Academia is the integral coaching zone for humanity’s future talent and the development of new approaches toward our survival as human species in terms of task execution and thinking. The academic score is an indicator used for performance assessment and management by schools and institutions, where rank and scale student talent and ability.
Data Context
We first see all the variables in the dataset and which variables we need for targets and their related attributions towards generating a prediction correctly. We have to use relatable and dependent variables toward a predictive outcome.
We can see that our dataset has multiple dependent and independent variables which showcase academic workflow and social and motivational influencing factors towards.
Our goal with the dataset is to predict the future math scores and related variables to see its interactive expedition.
Model Stage
Educational Model
We will choose ‘math score’ as our target variable against all remaining variables to get the correct prediction with a 30% Split. We will use 70% training and 30% testing(unseen) data for predictive accuracy.
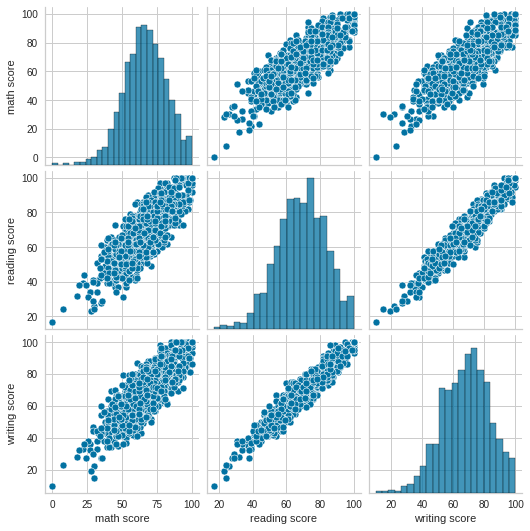
We can see above that math score is linearly influenced by reading and writing scores showing students who are good at reading and writing can also learn maths at a good pace.
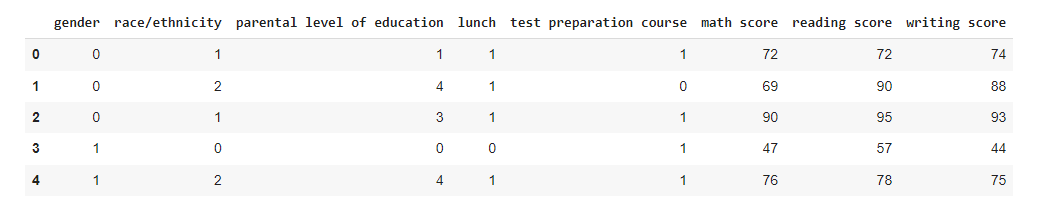
We first transform all categorical variables using a label encoder to make it easier for Machine Learning modeling to detect inputs and give outputs. As shown below:
As shown above, our inputs have transformed into a readable format for ML algorithms.
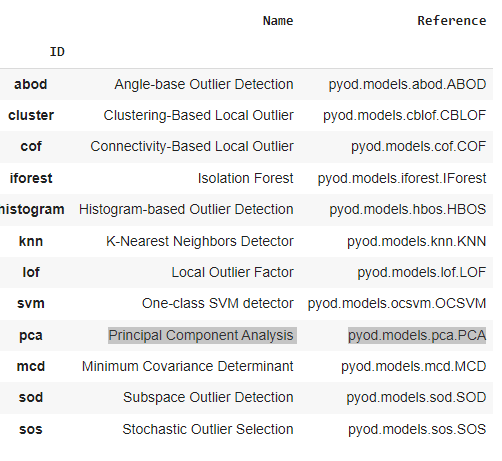
We feed our transformed data into Pycaret algorithms and get model recommendations below.
Our model choices from the list above are:
One class SVM(svm)
Isolation forest(forest).
Principal Component Analysis(PCA).
They are the best choices for accounting outliers into our data fitting and forecasting datasets with accuracy even if the linear data becomes non-linear at any point of the journey and help us identify and reduce those irrelevant data points to achieve accuracy in predictions as math scores involve grading beyond percentile levels and can create anomalies.
