



{kind=link}
This article was published as a part of the Data Science Blogathon
Overview:
Users formerly needed to know specialist languages, such as OpenGL, to use GPUs, which is related to their original purpose. These languages were designed specifically for GPUs, making them difficult to learn and use. GPUs, which were originally designed to speed up graphics processing, may now be used to substantially speed up deep learning computations.
Table of content
- Introduction.
- How does deep learning implement modern GPUs?
- Importance of GPUs for Deep Learning.
- Why PyTorch?
- Is PyTorch a deep learning framework?
- Key features of PyTorch in deep learning:
- CUDA SEMANTICS.
- Asynchronous execution.
- Agnostic-device code.
- About Myself.
- Conclusion
Introduction
In today’s extremely competitive market, businesses are turning to AI and Machine and Deep Learning, in particular, to turn enormous data into actionable insights that will help them better engage their target audiences. We broke this barrier by introducing the NVIDIA CUDA framework, allowing for more widespread use of GPU resources. CUDA(Compute Unified Device Architecture) is a C-based API that allows developers to use GPU computing to do machine learning tasks.
How does deep learning implement modern GPUs
Several deep learning frameworks, such as Pytorch and TensorFlow, were developed when NVIDIA launched CUDA. These frameworks have made GPU processing accessible to recent deep learning implementations by abstracting the complexity of programming directly with CUDA.

Importance of GPUs for Deep Learning
GPUs can perform several computations at the same time. It allows training procedures to be distributed and can considerably speed up machine learning operations. You can get a lot of cores with GPUs and consume fewer resources without sacrificing efficiency or power.
They base the decision to integrate GPUs in your deep learning architecture on various factors:
Memory bandwidth—GPUs, for example, can offer the necessary bandwidth to accommodate big datasets. This is because GPUs have specialized video RAM (VRAM), which allows you to save CPU memory for other operations.
Optimization—one disadvantage of GPUs is that it can be more difficult to optimize long-running individual activities than it is with CPUs.
Dataset size—GPUs can grow more easily than CPUs, allowing you to process large datasets more quickly. The more data you have, the more benefit you may get from GPUs.
Deep Learning GPU Technology
There is a range of GPUs to choose from when adding GPUs into your deep learning implementations, while NVIDIA leads the market. You can choose from consumer-grade GPUs, data center GPUs, and managed workstations among these possibilities.
Graphics Processing Units (GPUs) for Consumers:
Consumer GPUs are insufficient for large-scale deep learning projects, although they can serve as a starting point for implementations. We can use these GPUs to enhance current systems and are excellent for model development and low-level testing.
Why use PyTorch to speed up deep learning with GPUs?
PyTorch is a Facebook project. It is one of the most recent deep learning frameworks built by a Facebook team and released on GitHub in 2017. PyTorch is becoming increasingly popular because of its simplicity, ease of use, dynamic computational graph, and economical memory utilization, all of which we’ll go over in further depth later.
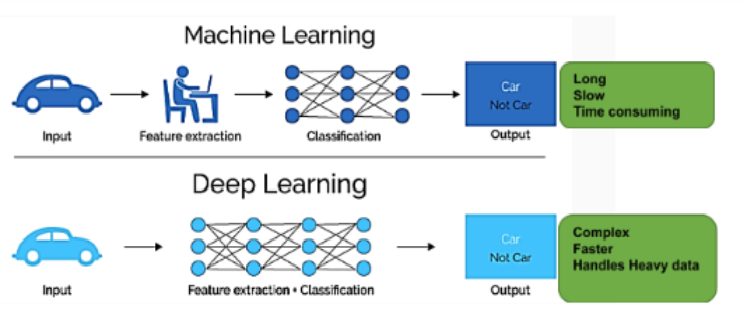
It’s Pythonic, and while it comes with caveats and best – practices, like any complex domain, using the library should feel comfortable for developers who have used Python before. PyTorch is used to store numbers, vectors, matrices, and arrays. It also includes functions for working with them. We can program with them progressively and interactively if we wish, just like we can with Python. If you’re familiar with NumPy, this will be a breeze.
Is PyTorch a deep learning framework?
PyTorch is a Python-based open-source machine learning package built primarily by Facebook’s AI research team. PyTorch enables both CPU and GPU computations in research and production, as well as scalable distributed training and performance optimization. Deep learning is a subfield of machine learning, and the libraries PyTorch and TensorFlow are among the most prominent. Deep learning divides algorithms into layers, generating deep artificial neural networks that can learn and decide on their own, similar to how human brains do.
Key features of PyTorch in deep learning
PyTorch is a Python-based machine learning framework that is open source. With the help of graphics processing units, you may execute scientific and tensor computations (GPUs). It may build and train deep learning neural networks that use automatic differentiation (a calculation process that gives exact values in constant time).
