

Overview
- Learn web scraping in Python using the BeautifulSoup library
- Web Scraping is a useful technique to convert unstructured data on the web to structured data
- BeautifulSoup is an efficient library available in Python to perform web scraping other than urllib
- A basic knowledge of HTML and HTML tags is necessary to do web scraping in Python
Introduction
The need and importance of extracting data from the web is becoming increasingly loud and clear. Every few weeks, I find myself in a situation where we need to extract data from the web to build a machine learning model.
For example, last week we were thinking of creating an index of hotness and sentiment about various data science courses available on the internet. This would not only require finding new courses, but also scraping the web for their reviews and then summarizing them in a few metrics!
This is one of the problems / products whose efficacy depends more on web scraping and information extraction (data collection) than the techniques used to summarize the data.
Note: We have also created a free course for this article – Introduction to Web Scraping using Python. This structured format will help you learn better.
Table of contents
Ways to extract information from web
There are several ways to extract information from the web. Use of APIs being probably the best way to extract data from a website. Almost all large websites like Twitter, Facebook, Google, Twitter, StackOverflow provide APIs to access their data in a more structured manner. If you can get what you need through an API, it is almost always preferred approach over web scraping. This is because if you are getting access to structured data from the provider, why would you want to create an engine to extract the same information.
Sadly, not all websites provide an API. Some do it because they do not want the readers to extract huge information in a structured way, while others don’t provide APIs due to lack of technical knowledge. What do you do in these cases? Well, we need to scrape the website to fetch the information.
There might be a few other ways like RSS feeds, but they are limited in their use and hence I am not including them in the discussion here.
What is Web Scraping?
Web scraping is a computer software technique of extracting information from websites. This technique mostly focuses on the transformation of unstructured data (HTML format) on the web into structured data (database or spreadsheet).
You can perform web scraping in various ways, including use of Google Docs to almost every programming language. I would resort to Python because of its ease and rich ecosystem. It has a library known as ‘BeautifulSoup’ which assists this task. In this article, I’ll show you the easiest way to learn web scraping using python programming.
For those of you, who need a non-programming way to extract information out of web pages, you can also look at import.io . It provides a GUI driven interface to perform all basic web scraping operations. The hackers can continue to read this article!
Libraries required for web scraping
As we know, Python is an open source programming language. You may find many libraries to perform one function. Hence, it is necessary to find the best to use library. I prefer BeautifulSoup (Python library), since it is easy and intuitive to work on. Precisely, I’ll use two Python modules for scraping data:
- Urllib2: It is a Python module which can be used for fetching URLs. It defines functions and classes to help with URL actions (basic and digest authentication, redirections, cookies, etc). For more detail refer to the documentation page. Note: urllib2 is the name of the library included in Python 2. You can use the urllib.request library included with Python 3, instead. The urllib.request library works the same way urllib.request works in Python 2. Because it is already included you don’t need to install it.
- BeautifulSoup: It is an incredible tool for pulling out information from a webpage. You can use it to extract tables, lists, paragraph and you can also put filters to extract information from web pages. In this article, we will use latest version BeautifulSoup 4. You can look at the installation instruction in its documentation page.
BeautifulSoup does not fetch the web page for us. That’s why, I use urllib2 in combination with the BeautifulSoup library.
Python has several other options for HTML scraping in addition to BeatifulSoup. Here are some others:
Basics – Get familiar with HTML (Tags)
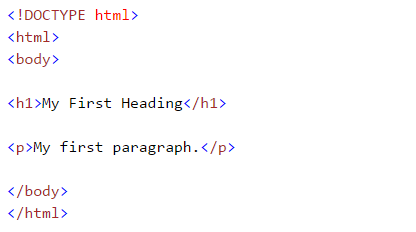
While performing web scarping, we deal with html tags. Thus, we must have good understanding of them. If you already know basics of HTML, you can skip this section. Below is the basic syntax of HTML:This syntax has various tags as elaborated below:
- <!DOCTYPE html> : HTML documents must start with a type declaration
- HTML document is contained between <html> and </html>
- The visible part of the HTML document is between <body> and </body>
- HTML headings are defined with the <h1> to <h6> tags
- HTML paragraphs are defined with the <p> tag
Other useful HTML tags are:
- HTML links are defined with the <a> tag, “<a href=“http://www.test.com”>This is a link for test.com</a>”
- HTML tables are defined with<Table>, row as <tr> and rows are divided into data as <td>