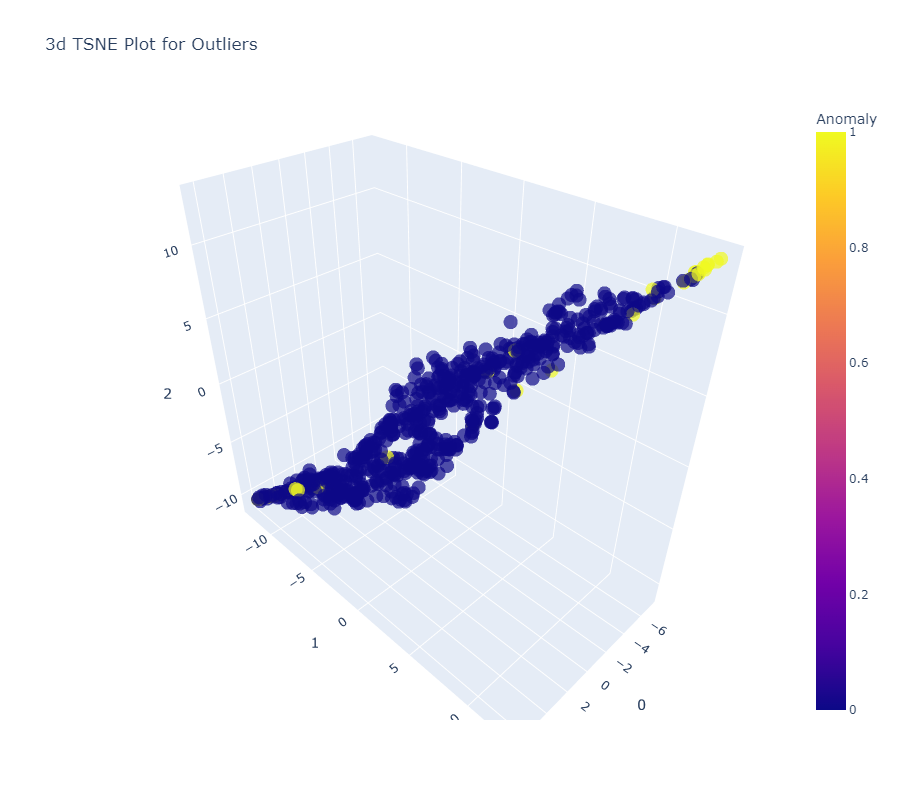
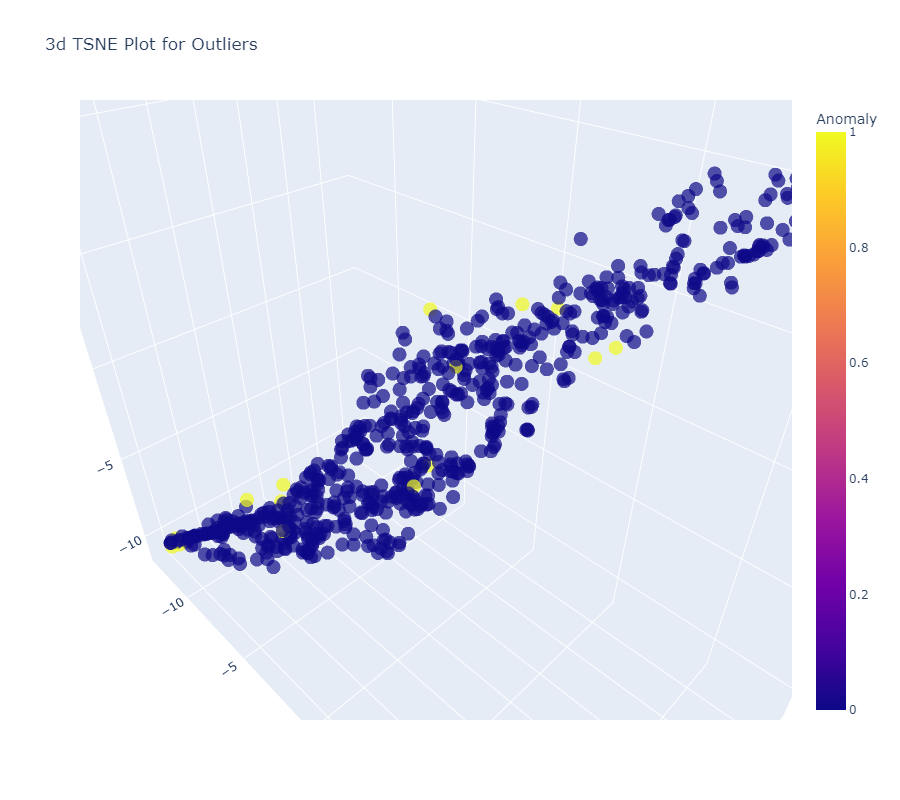
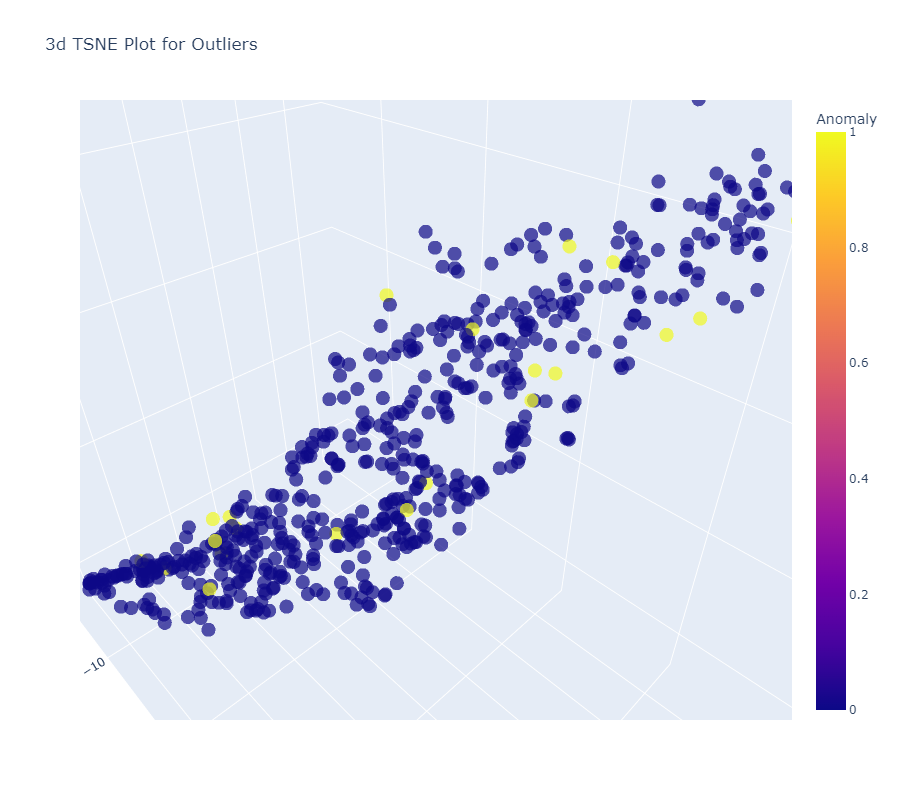
IOF Model
SVM ModelPCA Model
We can see Linear relationships in all three model visualizations. We choose PCA as our best predictive approach amongst all three as data shows best fitted in it with anomalies accounted.
Score relevance
After conducting our Exploratory analysis of our PCA model predictions generated, we can create insights for education strategy development to improve math scores earnt by students.
