the voting ensembles but also assigns the weights to the machine learning algorithms, where two layers of models are present: ground models and meta models. Due to this, Stacking tends to perform best of all the other ensemble techniques used in machine learning.
In this article, we will be talking about stacking ensemble techniques. We will start by talking about the core intuition of these techniques, followed by the mathematics and different approach behind their working mechanism. We will develop the code for these techniques to apply these algorithms to data, concluding with the key takeaways from this strategy.
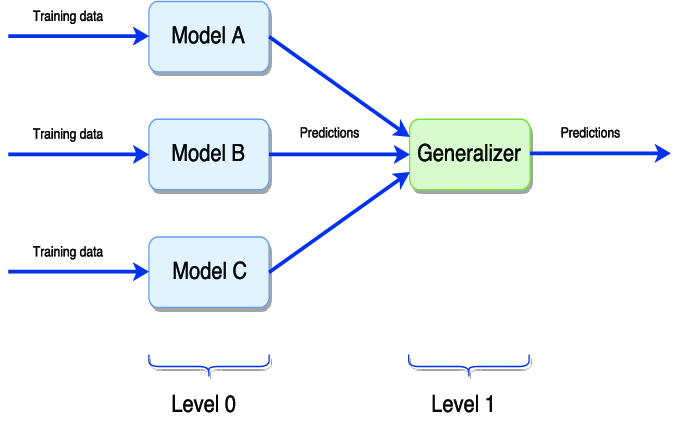
The Relation Between Voting Ensembles and Stacking
We mentioned above that Stacking is very similar to voting. In a voting ensemble, multiple machine-learning algorithms perform the same task. Here, we train multiple machine learning algorithms on the same data, and the results from each model are taken once you’ve had training. The final output is the mean of the ground models results if the regression problem or the most frequent category of classification problem, where all the results from ground models will have the same weightage.
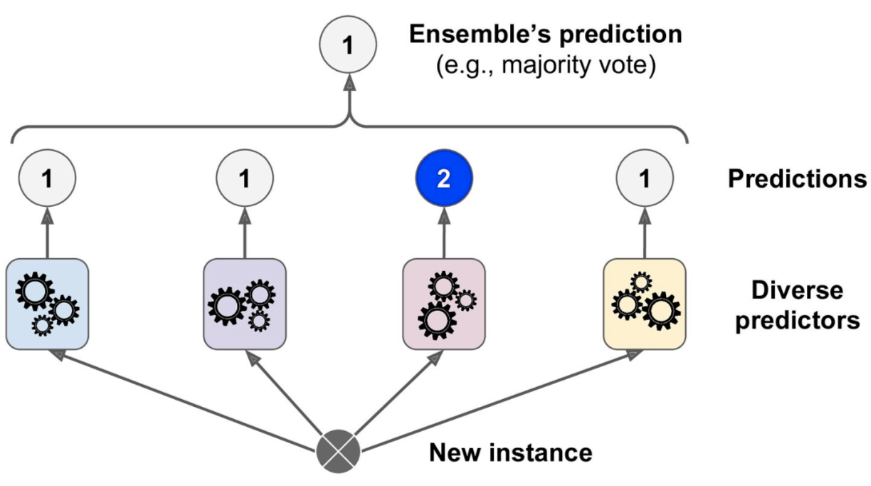
In stacking, the same thing takes place. Just a new layer of the model is taken into the interpretation. In Stacking, multiple machine learning algorithms are used as the ground models, but here there is also a further layer of the model called meta models. This model will assign different weights to the ground models, unlike voting ensembles, and then the prediction task is performed in stacking.
