



{kind=link}
This article was published as a part of the Data Science Blogathon.
This article will support data scientists in furthering their studies on recommendation systems so that they can develop applications for professional use. We introduce the content-based filtering, for the recommendation system, using this filtering, we learn here how to use this system and how to predict items, we use an amazon dataset.
In recommendation systems, we have two techniques, In this bog we major focus on content-based filtering.
- Collaborative Filtering.
- Content-based Filtering.
Today in real-world recommendation systems are an integral part of our lives. In amazon Roughly 35% of revenue is made by a Recommendation system, hence we can say the Recommendation system contributes to the major chunk of revenue in amazon. Working on recommendation algorithms is one of my favourite things to do. When I come across a recommendation engine on a website, I immediately want to dissect it and, how it works. It’s one of the many perks of a data scientist!
Collaborative Filtering
In this filtering, we use user and item reviews and then using this review we find a common user who has the same interest-as other users.
Content-based Filtering
Content-based filtering we recommend to what the user likes, based on their interest.

Source: Wikipedia
Table of Contents
What is the Recommendation System?
Overview of Data
The Feature List
data.columns # prints column-names or feature-names.
data = data[['asin', 'brand', 'color', 'medium_image_url', 'product_type_name', 'title', 'formatted_price']]
print ('Number of data points : ', data.shape[0],
'Number of features:', data.shape[1])
data.head() # prints the top rows in the table.
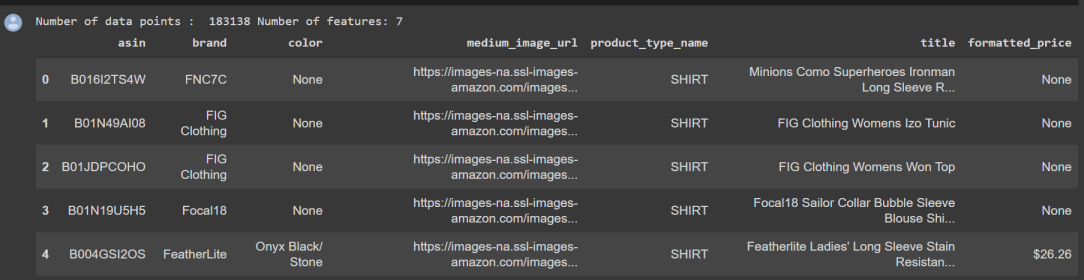
Source: Author’s GitHub Profile
Data Preprocessing
Remove the same Image.

.

Source: Author’s GitHub Profile
Text Preprocessing
Remove the stop word
# we use the list of stop words that are downloaded from nltk lib.
import nltk
nltk.download('stopwords')
stop_words = set(stopwords.words('english'))
print ('list of stop words:', stop_words)
{“couldn’t”, ‘such’, ‘where’, ‘too’, ‘are’, ‘ve’, ‘your’, ‘him’, ‘this’, “wouldn’t”, “didn’t”, ‘has’, ‘than’, ‘ll’, ‘very’, ‘who’, ‘having’, ‘for’, “should’ve”, ‘mightn’, ‘of’, ‘until’, ‘we’, ‘haven’, “you’d”, ‘while’, “shouldn’t”, ‘doing’, “mightn’t”, ‘just’, ‘through’, ‘own’, ‘o’, ‘what’, ‘any’, ‘will’, “weren’t”, ‘have’, “hadn’t”, ‘my’, ‘weren’, ‘most’, “aren’t”, ‘it’, ‘had’, ‘further’, ‘more’, ‘those’, ‘on’, ‘against’, “doesn’t”, ‘himself’, ‘their’, ‘few’, ‘being’, ‘you’, ‘below’, ‘in’, ‘here’, ‘be’, “mustn’t”, “wasn’t”, ‘nor’, ‘then’, ‘how’, “that’ll”, ‘a’, ‘hasn’, ‘mustn’, “needn’t”, ‘shouldn’, ‘by’, ‘doesn’, ‘hadn’, ‘y’, ‘herself’, “she’s”, ‘shan’, ‘do’, ‘d’, ‘an’, ‘ourselves’, ‘the’, ‘that’, ‘after’, ‘there’, “you’re”, ‘them’, ‘was’, ‘itself’, ‘hers’, ‘yours’, ‘needn’, ‘down’, ‘its’, “you’ll”, ‘didn’, “won’t”, ‘both’, ‘these’, ‘up’, ‘again’, ‘his’, ‘did’, ‘our’, ‘when’, ‘only’, ‘s’, ‘over’, ‘because’, ‘wasn’, ‘should’, ‘so’, ‘re’, ‘couldn’, ‘under’, ‘ain’, ‘at’, “it’s”, ‘as’, ‘he’, ‘all’, ‘does’, “don’t”, ‘won’, ‘whom’, ‘to’, ‘i’, “haven’t”, ‘ma’, ‘were’, “hasn’t”, ‘m’, ‘above’, ‘each’, ‘she’, “isn’t”, ‘between’, ‘they’, ‘am’, ‘no’, ‘myself’, ‘yourself’, ‘during’, ‘t’, ‘out’, ‘off’, ‘wouldn’, “you’ve”, ‘or’, ‘with’, ‘ours’, ‘before’, ‘same’, ‘which’, ‘into’, ‘now’, “shan’t”, ‘if’, ‘themselves’, ‘isn’, ‘about’, ‘yourselves’, ‘theirs’, ‘and’, ‘don’, ‘not’, ‘from’, ‘can’, ‘me’, ‘but’, ‘is’, ‘once’, ‘why’, ‘some’, ‘her’, ‘aren’, ‘been’, ‘other’}
Apply Stemming
from nltk.stem.porter import *
stemmer = PorterStemmer()
print(stemmer.stem('arguing'))
print(stemmer.stem('fishing'))
Output.
argu fish
Apply the Different Techniques to Convert Text to Vector
TF-IDF Base Word to Vector
Here we use a TF-IDF to convert a text to a vector and after this, we got a vector for each title.

