



{kind=link}
This article was published as a part of the Data Science Blogathon.
Introduction
Natural Language Processing (NLP) can help you to understand any text’s sentiments. This is helpful for people to understand the emotions and the type of text they are looking over. Negative and Positive comments can be easily differentiated. NLP wanted to make machines understand the text or comment the same way humans can. There would be situations where comments would be lefthanded compliment means the comment would be positive. Still, its intention would be the opposite. Machines need to find out the exact sentiment of these comments and how humans can figure it out.
We need to make machines understand text, and this can’t be achieved by just applying machine learning algorithms. Devices can usually comprehend binary representations or numeric data, so we need to find a way to make our text numeric so that machines can understand things. We must clean and convert data to required formats to make machines understand the texts.
Before Preprocessing steps, we would look into some terminologies used in NLP:
Terminologies in NLP
Corpus
A corpus is a large, structured set of machine-readable texts produced in a natural communicative setting. If we have a bunch of sentences in our dataset, all the sentences will come into the corpus, and the corpus would be like a paragraph with a mixture of sentences.
Corpus is a collection of Documents.
Documents
It is a unique text different from the corpus. If we have 100 sentences, each sentence is a document. Mathematical Representation of Documents is Vector.
Vocabulary
Vocabulary is unique words involved in the corpus.
E.g. Sentence1 = He is a good boy
Sentence2 = He is a Bad boy
Vocabulary = [He, is, good, boy, Bad]
Words
All the words in the corpus.
E.g. Sentence1 = He is a good boy
Sentence2 = He is a Bad boy
Vocabulary = [He, is, good, boy, He, is, Bad, Boy]
Text Preprocessing Steps
Removal of Noise, URLs, Hashtag and User-mentions
We may have URLs, hashtags, and tags in our texts as they are scrapped from the internet. All these may create noise. So we need to remove them from our text.
Python Code:
Lowercasing:
In Corpus, there might be the same words, where both the words are added to vocabulary as the words are differentiated with capital and small letters involved in the words, But we need to add the word only once as both indicate the same meaning. To escape this situation, we lowercase all the words involved in the corpus.
data['text'].str.lower()
Replacing Emoticons and Emojis:
Emoticons and emojis can be displayed incorrectly, Sometimes, it’s appropriate to remove emoticons and emojis, but in a sentiment analysis task instead of instance, they can be instrumental. In this situation, we can replace the emoji with some meaningful text. So it’s very much up to your discretion.
Replacing elongated characters:
While we work with texts of public chats, we may find elongated words like hiiii, heeeey they need to be optimized to their original word.
Correction of Spellings:
There might be incorrect words in the corpus; we can correct their spellings by Text Blob
Text = TextBlob(incorrect_text) Text.correct()
Expanding the Contractions:
We even find contractions to some of the words in the corpus like I’ll for I will, I’ve for I have, I’m for I am etc. These contractions can be removed by following code:
words = [] for word in text.split(): words.append(contractions.fix(word))
Removing the Punctuation:
If we won’t remove punctuations, they would also add separate words. To avoid this, we need to remove punctuations in the corpus
All_punct = '''!()-[]{};:'",./?@#$%^&*_~'''
for elements in simple_text:
if elements in All_punct: simple_text = simple_text.replace(elements, "");
Stemming:
Stemming is the technique to replace and remove the suffixes and affixes to get the root, base or stem word. We may find similar words in the corpus but with different spellings like having, have, etc. All those are similar in meaning, so to make them into a base word, we use a concept called stemming, which converts words to their base word.
E.g. History -> Histori
Lemmatization:
Lemmatization is a technique similar to stemming. In stemming rood word may or may not have the meaning, but in lemmatization, root word surely would have a meaning; it uses lexical knowledge to transform words into their base forms.
E.g. History -> History
These are some preprocessing techniques used in handling text in Natural Language Processing.
Feature Extraction
Our next step would be identifying the features.
We have some techniques for representing text into vectors, so machines can understand the corpus easily. Those are word Embedding techniques. They are
1. One Hot Encoding
2. Bag of Words
3. Term Frequency Inverse Document Frequency (TF-IDF)
4. Word2Vec
1. One Hot Encoding (OHE)
Let’s consider we have 3 documents
D1 = A man eats food
D2 = Cat eat food
D3 = Vishal watches movies
Vocabulary = [A man eats food cat Vishal watches movies]
In OHE, Each word is associated with a vector with a length equal to the cardinality of the dictionary. All entries in each vector are 0, except for one position where we find a word represented as 1.
How to represent this context in vectors using OHE?

