



{kind=link}
The loss function is very important in machine learning or deep learning. let’s say you are working on any problem and you have trained a machine learning model on the dataset and are ready to put it in front of your client. But how can you be sure that this model will give the optimum result? Is there a metric or a technique that will help you quickly evaluate your model on the dataset? Yes, here loss functions come into play in machine learning or deep learning. In this article, we will explain everything about loss function in Deep Learning.
This article was published as a part of the Data Science Blogathon.
Table of contents
What is Loss Function in Deep Learning?
In mathematical optimization and decision theory, a loss or cost function (sometimes also called an error function) is a function that maps an event or values of one or more variables onto a real number intuitively representing some “cost” associated with the event.
In simple terms, the Loss function is a method of evaluating how well your algorithm is modeling your dataset. It is a mathematical function of the parameters of the machine learning algorithm.
In simple linear regression, prediction is calculated using slope(m) and intercept(b). the loss function for this is the (Yi – Yihat)^2 i.e loss function is the function of slope and intercept.
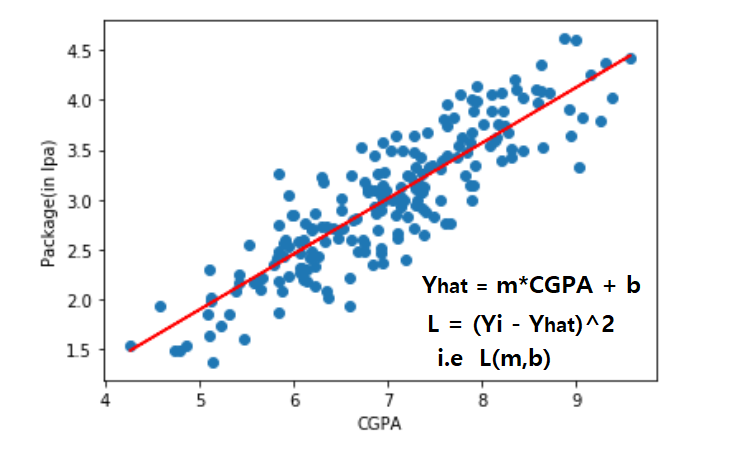
Why Loss Function in Deep Learning is Important?
Famous author Peter Druker says You can’t improve what you can’t measure. That’s why the loss function comes into the picture to evaluate how well your algorithm is modeling your dataset.
if the value of the loss function is lower then it’s a good model otherwise, we have to change the parameter of the model and minimize the loss.
Cost Function vs Loss Function in Deep Learning
Most people confuse loss function and cost function. let’s understand what is loss function and cost function. Cost function and Loss function are synonymous and used interchangeably but they are different.
| Loss Function | Cost Function |
|---|---|
| Measures the error between predicted and actual values in a machine learning model. | Quantifies the overall cost or error of the model on the entire training set. |
| Used to optimize the model during training. | Used to guide the optimization process by minimizing the cost or error. |
| Can be specific to individual samples. | Aggregates the loss values over the entire training set. |
| Examples include mean squared error (MSE), mean absolute error (MAE), and binary cross-entropy. | Often the average or sum of individual loss values in the training set. |
| Used to evaluate model performance. | Used to determine the direction and magnitude of parameter updates during optimization. |
| Different loss functions can be used for different tasks or problem domains. | Typically derived from the loss function, but can include additional regularization terms or other considerations. |
Loss Function in Deep Learning
- Regression
- MSE(Mean Squared Error)
- MAE(Mean Absolute Error)
- Hubber loss
- Classification
- Binary cross-entropy
- Categorical cross-entropy
- AutoEncoder
- KL Divergence
- GAN
- Discriminator loss
- Minmax GAN loss
- Object detection
- Focal loss
- Word embeddings
- Triplet loss
In this article, we will understand regression loss and classification loss.
A. Regression Loss
1. Mean Squared Error/Squared loss/ L2 loss
The Mean Squared Error (MSE) is the simplest and most common loss function. To calculate the MSE, you take the difference between the actual value and model prediction, square it, and average it across the whole dataset.
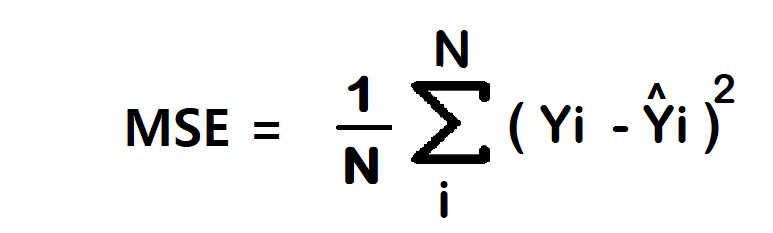
Advantage
- 1. Easy to interpret.