Source: Towards Data Science
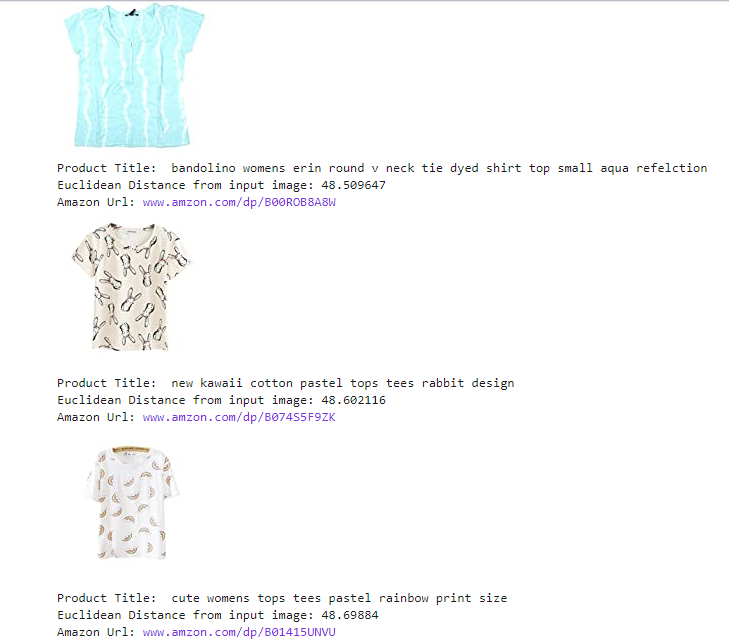
Now we have a vector and for this find, similarity we use a Euclidean distance, which product dist is very small to the query product we can defined-as a similar product.
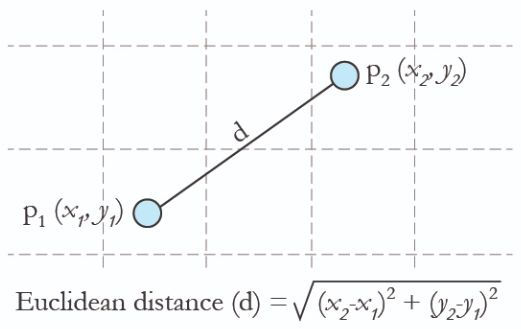
Source: Tutorial Example
Similar Product Output





Source: Author’s GitHub Profile
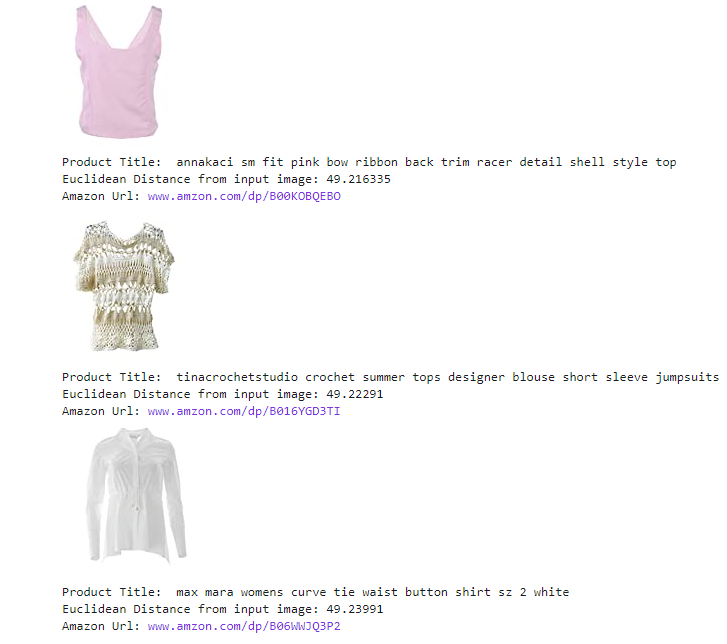
Brand and Color similarity




