



{kind=link}
This article was published as a part of the Data Science Blogathon.
An end-to-end guide on building Information Retrieval system using NLP
Hey Folks!!
I hope that you have enjoyed my last article that was all about Text-Generation using LSTM, if you haven’t read that yet prefer this link.
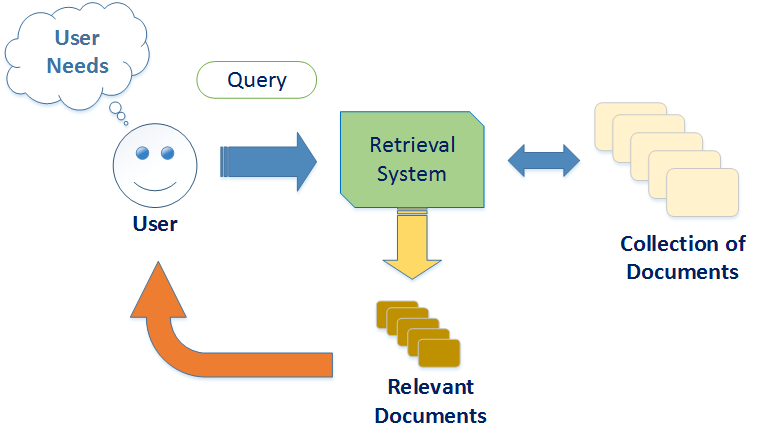
In this article, we will cover a very interesting yet tricky use case of NLP which is an Information retrieval system. Information retrieval system is a very widely used application of NLP.
In an information retrieval system, we will have various collections of documents and we need to search for a specific document by passing a context meaning.
Table of Contents
- Introduction
- Word Embedding
- Implementing IR system
Introduction
Google has trillions of web pages, how Google efficiently searches relevant web pages for us without taking the page URL?.
An IR(information retrieval ) system allows us to search a document based on the meaningful information about that document in an efficient way.
As we know that two sentences can have very different structures and different words but they possibly can have the same meaning. In NLP our goal is to capture the meaning of the sentences, by using various NLP concepts which we will see in detail further in the article.
In IR system we use the context meaning to search documents.
Problem statement: Perform an Information retrieval system using context meaning.
Solution:
There could be multiple ways to perform Information retrieval. But the easiest yet very efficient way to do it using word embedding. word embedding takes the context meaning into consideration regardless of sentence structure.
Applications of IR system:
- Document retrieval
- Passage retrieval
- Search engines
- Question answering
Word Embedding
I have written an article on various feature extraction techniques including word embedding implementation, if you haven’t read it, the link is here.
word embedding is capable of understanding the meaning of the sentence, regardless of the word structure.
For example
“I love him” and “I like him” will have the almost same meaning if we use word embedding
It is a predictive feature learning technique where words are mapped to the vectors using their contextual hierarchy.