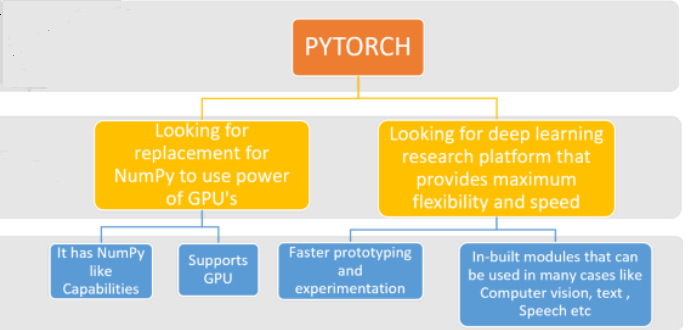
The following are some of PyTorch’s key features:
User Friendly—PyTorch has a steeper learning curve when compared to TensorFlow. PyTorch will take less time to become used to for Python programmers because it will most likely feel like an extension of Python’s framework. Easy debugging and a great set of straightforward APIs go a long way toward making PyTorch more approachable to programmers.
Simple user interface—includes an easy-to-use API that works with Python, C++, and Java. Tensor data structures, CPU and GPU operations, basic parallel primitives, and automatic differentiation calculations are all implemented using the PyTorch core. Because the core handles the most intensive computational tasks, they can be implemented in the fast C++ programming language to improve performance.
Pythonic in nature—smoothly integrates with the Python data science stack and allows you to use Python services and functionalities. PyTorch is a popular framework that allows us to build more pythonic code. When compared to any other library, it has a stronger preference for Python. PyTorch is popular because it is simple to learn and feels more natural, native, and in line with Python code.
Debugging Made Simple—When you access each line and the traditional technique of printing after each line, PyTorch is ridiculously easy to debug. The cherry on top is that PyTorch objects and operations contain actual data rather than symbolic references, making programming easier. ipdb, pdb, and PyCharm are some of the standard debuggers for PyTorch.
Dynamic Computational Graphs—PyTorch provides a dynamic approach to constructing computation graphs by considering each model as a Directed Acyclic Graph. While other frameworks allow you to define a static graph, PyTorch allows you to create a dynamic computation graph that you can alter on the go. Recurrent Neural Networks, for example, are one of the elements that gain the most from PyTorch’s dynamic aspect.
Useful Libraries—With a strong sense of community, comes a lot of excitement and contributions to the community. Programmers have produced some projects using PyTorch, which are available for anyone interested to look at. The following is a list of a few of these projects from diverse disciplines, including Computer Vision, Natural Language Processing, and Generative Libraries:
1) ParlAI allows you to share, train, and test dialogue models.
2) OpenNMT-py is a Python package that implements a neural machine translation system.
3) BoTorch is a tool for doing Bayesian optimizations.
Useful for Resource—PyTorch has proven to be a godsend for academics, with at least 70% of those working on frameworks using it. TensorFlow hasn’t yet caught up to PyTorch despite being the industry-leading choice for developing applications. One reason for this could be PyTorch’s simplicity and ease of use, as well as its superior performance.
Parallelism of data—PyTorch’s data parallelism is efficient, allowing you to divide data into batches and send them to many GPUs for processing. PyTorch can shift a considerable portion of the workload from the CPU to the GPU using this technique. It takes advantage of the torch for data parallelism. torch.nn.DataParallel is a data-parallel class.
Community Support is Strong—PyTorch also has a fantastic user community. Forum’s main page contains extensive documentation for each of its capabilities. PyTorch Forum is a fantastic and highly recommended area for newcomers to ask questions and experienced programmers to discuss their ideas with other programmers. The community is quite active, with over a hundred posts per day, and it encourages people to use PyTorch.
CUDA Support in PyTorch
NVIDIA created the CUDA programming model and computing toolkit. By parallelizing activities across GPUs, you can perform compute-intensive procedures quicker. Although other solutions, such as OpenCL, are available, CUDA is the most popular deep learning API. The torch.cuda package in PyTorch includes CUDA functionality.
Steps to be followed while using CUDA with PyTorch:
PyTorch installation:
macOS and Linux
pip3 install torch torchvision● Windows
pip3 install https://download.pytorch.org/whl/cu90/torch-1.1.0-cp36-cp36m-win_amd64.whlpip3 install https://download.pytorch.org/whl/cu90/torchvision-0.3.0-cp36-cp36m-win_amd64.whl
To get started with PyTorch and CUDA, you’ll need to know a few basic instructions. The most basic of these commands allow you to check whether you have the necessary CUDA libraries and NVIDIA drivers installed, as well as whether you have a GPU to work with. The following command can confirm this:
torch.cuda.is_available()
If you receive a positive result for the above query, you can proceed with the next step below.
The to() function to move tensors:
A to() member function is allocated to each Tensor you create. This function applies the supplied tensor to the device you specify, which can be either the CPU or the GPU. You must use a torch. device object as an input when using this function. This object could be:
CPU
Cuda:{number ID of GPUs}
When a tensor is created, It is frequently placed on a CPU. Then, if you need to speed up calculations, you can switch it to GPU. The code block below shows how to assign this placement.
if torch.cuda.is_available(): dev = "cuda:0" else: dev = "cpu" device = torch.device(dev) a = torch.zeros(10,3) a = a.to(device)
The cuda() function to move tensors around:
To put tensors, you can use cuda(). The index of the GPU you want to use is sent as an argument to this method; it defaults to 0. You can put your complete network on a single device by using this feature. A code block that accomplishes this is shown below.
clf = myNetwork1()
clf.to(torch.device("cuda:0"))
Make careful you use the same device for tensors and tensors and tensors and tensors and
Although being able to specify which GPUs to utilize for your tensors is useful, you don’t want to relocate all of your tensors manually. Instead, try to construct tensors on a single device automatically. This helps to avoid cross-device transfers and the time lost because of them.