Source: GitHub Profile
Here we can see this is more focused on colour and brand.
Image similarity
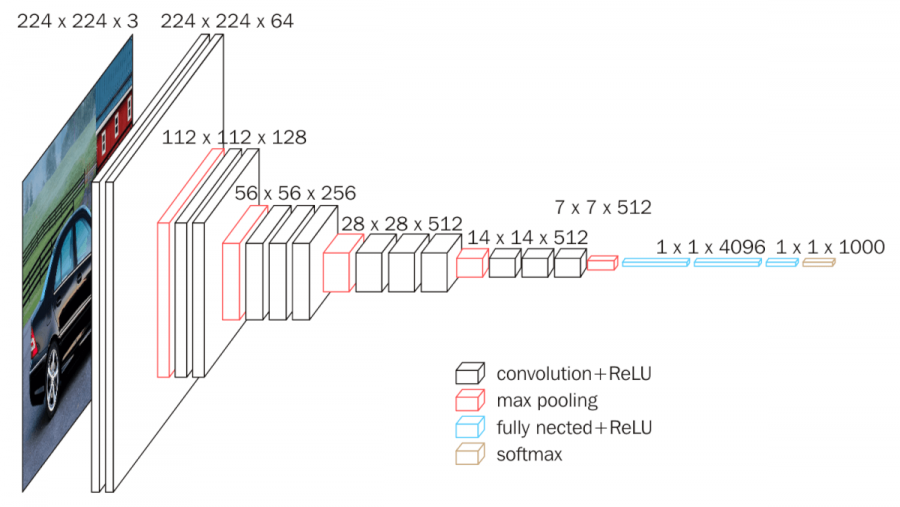
Source: https://neurohive.io/en/popular-networks/vgg16/
The output of the VGG16 model.
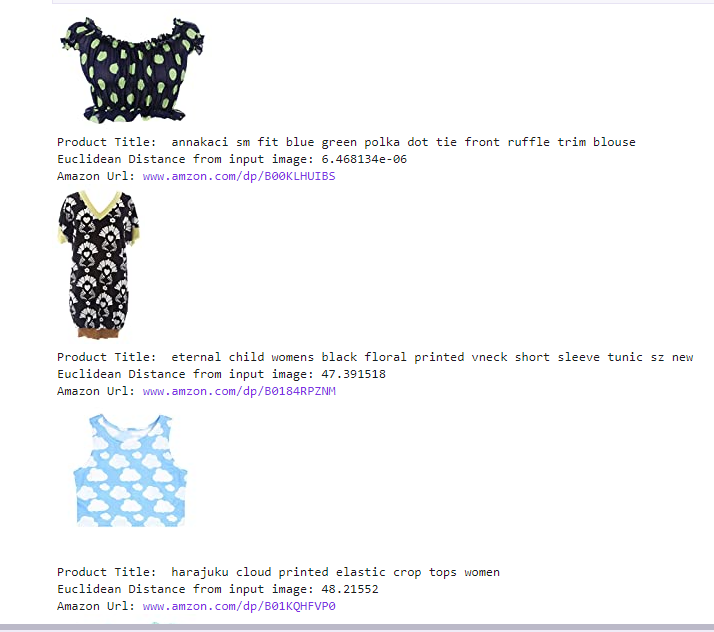
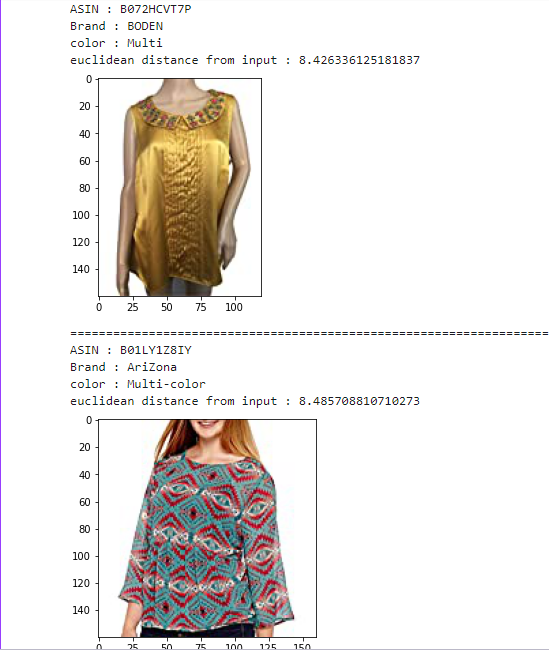
Combine all features for similarity




Measuring the Effectiveness of the Solution
So here we provide 5 solutions for finding a similar product, we can perform A/B testing.
For more about A/B testing. https://en.wikipedia.org/wiki/A/B_testing
For full code:- https://github.com/shivambaldha/Amazon-Apparel-Recommendations
Conclusion
Recommendation systems are a powerful new tool for adding value to a company and, These systems assist users in locating things they wish to purchase from a business. Recommendation systems are quickly becoming a critical element in online E-commerce.
References
- https://www.cs.umd.edu/~samir/498/Amazon-Recommendations.pdf
- http://www10.org/cdrom/papers/519/node36.html
Connect with me
- Linkedin: https://www.linkedin.com/in/shivam-baldha/
- Github: https://github.com/shivambaldha