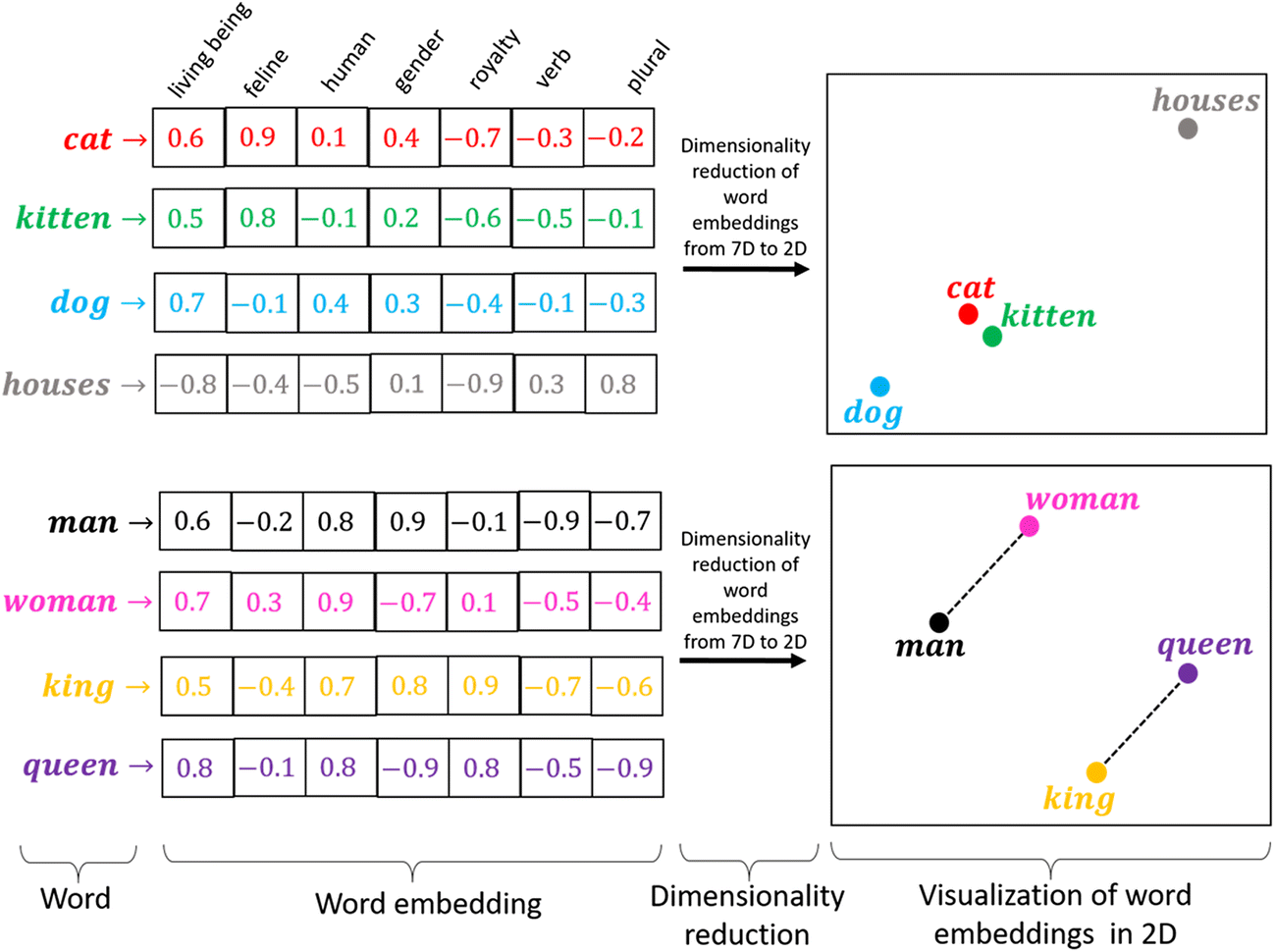
As you see kitten and cat are placed very closely because they have very close meanings.
word embedding has been trained on more than 8 billion words using shallow neural networks, we will use the pre-trained word embedding vector for our task.
Implementing IR System
We are going to implement the information retrieval system using python.
While implementing the information retrieval system there are some steps that we need to follow:-
- Getting the data
- Cleaning the data
- Loading pre-trained word2vec
- Getting the context-meaning of docs
- Comparing queries with documents
1 Getting the Document
we have created our own dataset containing 4 documents, for better understanding, we will use a small dataset.
Doc1 = ["""Wasting natural resources is a very serious problem, since we all know that natural resources are limited but still we dont feel it. We use it more than we need, Government are also encouraging people to save the natural resoucres""" ] Doc2 = ["""Machine learning is now days a very popular field of study, a continuous reasearch is going on this , Machine learning is all about maths. Analysing the patters solve the task."""] Doc3 = ["""Nowdays books are loosing its charm since the phones and smart gadgets has taken over the old time, Books are now printed in Digital ways, This saves papers and ultimately saves thousands of trees"""] Doc4 = ["""The man behind the wicket is MS DHONI , his fast hand behind wicket are a big advantage for india, but pant has now carrying the legacy of DHONI but he is not that fast"""]
here we have 4 documents and our dataset will be a list of documents separated by a comma.
