



{kind=link}
This article was published as a part of the Data Science Blogathon.
Introduction
Every Data Science enthusiast’s journey goes through one of the most classical data problems – Frequent Itemset Mining, also sometimes referred to as Association Rule Mining or Market Basket Analysis.
Frequent Itemset Mining is one of the most widely used methods for Market Basket Analysis. The goal is to find patterns/regularities in customers’ shopping behavior. Many supermarkets use the customers’ historical purchase data to lure them into buying more products and maximize their sales.
One classic example could be Amazon’s recommender system, which suggests what a user is likely to buy along with an item ‘X’.
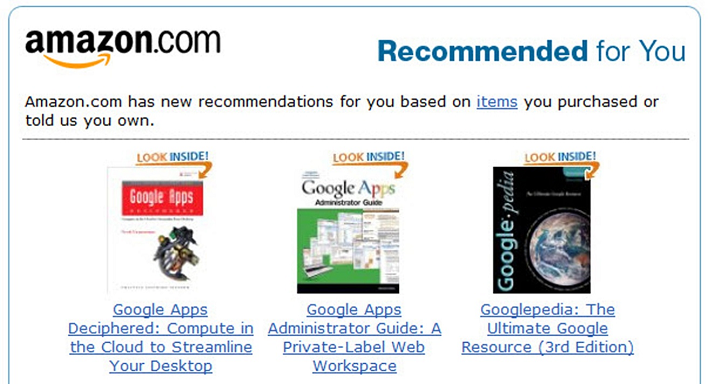
[ source: https://www.mageplaza.com/blog/product-recomendation-how-amazon-succeeds-with-it.html]
Today, let’s try to solve the Frequent Itemset Mining using the MapReduce algorithm on Hadoop.
So if you are excited to be a part of this journey, let’s go.
Things we Need to Pack
1. Oracle VM VirtualBox:
We will be using the VirtualBox virtual machine by Oracle for hands-on implementation of Frequent Itemset Mining.
2. Cloudera Quickstart VM:
Cloudera Quickstart VM is a virtual machine image with Hadoop pre-installed. This is to avoid the unnecessary hassle of installing Hadoop, as sometimes, things might go wrong if not properly installed.
Okay, so before we start, let’s briefly introduce Frequent Itemset Mining and MapReduce.
The Frequent Itemset Mining Algorithm
Frequent Itemset Mining, which is also termed “Association Rules Mining”, is an algorithm that looks for the frequent items bought in a dataset of items. As the word suggests, it makes interesting associations/deductions about the items that are likely to be bought together.
For example, you go to the supermarket near your home to buy some commodities.

Shopping List
Source: https://www.pinterest.com/pin/picture-grocery-list-mobile-or-printed–412712753335867002/]
If you buy milk and bread, then it is more likely that you will also buy butter and cheese. This association of the data items {milk + bread} → {butter, cheese} is defined by some rules. These are called transactions.
Support: Support is the parameter that quantifies the amount of interestingness. So, if the support is 20%, then 20% of the transactions will follow that rule.
If A and B are two different items, then the Support for item B, when item A is bought, is the union of the support counts of both the items.
Support(A → B) = Support_count(A U B)
Confidence: Confidence is the parameter that tells us the confidence/probability of customers who bought items A and B together. So, if the confidence is 40%, then 40% of the customers who bought milk and bread also bought butter and cheese.
Confidence(A → B) = [Support_count(A U B)] / Support_count(A)
Now that we have covered the basics let’s move to the next important part of this blog.
MapReduce
MapReduce is a framework that is used to process big data on parallel clusters of hardware in an efficient manner.
As the name suggests, MapReduce consists of two stages –
1. Map stage:
In the Map stage, the mapper job processes the input data. This input data is stored on Hadoop File System (HDFS). The mapper function basically ‘maps’ the input file line-by-line and process small chunks of the data.
2. Reduce stage:
The Reduce stage is a combination of shuffling and reducing. The output of the map stage becomes the input of the reduce stage. The output of the Reduce stage is the final output stored on HDFS.
MapReduce Architecture
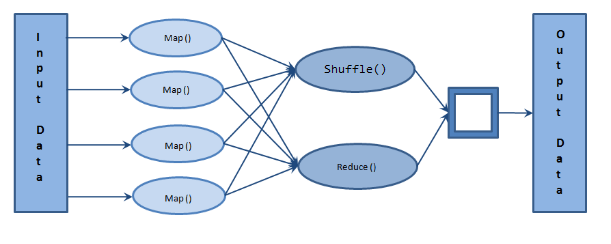
[source: https://beyondcorner.com/wp-content/uploads/2017/11/Apache-Hadoop-MapReduce-Architecture.png]
Some common terminologies used in MapReduce:
• Payload: Applications that use MapReduce
• Mapper: The mapper function maps the input pairs to an intermediary pair.
• NameNode: The node that keeps metadata such as no. of active clusters, HDFS, etc.
• DataNode: The node where data is stored for processing.
• MasterNode: The node where JobTracker runs and accepts jobs from the clients.
• SlaveNode: The node where the actual MapReduce job runs.
• JobTracker: Schedules jobs and tracks the assigned jobs to TaskTracker.
• TaskTracker: Tracks the task and reports the status to JobTracker.
• Job: A program that requires MapReduce to be executed.
• Task: A task is a slice (small part) of a job.
Hands-on: MapReduce for Frequent Itemset Mining on Hadoop
Step 1: Open Cloudera Quickstart VM