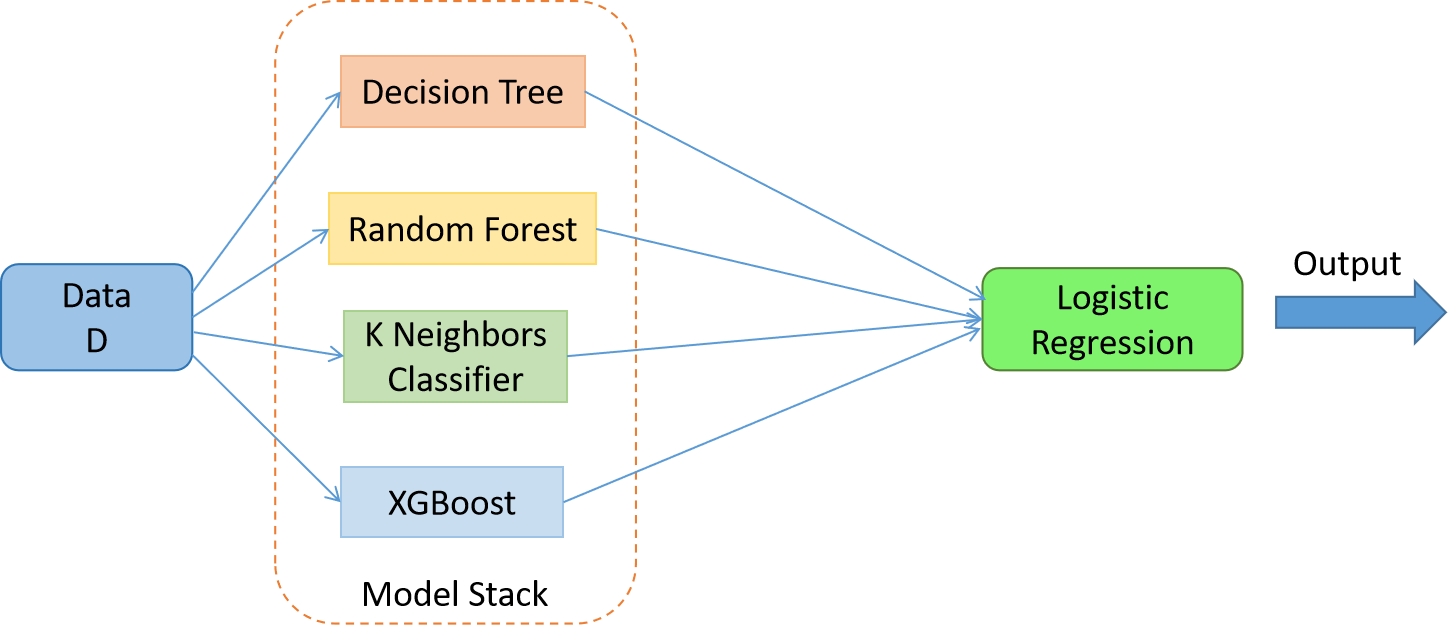
Suppose we have dataset D, and we have three machine learning ground models: Decision Tree, Random Forest, KNN, and the XGBoost, and the meta-model in the second layer is the Logistic Regression. Now we will feed the dataset D to every respective ground model. We will train the ground models on the same dataset, and one trained will be able to predict for our test dataset. Once we introduce the ground models, we will take the prediction data of every ground model and use that data to train the meta-model Decision tree. So here, the training data for the decision tree will be different. Once we introduce the meta-models, it will assign the weights to the ground models, and the output from the meta-models will be considered the final output of the stacking algorithm.
The Problem with Stacking Algorithms
As we know, in Stacking, ground models are trained on the dataset, where we use the outputs of the ground models on the test data as the training data for the meta-model. Here we can see the same data is used multiple times by the model, meaning that the output data from ground models are already open to the whole model and are again used for the training of the meta-model. So obviously, there will be a case of over-fitting where the model will perform very well on the training data, but it will perform poorly in the i=unknown or testing data.
So here, in this case, we have tackled this problem, either we can validate the data, meaning that we will not show some samples of the data to the ground models, or we use special techniques like KNN sampling to perform the task. In stacking, we use the K-fold approach for handling these problems related to overfitting.
K Fold Approach: Stacking
As we know, there Is a potential overfitting in these ensembles, and we can use the K-fold approach to tackle this problem. This approach is also called Stacking or classical Stacking. Let’s try to understand the K fold sampling with an example.