OHE is simple and intuitive. On the other hand, it has its disadvantages.
Disadvantages of OHE:
1. Sparse Matrix Creation
2. More Computation Time
3. Lots of Memory
4. Out of Vocabulary
5. Not fixed size
6. Semantic meaning behavior word is not captured
Out of Vocabulary (OOV): Let us understand it from the above example; in document 1, we have length 4 data, and in document 2, we have length 3 data; as the length of the data is decreased, we can’t train the model due of Out of Vocabulary. Also, different words in test data can’t be handled.
2. Bag of Words
Let us consider the three documents
D1 = He is a good boy
D2 = She is a good girl
D3 = Boy and girl are good
Firstly we will apply the elimination of stop words and remove unwanted words like (is, a, he, she, and, are). After removing stop words, our documents would be
D1 = good boy
D2 = good girl
D3 = Boy girl good
Vocabulary for a new document is V = good, boy, girl
Frequency of words in the vocabulary
good – 3
boy – 2
girl – 2

In the above picture, it was explained about representation in Bag of Words in general and in a binary row.
Of course, matrixes have been reduced with Bag of Words compared to OHE. The bag of words is simple and intuitive with some disadvantages, but it covered a few disadvantages of OHE, such as better computation time and memory usage.
Disadvantages in Bag of Words:
1. Sparsity – It is even observed here.
2. Out of Vocabulary
3. Ordering of words has completely changed
4. Semantic meaning not captured.
How to capture the semantic meaning?
To this, we need to use the concept of N-grams. N-grams are continuous sequences of words or symbols or tokens in a document. if n=2 it is Bigram, n=3 it is Trigram. N-gram models are useful in many text analytics applications, where sequences of words are relevant such as in sentiment analysis, text classification and text generation. For the same above example, we will observe applying N-grams.

3. Term Frequency – Inverse Document Frequency (TF-IDF)
Let us take documents as we considered in BOW (Bag of Words).
D1 = good boy
D2 = good girl
D3 = boy girl good
Let us first discuss TF-IDF. Here whichever words are less frequent are given more weightage.
Rare words are captured by Term Frequency.
Inverse Document Frequency captures frequent words.
Now we will see the formula for term frequency and Inverse Document Frequency
Term Frequency = (No repetition of words in the sentence) / (No of words in the sentence).
Inverse Document Frequency = loge(No of sentences / No of sentences containing the word).
Let us see the Term Frequency and Inverse Document Frequency for the above example.

