



This article was published as a part of the Data Science Blogathon
Introduction
In Machine learning or Deep Learning, some of the models such as Linear Regression, Logistic Regression, Artificial Neural Networks assume that features are normally distributed and can perform much better if the features provided to them during modeling are normally distributed.
But the data provided to us does not necessarily follow a normal distribution. So what should we do in such cases? That’s what we are going to cover in this article.
Table of Content
- A brief introduction to Gaussian Distribution
- How to check if a variable is following Gaussian Distribution
- Various Transformations to change the distribution of features
- Log Transformation
- Square root Transformation
- Reciprocal Transformation
- Exponential Transformation
- Box-Cox Transformation
Introduction to Gaussian Distribution
In probability theory, a normal (or Gaussian) distribution is a type of continuous probability distribution for a real-valued random variable. The general form of its probability density function is

{kind=link}
Samples of the Gaussian Distribution follow a bell-shaped curve and lies around the mean. The mean, median, and mode of Gaussian Distribution are the same.
To read more about Normal/Gaussian Distribution in detail, refer to the attached article.
How to check if a variable is following Normal Distribution
There are various ways in which we can check the distribution of the variables. Some of them are:
- Histogram
- Q-Q plot
- KDE plot
- Skewness and Kurtosis
- Five Number Summary (This one just gives the glimpse and not the entire detail. Check out my blog if you want to know more about this concept)
We will see all the above-mentioned methods with the help of a dataset. For this, we will use a subset of Car price dataset where categorical variables will be excluded for now and will check the distributions on numerical variables.
Python Code:
Checking the distribution with Skewness
#skewness in the data cp.skew()
Output:
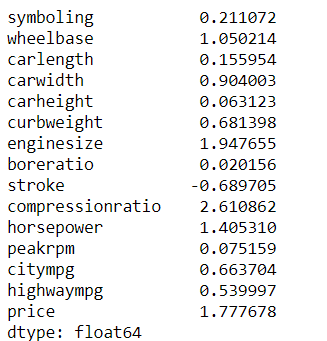
From the above result, we can check which variable is normally distributed and which is not.
- The variables with skewness > 1 such as wheelbase, compressionratio, horsepower, price are highly positively skewed.
- The variables with skewness < -1 are highly negatively skewed.
- The variables with 0.5 < skewness < 1 such as carwidth, curbweight, citympg are moderately positively skewed.
- The variables with -0.5 < skewness < -1 such as stroke are moderately negatively skewed.
- And, the variables with -0.5 < skewness < 0.5 are symmetric i.e normally distributed such as symboling, carheight, boreration, peakrpm, highwaympg.
Checking the distribution of some variables using Histogram
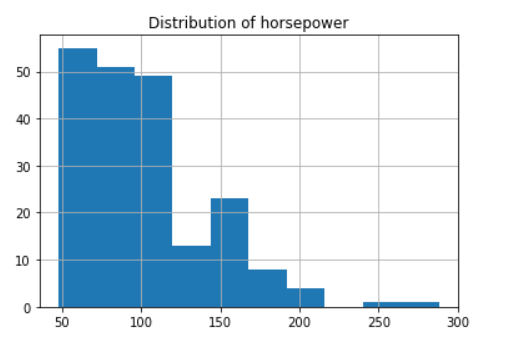
cp.horsepower.hist()
plt.title('Distribution of horsepower');
Output: Highly positive Skewed i.e does not follow a normal distribution
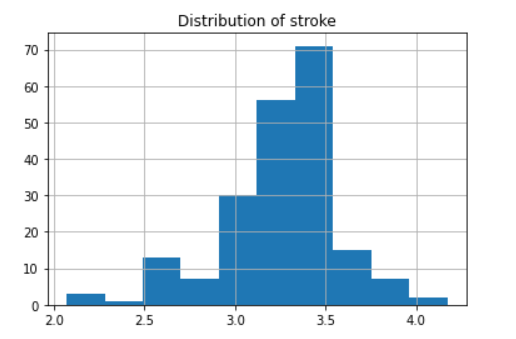
cp.stroke.hist()
plt.title('Distribution of stroke');
Output: Moderately negatively Skewed i.e does not follow a normal distribution
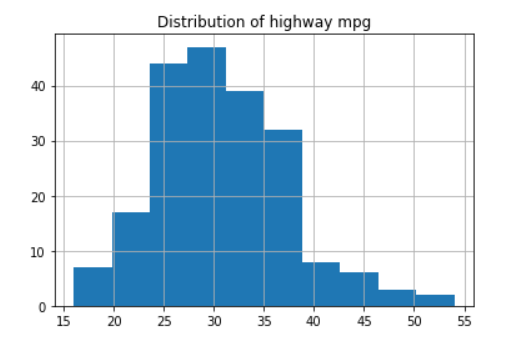
cp.highwaympg.hist()
plt.title('Distribution of highway mpg');
Output: Symmetric i.e does follow a normal distribution
Checking the distribution of variables using KDE plot
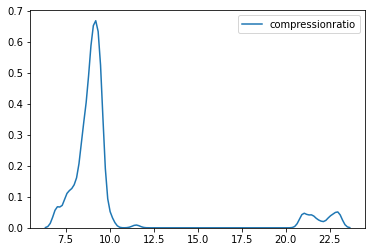
sns.kdeplot(cp.compressionratio);
sns.kdeplot(cp.price);
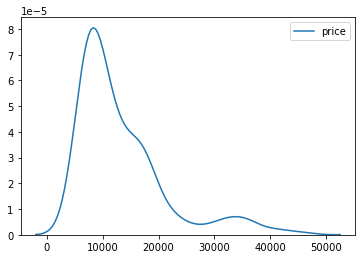
The distribution of both the variables compression ratio and the price is highly positively skewed and is not normally distributed.