#------merging all the documents------- data = doc1+doc2+doc3+doc4 print(data)

2 Importing Necessary Libraries
We are importing all the dependencies that gonna be in use at once.
import numpy as np
import nltk
import itertools
from nltk.corpus import stopwords
from nltk.tokenize import sent_tokenize, word_tokenize
import scipy
from scipy import spatial
import re
tokenizer = ToktokTokenizer()
stopword_list = nltk.corpus.stopwords.words('english')
3 Data Cleaning
In NLP data cleaning always generalize our training and promise better results. It’s always a good practice to perform data cleaning after loading the data.
making a function for data cleaning
def remove_stopwords(text, is_lower_case=False):
pattern = r'[^a-zA-z0-9s]'
text = re.sub(pattern," ",''.join(text))
tokens = tokenizer.tokenize(text)
tokens = [tok.strip() for tok in tokens]
if is_lower_case:
cleaned_token = [tok for tok in tokens if tok not in stopword_list]
else:
cleaned_tokens = [tok for tok in tokens if tok.lower() not in stopword_list]
filtered_text = ' '.join(cleaned_tokens)
return filtered_text
The function remove_stopwords takes documents one by one and returns the cleaned document.
- we first removed all the unnecessary characters using regular expressions.
- After removing the unnecessary characters we tokenized the filtered word and used stopword_list to filter out all the stopwords.
4 Implementing Word Embedding
We will be using a pre-trained word vector of 300 dimensions. you can download the word vector using this link. I would suggest you create a notebook on Kaggle is a better option if you don’t want to download the big file of world-vectors.
Loading the word vectors
the word vector is a text file containing the words and their corresponding vectors.

glove_vectors = dict()
file = open('../input/glove6b/glove.6B.300d.txt', encoding = 'utf-8')
for line in file:
values = line.split()
word = values[0]
vectors = np.asarray(values[1:])
glove_vectors[word] = vectors
file.close()
glove_vectorIt’s a dictionary containing words as keys and values as feature vectors.glove.6B.300dThis word embedding is trained on 6Billions of words and the feature vectors length is 300.- If a word is not present in our word vector dictionary it will return a zero vector of 300 lengths.
example:
glove_vectors['cat']
The returned feature vector for the cat is having 300 feature values.
Creating a feature vector for our document using word-embeddings.
We are creating a function that takes a sentence and returns the feature vector of 300 dimensions.
vec_dimension = 300
def get_embedding(x):
arr = np.zeros(vec_dimension)
text = str(x).split()
for t in text:
try:
vec = glove_vectors.get(t).astype(float)
arr = arr + vec
except:
pass
arr = arr.reshape(1,-1)[0]
return(arr/len(text))
5 Summarizing the Document
A document contains many sentences and a sentence has a lot of vectors based on the number of words present in that sentence.
To sum up the meaning of a document, we need to average the meaning of all the sentences inside that document.
In the language of NLP, we average all the feature vectors of all sentences inside that document.