Cloudera Quickstart VM Desktop
[source: Screenshot of Cloudera Quickstart VM installed on my local machine]
Step 2: Clone the following repository on your local machine
www.github.com/NSTiwari/Hadoop-MapReduce-Programs
You’ll find the Frequent-Itemset-Mining folder along with some other folders. The
Frequent-Itemset-Mining directory contains three files –
- frequent_itemset_data.txt – The text data file that contains transactions (input).
- frequent_itemset_mapper.py – The mapper file for Frequent Itemset Mining.
- frequent_itemset_reducer.py – The reducer file for Frequent Itemset Mining.
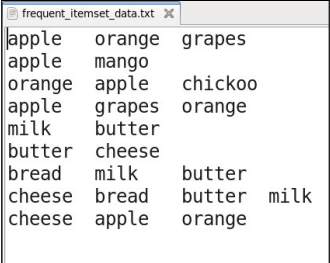
[source: Screenshot of my local machine]
ls

[ Screenshot of Cloudera Quickstart VM on my local machine]
All three files are present.
Step 3: Test the MapReduce program locally
cat frequent_itemset_data.txt | python frequent_itemset_mapper.py | sort
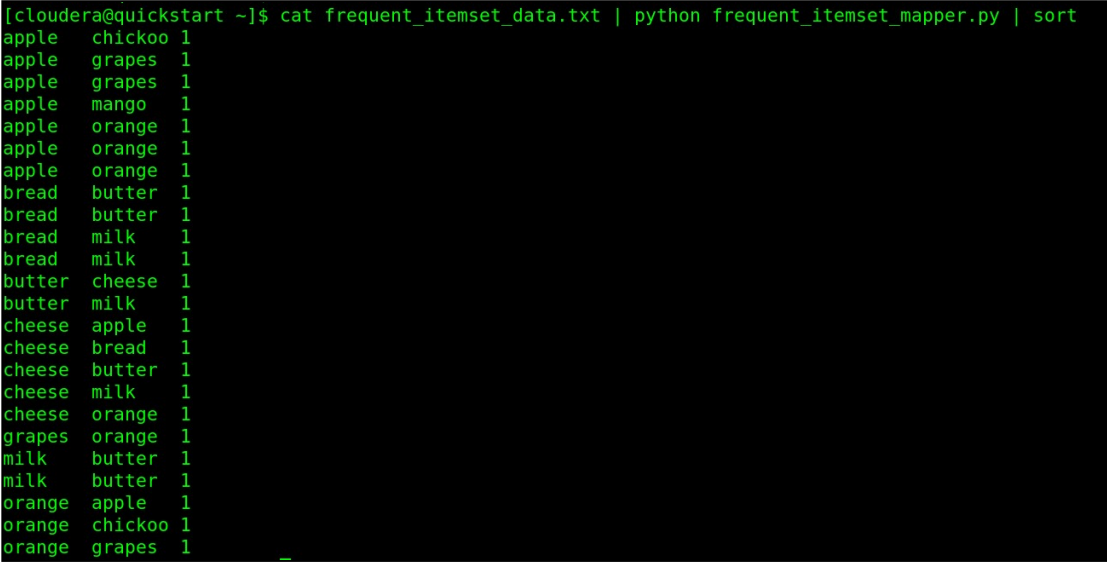
[source: Screenshot of Cloudera Quickstart VM on my local machine]
cat frequent_itemset_data.txt | python frequent_itemset_mapper.py | sort | python frequent_itemset_reducer.py