Checking the distribution of variables using a Q-Q plot
A Q-Q plot is a scatterplot created by plotting two sets of quantiles against one another. If both sets of quantiles came from the same distribution, we should see the points forming a roughly straight line.
That is, if the data falls in a straight line then the variable follows normal distribution otherwise not.
#importing necessary libraries import scipy.stats as stats import pylab
From the Skewness and KDE plots, we have seen that the price variable is highly positively skewed. Let’s plot the Q-Q plot for the Price variable and check.
stats.probplot(cp.price,plot=pylab);
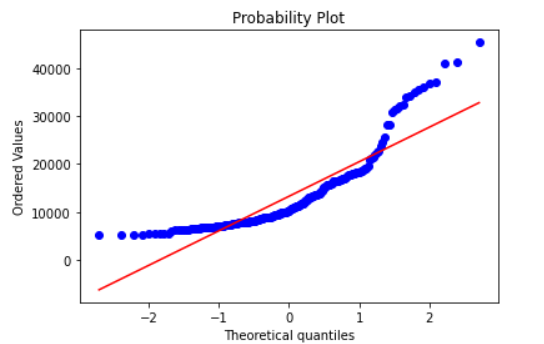
The X-axis of the above plot has Quantiles values and Y-axis has the price values. From the plot, we can analyze that the data points of the price feature are not falling on a straight line. This implies that it does not follow a normal distribution.
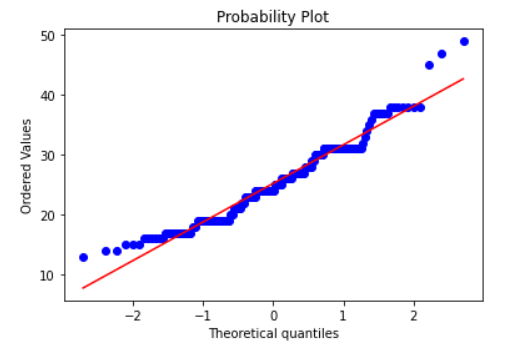
Let’s check for the city mpg feature now. The graph shows that the majority of the data points of city mpg fall on the straight line so the distribution is normal.
stats.probplot(cp.citympg,plot=pylab);
Transformations to change the distribution of features
Till now we have seen how to check the distribution of the feature. This section will learn how to convert the variables into the normal distribution if they are not following it.
For this purpose, we will work on a single feature first and will see which transformation out of all works the best to convert the feature into a normal distribution.
First of all, defining a function in python which will take data and feature name as inputs and return the KDE plot and Q-Q plot of the feature.
#function to return plots for the feature
def normality(data,feature):
plt.figure(figsize=(10,5))
plt.subplot(1,2,1)
sns.kdeplot(data[feature])
plt.subplot(1,2,2)
stats.probplot(data[feature],plot=pylab)
plt.show()
Plotting for the Price feature using the above-defined function:
normality(cp,’price’)
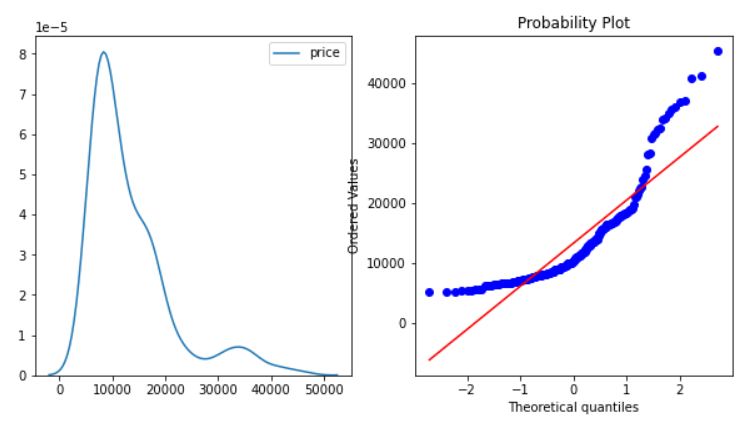
Performing the transformations on the Price variable.