The torch.get device() function can assign tensors automatically. This method returns the GPU index and is only supported by GPUs. This index can then be used to guide the placement of new tensors. The following code demonstrates how to utilize this method.
prev = t1.get_device() later = torch.tensor(prev.shape).to(dev)
Make careful you use the same device for tensors and tensors and tensors and tensors and
Calling cuda() and setting the desired default is another approach.
torch.cuda.set_device({GPU ID})
CUDA SEMANTICS
To build up and run CUDA operations, use a torch.cuda. It remembers which GPU is currently selected, and the default will produce all CUDA tensors you allocate on that device.
Copy_() and other methods with copy-like functionality, such as to() and cuda(), are the only ways that support cross-GPU operations by default (). Any efforts to run operations on tensors scattered over several devices will fail unless peer-to-peer memory access is enabled.
cuda = torch.device('cuda')
cuda0 = torch.device('cuda:0')
cuda2 = torch.device('cuda:2')
x = torch.tensor([1., 2.], device=cuda0)
# x.device is device(type='cuda', index=0)
y = torch.tensor([1., 2.]).cuda()
# y.device is device(type='cuda', index=0)
with torch.cuda.device(1):
# allocates a tensor on GPU 1
a = torch.tensor([1., 2.], device=cuda)
# transfers a tensor from CPU to GPU 1
b = torch.tensor([1., 2.]).cuda()
b2 = torch.tensor([1., 2.]).to(device=cuda)
c = a + b
# c.device is device(type='cuda', index=1)
z = x + y
# z.device is device(type='cuda', index=0)
d = torch.randn(2, device=cuda2)
e = torch.randn(2).to(cuda2)
f = torch.randn(2).cuda(cuda2)
Asynchronous execution
GPU operations are asynchronous by default. When you call a GPU-based function, the actions are queued and sent to the device, but they aren’t always executed right away. This enables us to run more computations in parallel, including those on the CPU and other GPUs.
(1) Each device executes operations in the order they are queued, and (2) PyTorch automatically achieves essential synchronization when moving data between CPU and GPU or between two GPUs, the effect of asynchronous processing is imperceptible to the caller. As a result, computation will proceed as though all operations were carried out synchronously.
Time measurements without synchronizations are inaccurate as a result of asynchronous computing. To gain precise measurements, either use torch.cuda or call torch.cuda.synchronize() before measuring. It will time the following event:
start_event1 = torch.cuda.Event(enable_timing=True) end_event1 = torch.cuda.Event(enable_timing=True) start_event1.record() # Run some things here end_event.record() torch.cuda.synchronize() elapsed_time_ms = start_event.elapsed_time(end_event)
Best practices
Agnostic-Device code
Because of PyTorch’s structure, you may need to write device-agnostic (CPU or GPU) code manually; for example, constructing a new tensor as the hidden state of a recurrent neural network.
The first step is to determine whether to use the GPU. Using Python’s argparse module to read in user arguments and having a flag that may be used with is available to deactivate CUDA is a popular practice (). The torch.device object returned by args.device can be used to transport tensors to the CPU or CUDA.
import argparse
import torch
parser = argparse.ArgumentParser(description='PyTorch Example')
parser.add_argument('--disable-cuda', action='store_true',
help='Disable CUDA')
args = parser.parse_args()
args.device = None
if not args.disable_cuda and torch.cuda.is_available():
args.device = torch.device('cuda')
else:
args.device = torch.device('cpu')
We can use args.device to create a Tensor on the specified device now that we have it.
x = torch.empty((8, 42), device=args.device)
net = Network().to(device=args.device)
This can be used to generate device-independent code in a variety of situations. Here’s an example of how to use a data loader:
cuda0 = torch.device('cuda:0') # CUDA GPU 0
for i, x in enumerate(train_loader):
x = x.to(cuda0)
ABOUT MYSELF:
Hello, my name is Lavanya, and I’m from Chennai. I am a passionate writer and enthusiastic content maker. The most intractable problems always thrill me. I am currently pursuing my B. Tech in Chemical Engineering and have a strong interest in the fields of data engineering, machine learning, data science, and artificial intelligence, and I am constantly looking for ways to integrate these fields with other disciplines such as science and chemistry to further my research goals.
Linkedin URL: https://www.linkedin.com/in/lavanya-srinivas-949b5a16a/
Conclusion:
I hope you found this blog post interesting! You should now be familiar with GPUs. Add your opinion in the comment section. Thank you!
Image Sources
- Image 1 – https://miro.medium.com/max/875/1*3Tvx32LZyEut7fZY9bilQQ.png