- 2. Always differential because of the square.
- 3. Only one local minima.
Disadvantage
- 1. Error unit in the square. because the unit in the square is not understood properly.
- 2. Not robust to outlier
Note – In regression at the last neuron use linear activation function.
2. Mean Absolute Error/ L1 loss
The Mean Absolute Error (MAE) is also the simplest loss function. To calculate the MAE, you take the difference between the actual value and model prediction and average it across the whole dataset.
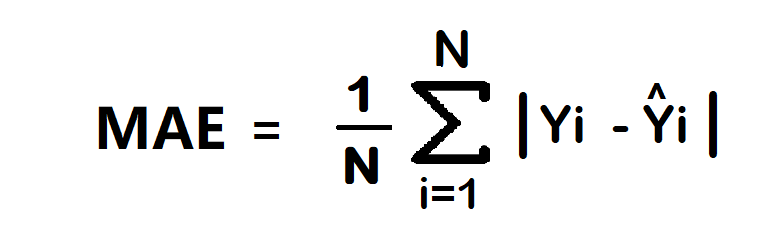
Advantage
- 1. Intuitive and easy
- 2. Error Unit Same as the output column.
- 3. Robust to outlier
Disadvantage
- 1. Graph, not differential. we can not use gradient descent directly, then we can subgradient calculation.
Note – In regression at the last neuron use linear activation function.
3. Huber Loss
In statistics, the Huber loss is a loss function used in robust regression, that is less sensitive to outliers in data than the squared error loss.
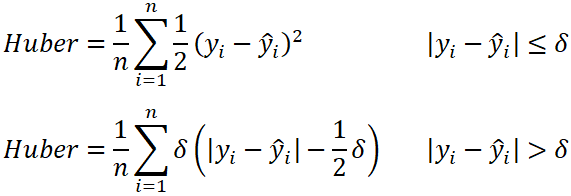
- n – the number of data points.
- y – the actual value of the data point. Also known as true value.
- ŷ – the predicted value of the data point. This value is returned by the model.
- δ – defines the point where the Huber loss function transitions from a quadratic to linear.
Advantage
- Robust to outlier
- It lies between MAE and MSE.
Disadvantage
- Its main disadvantage is the associated complexity. In order to maximize model accuracy, the hyperparameter δ will also need to be optimized which increases the training requirements.
B. Classification Loss
1. Binary Cross Entropy/log loss
It is used in binary classification problems like two classes. example a person has covid or not or my article gets popular or not.
Binary cross entropy compares each of the predicted probabilities to the actual class output which can be either 0 or 1. It then calculates the score that penalizes the probabilities based on the distance from the expected value. That means how close or far from the actual value.
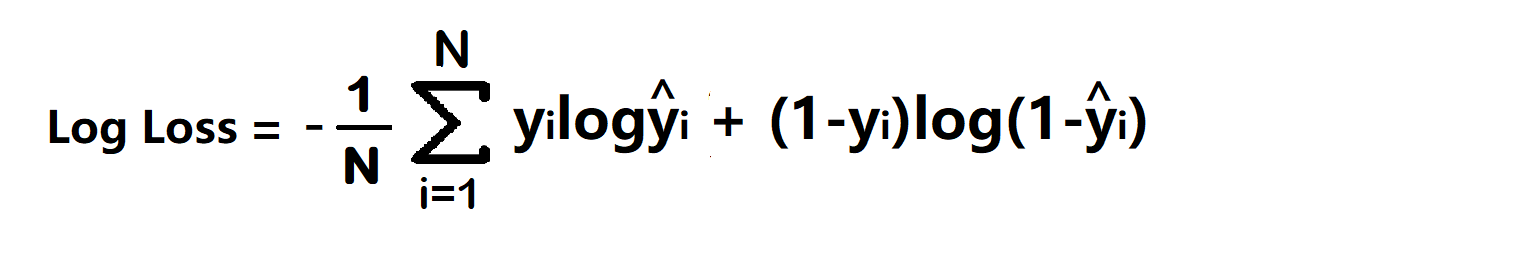
- yi – actual values
- yihat – Neural Network prediction
Advantage –
- A cost function is a differential.
Disadvantage –
- Multiple local minima
- Not intuitive
Note – In classification at last neuron use sigmoid activation function.