- Logarithmic Transformation – This will convert the Price value to its log value i.e log(Price)
#performing logarithmic transformation on the feature cp['price_log']=np.log(cp['price'])
#plotting to check the transformation normality(cp,'price_log')
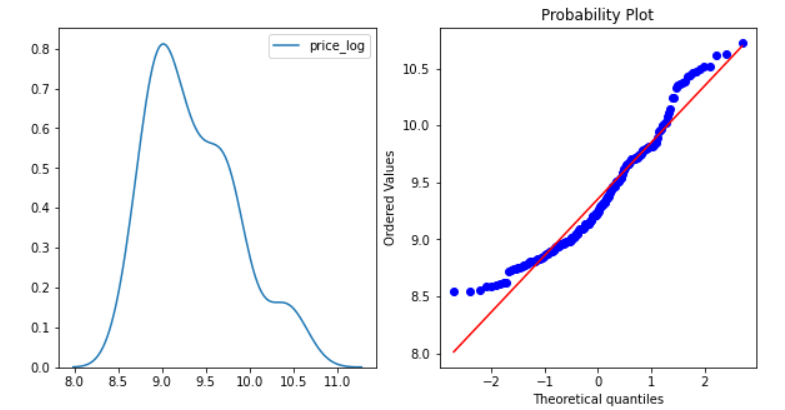
The distribution changed slightly and looks moderately skewed now. More data points are also falling on the line in the Q-Q plot.
- Reciprocal Transformation – This will inverse values of Price i.e1/Price
cp['price_reciprocal']=1/cp.price normality(cp,'price_reciprocal')
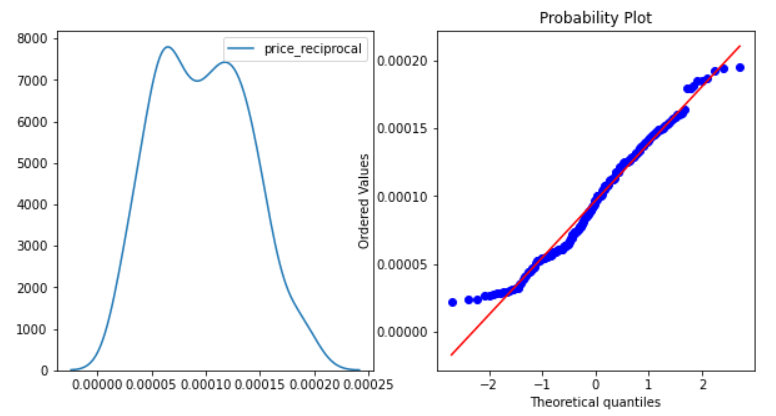
The Reciprocal Transformation has kind of converted the feature to normal distribution. Most of the data points are also falling on the line in the Q-Q plot. This one is better than the log transformation for the Price feature.
- Square Root Transformation – This transformation will take the square root of the Price column i.e sqrt(Price).
cp['price_sqroot']=np.sqrt(cp.price) normality(cp,'price_sqroot')
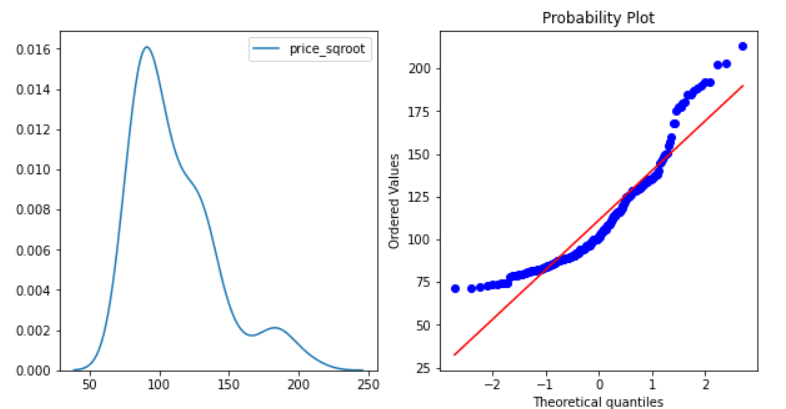
This one has reduced the skewness of the feature but has not transformed it into a normal distribution.