MapReduce program run locally
[source: Screenshot of Cloudera Quickstart VM on my local machine]
Step 4: Create a directory on HDFS
sudo -u hdfs hadoop fs -mkdir /frequent_itemset
hdfs dfs -ls /
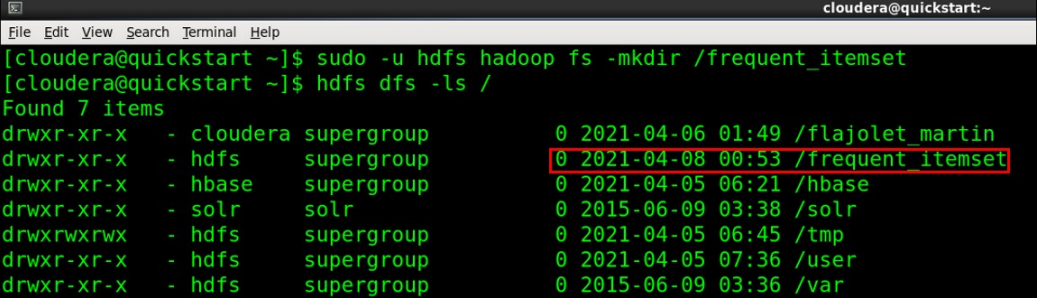
[Image source: Screenshot of Cloudera Quickstart VM on my local machine]
Step 5: Copy input file to HDFS
sudo -u hdfs hadoop fs -put /home/cloudera/frequent_itemset_data.txt /frequent_itemset
hdfs dfs -ls /frequent_itemset

[Image source: Screenshot of Cloudera Quickstart VM on my local machine]
Step 6: Configure permissions to run MapReduce for Frequent Itemset Mining on Hadoop
chmod 777 frequent_itemset_mapper.py frequent_itemset_reducer.py
sudo -u hdfs hadoop fs -chown cloudera /frequent_itemset