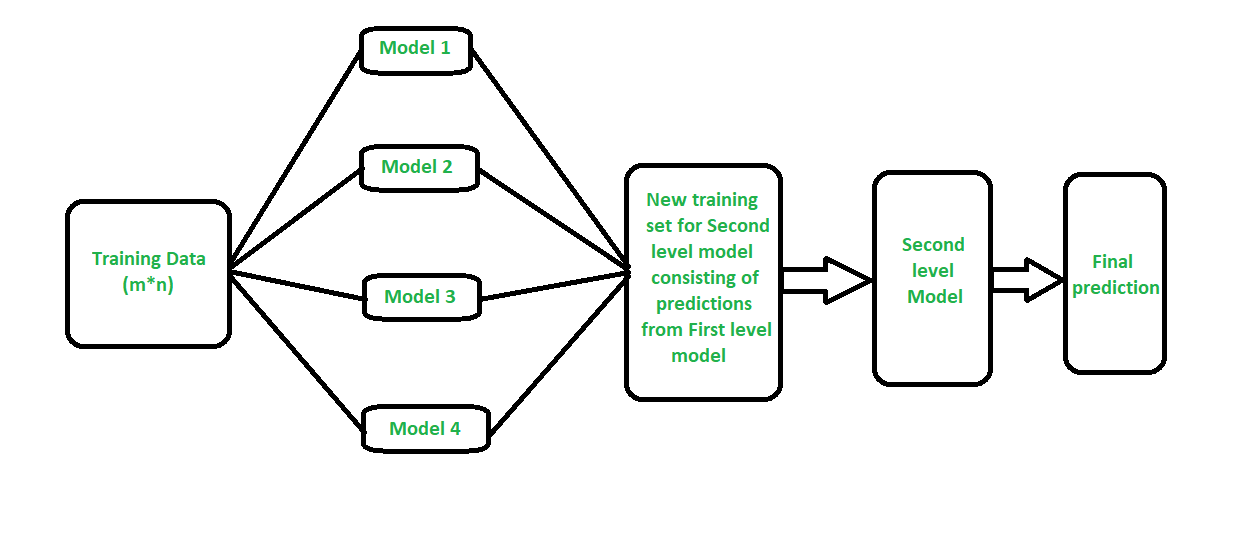
Suppose we have a regression dataset where the output column is in the form of a numerical value. So in the K fold sampling, the step would be to split the dataset into training and testing sets. So here, using the train_test_split module, the dataset can be easily divided into the training and testing set. Suppose we have a split of 80 – 20 in our dataset.
In the second step, we decide the value of K, which is the value known as the equal split of the data. Generally, we take the value of K as 5, which means that we will split the dataset into five parts.
In the 3rd step, we will train the ground models one by one on the dataset; since we have five equal splits of the dataset, we will use four splits as the training set, and the last split will be utilized as the testing set. Once trained, we will record the prediction on the earlier split for all the algorithms. The same thing will repeat, and we will record the output of the 1st, 2nd, 3rd, and 4th ground models.
In the 4th step, where we will have the prediction dataset for all the ground models, we will use that data as the training set for the meta-models. Once the meta-model is trained, now the training of the ground models, the same dataset will not be used. Instead, the training data from step 1 will be used as the training set for the ground models.
So here, we train the meta-models first, and then the ground models are introduced. Also, the problem of data leakage is solved where the meta-models are ground models trained individually, and the problem of overfitting will not occur.
Stacking: Code Example
Applying Stacking on data available is very simple; libraries like StackingClassifer and StackingRegresor are available in Scikit-Learn.
Importing the required libraries:
from sklearn.ensemble import RandomForestClassifier from sklearn.neighbors import KNeighborsClassifier from sklearn.linear_model import LogisticRegression from sklearn.ensemble import GradientBoostingClassifier from sklearn.ensemble import StackingClassifier
Creating the estimators’ list:
estimators = [
('rf', RandomForestClassifier(n_estimators=10, random_state=42)),
('knn', KNeighborsClassifier(n_neighbors=10)),
('gbdt',GradientBoostingClassifier())
]
Applying Stacking:
clf = StackingClassifier(
estimators=estimators,
final_estimator=LogisticRegression(),
cv=11
)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
from sklearn.metrics import accuracy_score
accuracy_score(y_test,y_pred)
Conclusion
In this article, we discussed the famous ensemble approach, stacking, and its core intuition if it’s with the actual example, the working mechanism, and the code example. Knowing about this strategy will help one understand the stacking algorithms better and the working of the data sampling behind them. It will also help one answer the interview question about stacking very efficiently.
Some Key Takeaways from this article are:
1. Stacking is a well-known ensemble approach that uses two layers of machine learning algorithms to predict the samples.
2. In Stacking, the meta-model is trained first on the output of the ground models.
3. Ground models in Stacking are trained two times on different datasets, the first training is to get outputs for validation data to feed it to the meta-model, and the second training is for the ground models themselves.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
UG (PE) @PDEU | 25+ Published Articles on Data Science | Data Science Intern & Freelancer | Amazon ML Summer School ’22 | AI/ML/DL Enthusiast | Reach Out @portfolio.parthshukla.live