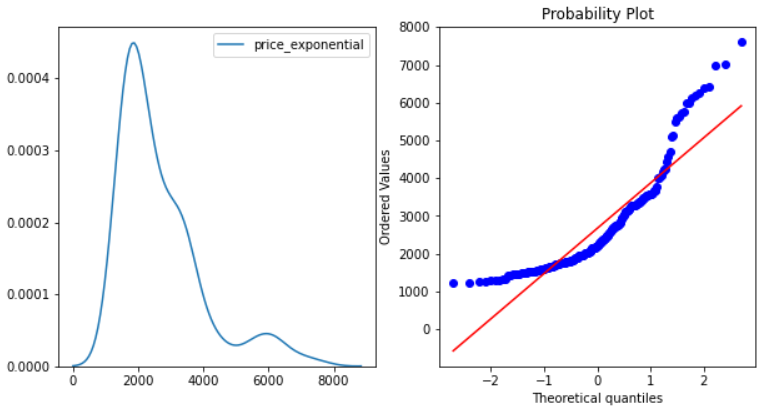
- Exponential Transformation: The exponential value of the Price variable will be taken.
cp['price_exponential']=cp.price**(1/1.2) normality(cp,'price_exponential')
- Box-Cox Transformation – The Box-Cox transformation is defined as:
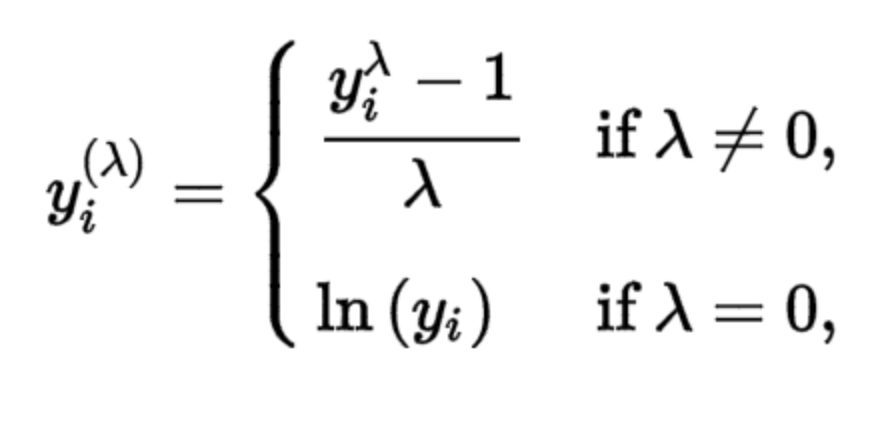
where y is the response variable and λ is the transformation parameter. λ value varies from -5 to 5. During the transformation, all values of λ are considered and the optimal/best value for the variable is selected. log(y) is only applied when λ=0.
cp['price_Boxcox'],parameters=stats.boxcox(cp['price']) normality(cp,'price_Boxcox')
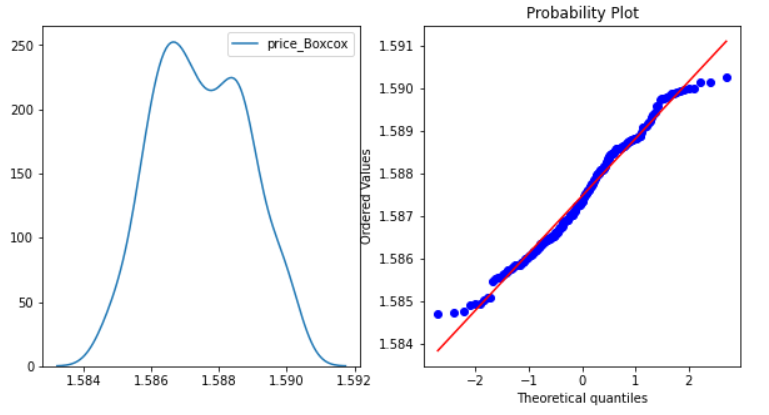
Box cox transformation technique also gives a good result and normally distributes the Price feature. The data points on the Q-Q plot are almost on the line as well.
From all the transformations discussed above, we can conclude that the Box cox and Reciprocal transformation perform the best on the Price variable and transform it to normal distribution. Any one of the two can be used but as Box cox is more logic-based and involves the λ variable which is chosen as per the best skewness for the data so Box cox will be a better transformation to go with.
About the Author
I am Deepanshi Dhingra currently working as a Data Science Researcher, and possess knowledge of Analytics, Exploratory Data Analysis, Machine Learning, and Deep Learning. Feel free to content with me on LinkedIn for any feedback and suggestions.
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.