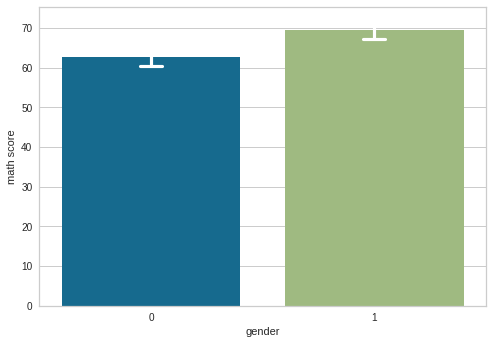
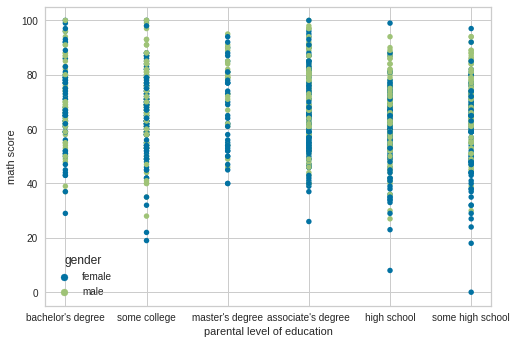
We can see that males are getting better-predicted grades for maths than females, which might demotivate females from improved scores. Thus, extra classes for maths need to be provided to females at their discretion to allow them to improve without demotivation.
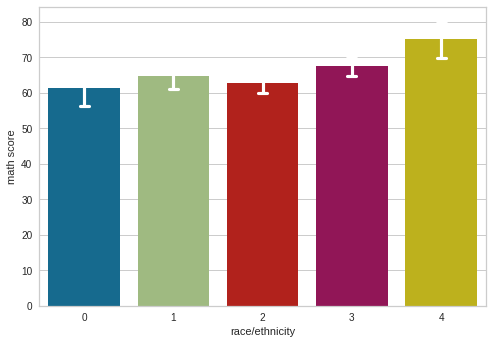
We have to identify Group D as they are showing the best predictive math scores so they can help other groups in math teaching assistance.