[Image source: Screenshot of Cloudera Quickstart VM on my local machine]
All the required permissions have now been configured. Let’s now execute Hadoop streaming.
Step 7: Run MapReduce on Hadoop
Run the following command on terminal.
hadoop -jar /home/cloudera/hadoop-streaming-2.7.3.jar
> -input /frequent_itemset/frequent_data.txt
> -output /frequent_itemset/output
> -mapper /home/cloudera/frequent_map.py
> -reducer /home/cloudera/frequent_reduce.py
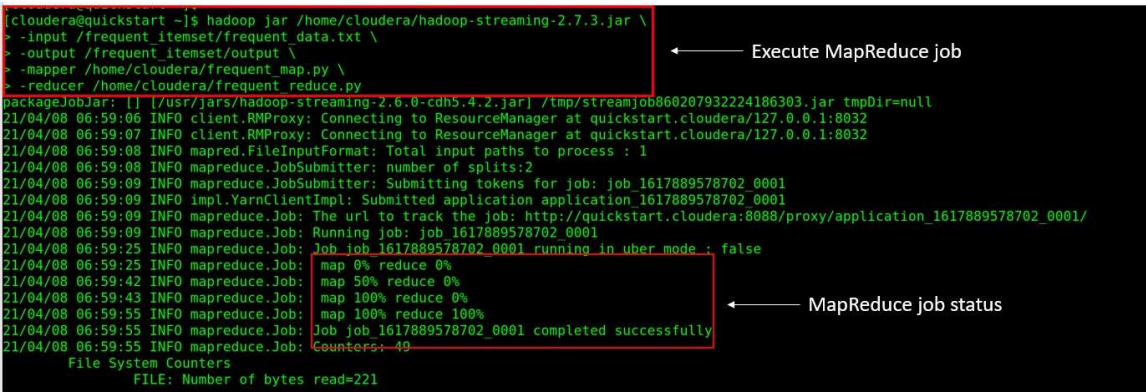
[ source: Screenshot of Cloudera Quickstart VM on my local machine]
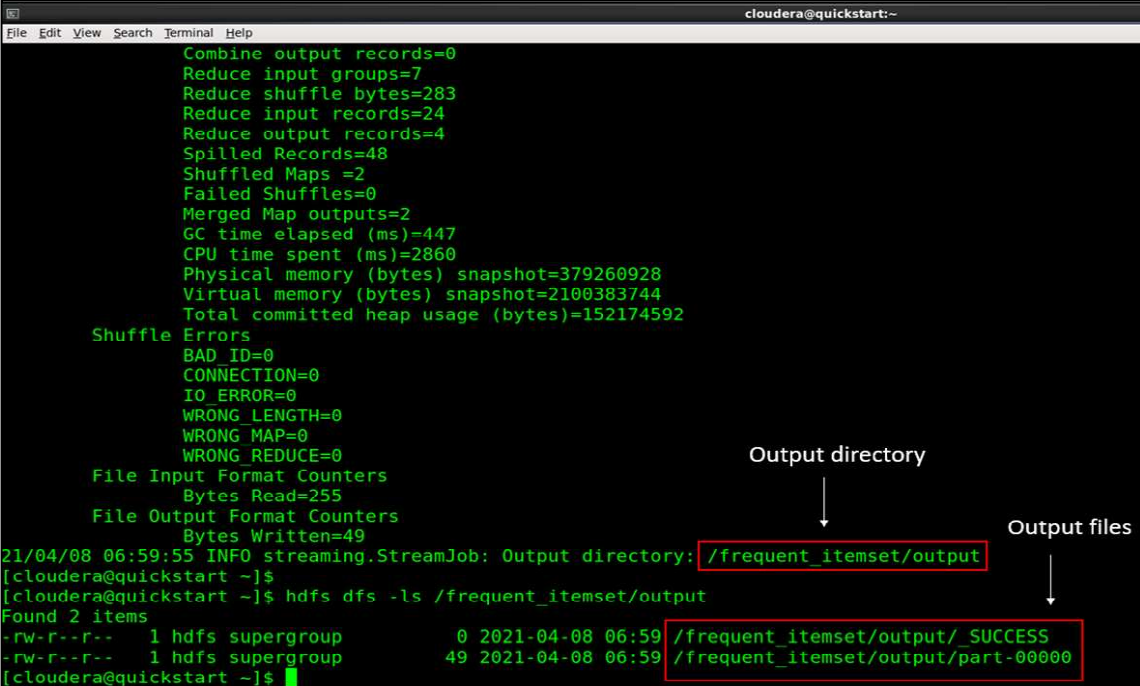
[source: Screenshot of Cloudera Quickstart VM on my local machine]
Step 8: Read the MapReduce output
hdfs dfs -cat /frequent_itemset/output/part-00000
And finally, here is the output of our entire MapReduce program run on Hadoop.

[source: Screenshot of Cloudera Quickstart VM on my local machine]
As we can see, the associating rule after running the MapReduce program on Hadoop for the input dataset suggests a customer is likely to buy:
- An orange if bought an apple.
- Butter if bought bread.
- Milk is purchased bread.
- Butter if purchased milk.
Conclusion
So, this concludes the article here. To quickly summarize this blog, we learned –
- Introduction to Frequent Itemset Mining
- A real-world example of the Frequent Itemset Mining algorithm – Amazon’s Recommender System
- The Frequent Itemset Mining algorithm: Explained
- Parameters of the Frequent Itemset Mining algorithm: Support and Confidence
- Introduction to the MapReduce algorithm
- The MapReduce Architecture
- Common terminologies used in MapReduce
- Hands-on practical on Frequent Itemset Mining using MapReduce on Hadoop.
If you liked my article and would like to talk more on ML topics, feel free to connect with me on my LinkedIn profile. Until next time. 🙂
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.