out_dict = {}
for sen in fin:
average_vector = (np.mean(np.array([get_embedding(x) for x in nltk.word_tokenize(remove_stopwords(sen))]), axis=0))
dict = { sen : (average_vector) }
out_dict.update(dict)
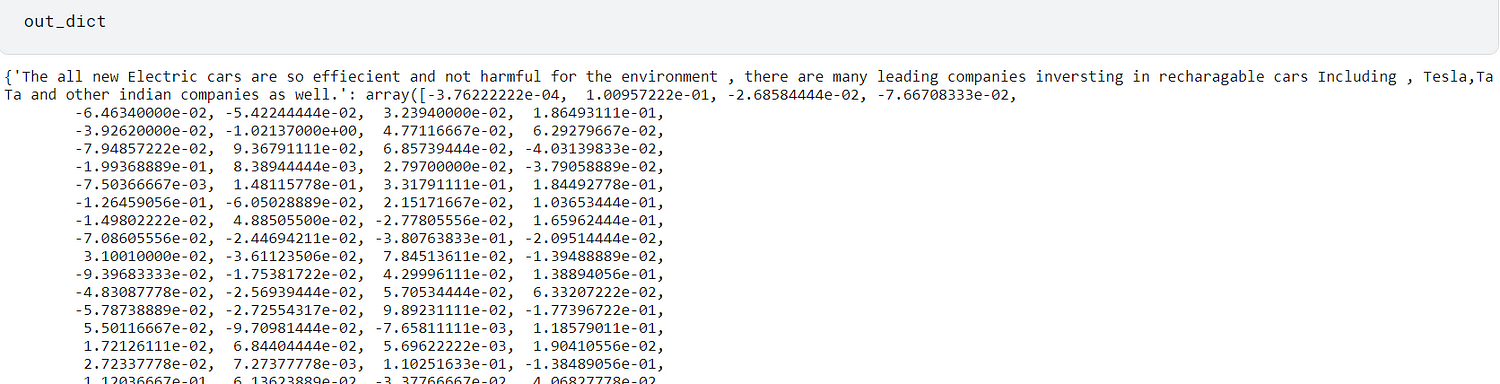
- The dictionary out_dict contains documents as key and their average feature vectors as their corresponding values.
- The average feature vectors encode the meaning of a document into vectors.
6 Comparing the Meaning of a Context
As of now, we have the feature vector of each and every document and we need to build a function that can compare the feature vectors based on their meaning.
The similarity of two words can be calculated by using cosine-distance between their feature vectors.
def get_sim(query_embedding, average_vector_doc):
sim = [(1 - scipy.spatial.distance.cosine(query_embedding,
average_vector_doc))]
return sim
- the function
get_simtakes feature-vector of queries and feature-vector of all documents and returns the similarity between query and document. - If the similarity
simis higher, closer to 1 we can say it has almost the same meaning. - If the similarity
simis closer to 0, we can say their meaning is different. - the package
scipyprovides the classscipy.spatial.distance.cosinefor calculating the cosine distance.
7 Making Queries
We are ready with feature vectors of documents as well as we have created the function to compare the similarity of two feature vectors.
def Ranked_documents(query):
query_word_vectors = (np.mean(np.array([get_embedding(x) for x in nltk.word_tokenize(query.lower())],dtype=float), axis=0))
rank = []
for k,v in out_dict.items():
rank.append((k, get_sim(query_word_vectors, v)))
rank = sorted(rank,key=lambda t: t[1], reverse=True)
print('Ranked Documents :')
return rank[0]
query_word_vectorsIt holds the feature vectors of the input query.- The function
Ranked_documentcompares the similarity between feature vectors of the query with the documents feature vector iteratively. - we are returning only one most similar document as our output.
8 Results
When we call the Ranked_document function by passing a query the function will return the one most relevant document related to our query.
Example1:
Ranked_documents('bat and ball')

As you see bat and ball is related to cricket when we searched this keyword the model returns the document related to cricket. Moreover, In the document, there is no bat and ball word present.
Example2:
Ranked_documents(‘computer science’)

As we all know that computer science is related to machine learning. when we queried the keyword computer science it returned the document related to computer science.
Conclusion
In this article, we discussed the document retrieval system, which is based on the comparison of the meaning of a document /sentence by comparing the feature vectors.
We Implemented the document retrieval system using python and pre-trained word embedding. There are multiple ways to perform document matching but using word-embedding and scipy’s cosine distance it becomes so easier to implement.
Hope you liked my article on search engines using deep learning?
You can copy and download the codes used in this article using this link.
Feel free to hit me on Linkedin if you have any queries or suggestions for me.
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.