2. Categorical Cross Entropy
Categorical Cross entropy is used for Multiclass classification and softmax regression.
loss function = -sum up to k(yjlagyjhat) where k is classes
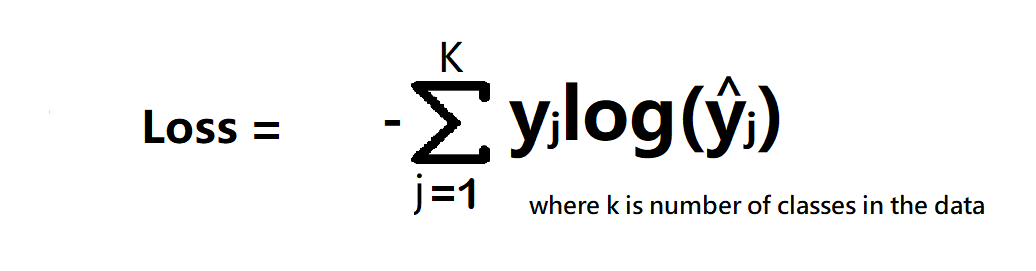
cost function = -1/n(sum upto n(sum j to k (yijloghijhat))
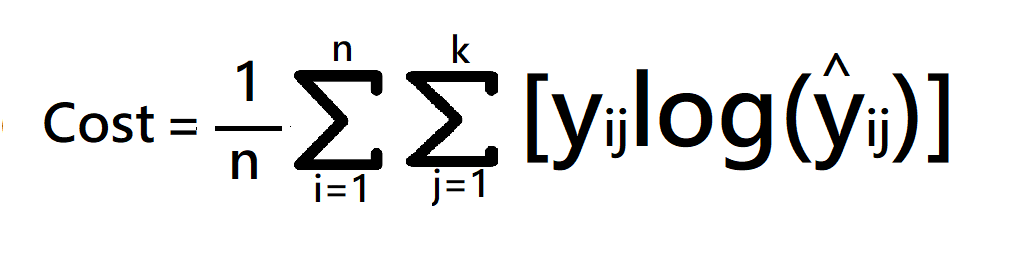
where
- k is classes,
- y = actual value
- yhat – Neural Network prediction
Note – In multi-class classification at the last neuron use the softmax activation function.
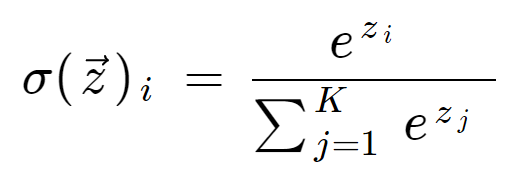
if problem statement have 3 classes
softmax activation – f(z) = ez1/(ez1+ez2+ez3)
When to use categorical cross-entropy and sparse categorical cross-entropy?
If target column has One hot encode to classes like 0 0 1, 0 1 0, 1 0 0 then use categorical cross-entropy. and if the target column has Numerical encoding to classes like 1,2,3,4….n then use sparse categorical cross-entropy.
Which is Faster?
sparse categorical cross-entropy faster than categorical cross-entropy.
Conclusion
In this article, we learned about different types of loss functions. The key takeaways from the article are:
- We learned the importance of loss function in deep learning.
- Difference between loss and cost.
- The mean absolute error is robust to the outlier.
- This function is used for binary classification.
- Sparse categorical cross-entropy is faster than categorical cross-entropy.
So, this was all about loss functions in deep learning. Hope you liked the article.
Frequently Asked Questions
A. A loss function is a mathematical function that quantifies the difference between predicted and actual values in a machine learning model. It measures the model’s performance and guides the optimization process by providing feedback on how well it fits the data.
A. In deep learning, “loss function” and “cost function” are often used interchangeably. They both refer to the same concept of a function that calculates the error or discrepancy between predicted and actual values. The cost or loss function is minimized during the model’s training process to improve accuracy.
A. L1 loss function, also known as the mean absolute error (MAE), is commonly used in deep learning. It calculates the absolute difference between predicted and actual values. L1 loss is robust to outliers but does not penalize larger errors as strongly as other loss functions like L2 loss.
A. In deep learning for natural language processing (NLP), various loss functions are used depending on the specific task. Common loss functions for tasks like sentiment analysis or text classification include categorical cross-entropy and binary cross-entropy, which measure the difference between predicted and true class labels for classification tasks in NLP.
1. Backpropagation is an algorithm that updates the weights of the neural network in order to minimize the loss function.
2. Backpropagation works by first calculating the loss function for the current set of weights.
3. Next, it calculates the gradient of the loss function with respect to the weights.
4. Finally, it updates the weights in the direction opposite to the gradient.
5. The network is trained until the loss function stops decreasing.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.