TF-IDF has succeeded in capturing the word importance; even with capturing meaning, TF-IDF has disadvantages
Disadvantages:
1. Sparsity Issues ( less compared with Bow and OHE)
2. Out of Vocabulary.
We have another word embedding technique called Word2Vec
4. Word2Vec in NLP
Word2Vec not only maintained the semantic meaning of the words and captured the important words but also reduced the sparsity to a high extent. Vectors in Word2Vec are limited Dimensions. It can be obtained using two methods, both involving neural networks. Skip gram and Common Bag of Words (CBOW).
CBOW: This method takes each word’s context as input and tries to predict the word corresponding to the context. If we take the example Have a great day, the input for the neural network be great; we are going to predict the day using this single context input word.
Let us see the actual architecture
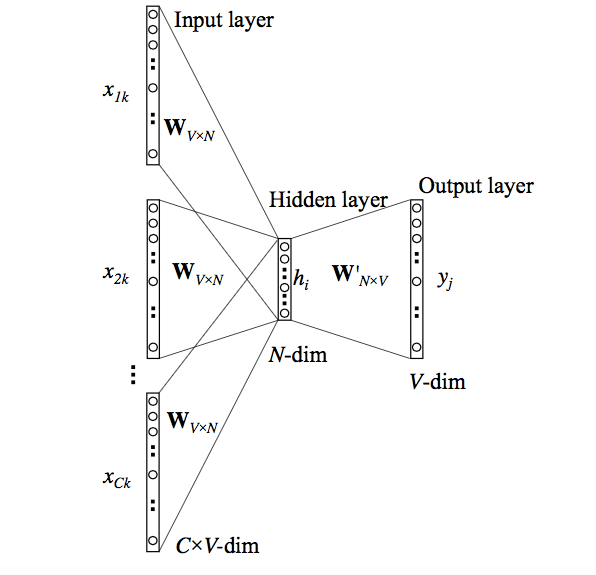
Source: Data Science Stack Exchange
This model takes C Context Words, Wvn is used to calculate hidden layer inputs, and we take an average over all these C context word inputs. This is one way of representation using context words. We even have another representation called skip-gram.
Advantages of CBOW:
1. It performs well with deterministic methods.
2. Low usage of Memory.
Disadvantages of CBOW:
1. For a word, CBOW takes the average of Contexts.
2. Failed to identify the combined word phrases, e.g. Honey bee, Vatican city etc.
Skip Gram: Skip gram is small changes to CBOW. CBOW input is output in Skip gram nearly and vice versa.
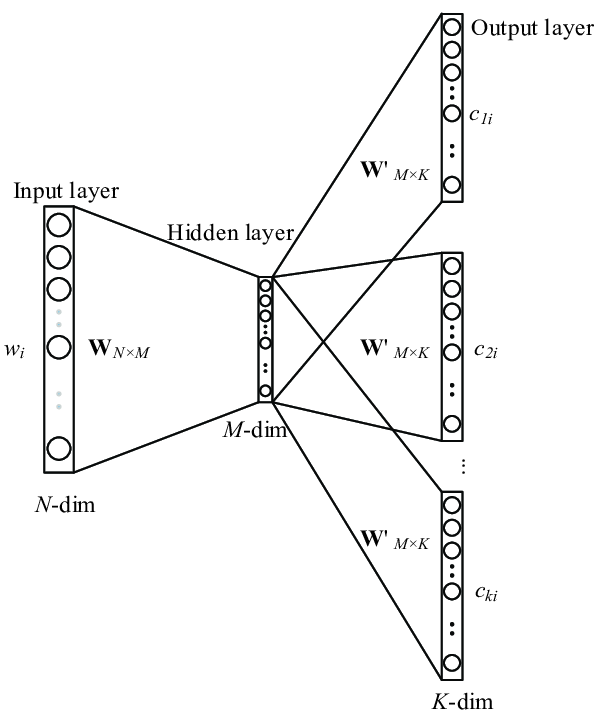
We input the target word into the network. For each context position, we get C probability distributions of V probabilities, one for each word.
Advantages of Skip gram:
1. Skip gram overcomes the disadvantage of CBOW about average contexts; skip-gram maintains two semantics for a single word.
2. Skip-gram with negative sub-sampling outperforms every other method generally.
Disadvantages of Skip gram:
1. Failed to identify the combined word phrases, e.g. Honey bee, Vatican city etc.
Conclusion to NLP
We hope you enjoyed this article on the basics of NLP, which covers all the basic stuff related to Natural Language Processing.
Natural Language Processing help machines to understand various texts and output sentiment or relevant words in filling the text. This helps us to reduce the work in analysing the text of large datasets. Machines td with NLP can even find the most talked about situation or used emotions on social media platforms.
The Keynotes are:
- Terminologies in NLP are required to understand the process easily.
- Many texts preprocessing steps are involved in NLP, and according to the requirement, we need to use them.
- No need to implement all feature extraction techniques. Depending on the problem requirement, a feature extraction technique must be chosen.
- Text Preprocessing is the most important step in making machines understand better about the context.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Myself Bhavesh, student from VIT Vellore, who loves to explore new technologies and make them implement into real world. I am enthusiast in field of ML, Data sciences. I love to solve real world problems in these fields and I am also a passionate in Exploring much in Data sciences domain.