We are noticing that female parents are showing higher predicted levels of education. However, in terms of math scores, males still receive more grades at the top quartile, thus showing that cultural factors or promoting male education at Home and School may be the outer influencing variable behind it.
import missingno as mn
mn.heatmap(df)
# We Fill in the missing values based on the relationships above.
#we can see that missing values are not at random
# Machine Learning model
import seaborn as sns
from matplotlib import pyplot as plt
sns.pairplot(df)
from sklearn.preprocessing import OneHotEncoder, LabelEncoder
#tranform variables:
#gender
#race/ethnicity
#parental level of education
#lunch
#test preparation course
#Label encoding on categorical variables
encoder = LabelEncoder()
#perform encoding on 'team' column
df['gender']= encoder.fit_transform(df[['gender']])
#perform encoding on 'race' column
df['race/ethnicity']= encoder.fit_transform(df[['race/ethnicity']])
#perform encoding on 'education level' column
df['parental level of education']= encoder.fit_transform(df[['parental level of education']])
#perform encoding on 'lunch' column
df['lunch']= encoder.fit_transform(df[['lunch']])
#perform encoding on 'test prep' column
df['test preparation course'] = encoder.fit_transform(df[['test preparation course']])
df.head()
## We can see linear relationships amongst our variables
# especially how math is related to reading and writing
# We check our approach using Pycaret
# Lets do it
!pip install pycaret
!pip install markupsafe==2.0.1
# we set our math SAT score as target variable
X = df
y = df['math score']
from pycaret.anomaly import *
### we divide the data into a 30 % split in seen(train) and unseen(test)
data = X.sample(frac=0.70, random_state=700)
data_unseen = X.drop(data.index)
data.reset_index(drop=True, inplace=True)
data_unseen.reset_index(drop=True, inplace=True)
print('Data for Modeling: ' + str(data.shape))
print('Unseen Data For Predictions: ' + str(data_unseen.shape))
exp_ano101 = setup(data, normalize = False, session_id = 123, log_experiment = False)
models()
## lof Local Outlier Factor, pyod.models.lof.LOF,
## svm One-class SVM detector pyod.models.ocsvm.OCSVM,
## pca Principal Component Analysis pyod.models.pca.PCA
# Will be the model we will test
We were able to get an analysis of the Female grading and model predictions of it and insight into cultural trends in our education settings.
With the implementation and analysis of our machine learning workflow above, we can:
Create Improvement plans for female academic performance in classrooms.
Do awareness sessions on education and the importance of meritocracy in bridging the gap between success likelihood between males and females.
Invest in a gender-neutral curriculum and encourage females in STEM-based subject selection as we can see higher rates of male performance within it.
Project Implementation process
To implement machine learning workflow at any institute, we need to follow a particular sequence of steps, including pilot testing and feasibility study, which include:
Conduct data analysis on the ratio of school genders.
Check academic success records of female and male students and other recognized genders in school settings.
Check which gender lacks Academic success.
Sign an agreement between the Institute and the implementor regarding data migration and usage.
Ensure all ethical guidelines are met on the dataset used.
Feature engineer the variables “gender”, “race/ethnicity”, “parental level of education”, “lunch”,”test preparation course”, “math score”, “reading score”, “writing score”.
Run the model on the data and see if it needs cross-validation for more improvement.
Deploy it on the Institute’s cloud server or local machines once the test run is successful with the stakeholder’s agreement.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
A verification link has been sent to your email id
If you have not recieved the link please goto Sign Up page again
Loading…
back
Please enter the OTP that is sent to your registered email id
email 2
Loading…
back
Please enter the OTP that is sent to your email id
email 2
Loading…
back
Please enter your registered email id
email 2
This email id is not registered with us. Please enter your registered email id.
Don’t have an account yet?Register here
Loading…
back
Please enter the OTP that is sent your registered email id
email 2
Loading…
Please create the new password here
key-
key-
We use cookies on Analytics Vidhya websites to deliver our services, analyze web traffic, and improve your experience on the site. By using Analytics Vidhya, you agree to our Privacy Policy and Terms of Use.Accept
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.


















{kind=link}
Clear