- HTML list starts with <ul> (unordered) and <ol> (ordered). Each item of list starts with <li>
If you are new to this HTML tags, I would also recommend you to refer HTML tutorial from W3schools. This will give you a clear understanding about HTML tags.
Scraping a web page using BeautifulSoup
Here, I am scraping data from a Wikipedia page. Our final goal is to extract list of state, union territory capitals in India. And some basic detail like establishment, former capital and others form this wikipedia page. Let’s learn with doing this project step wise step:
- Import necessary libraries:
#import the library used to query a website
import urllib2 #if you are using python3+ version, import urllib.request#specify the url
wiki = "https://en.wikipedia.org/wiki/List_of_state_and_union_territory_capitals_in_India"#Query the website and return the html to the variable 'page'
page = urllib2.urlopen(wiki) #For python 3 use urllib.request.urlopen(wiki)#import the Beautiful soup functions to parse the data returned from the website
from bs4 import BeautifulSoup#Parse the html in the 'page' variable, and store it in Beautiful Soup format
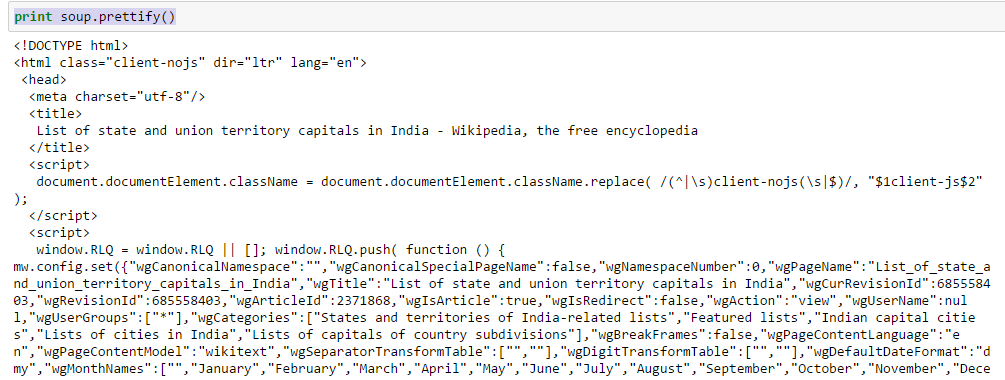
soup = BeautifulSoup(page)- Use function “prettify” to look at nested structure of HTML page
 Above, you can see that structure of the HTML tags. This will help you to know about different available tags and how can you play with these to extract information.
Above, you can see that structure of the HTML tags. This will help you to know about different available tags and how can you play with these to extract information.
- Work with HTML tags
- soup.<tag>: Return content between opening and closing tag including tag.
In[30]:soup.title Out[30]:<title>List of state and union territory capitals in India - Wikipedia, the free encyclopedia</title>
- soup.<tag>.string: Return string within given tag
In [38]:soup.title.string Out[38]:u'List of state and union territory capitals in India - Wikipedia, the free encyclopedia'
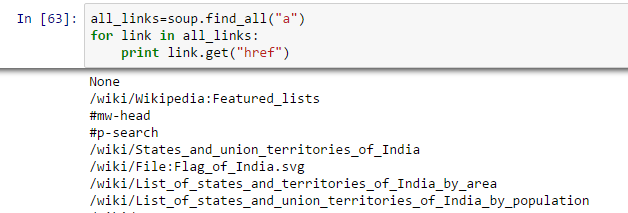
- Find all the links within page’s <a> tags:: We know that, we can tag a link using tag “<a>”. So, we should go with option soup.a and it should return the links available in the web page. Let’s do it.
In [40]:soup.a Out[40]:<a id="top"></a>

Above, you can see that, we have only one output. Now to extract all the links within <a>, we will use “find_all().
Above, it is showing all links including titles, links and other information. Now to show only links, we need to iterate over each a tag and then return the link using attribute “href” with get.
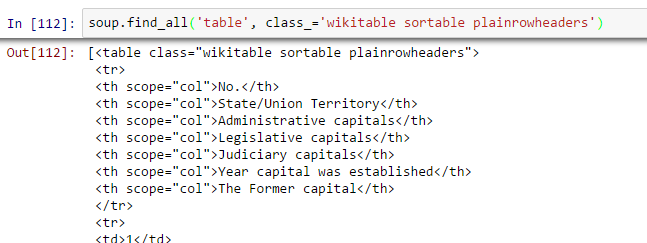
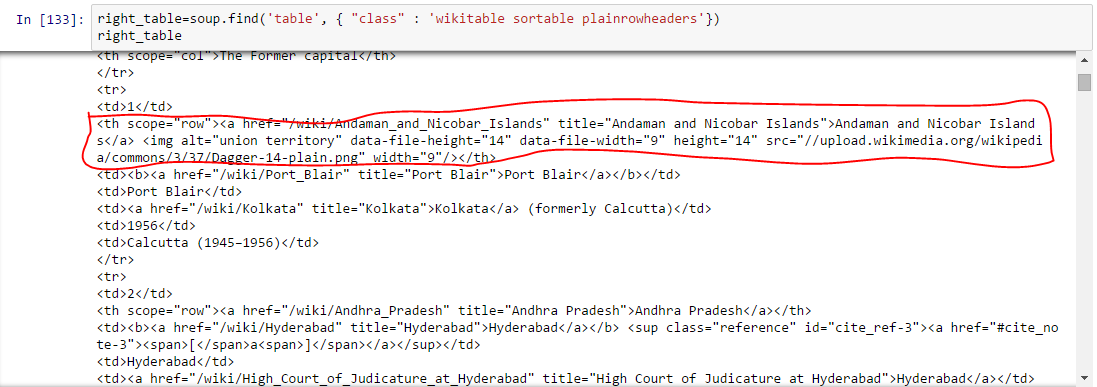
- Find the right table: As we are seeking a table to extract information about state capitals, we should identify the right table first. Let’s write the command to extract information within all table tags.
all_tables=soup.find_all('table')Now to identify the right table, we will use attribute “class” of table and use it to filter the right table. In chrome, you can check the class name by right click on the required table of web page –> Inspect element –> Copy the class name OR go through the output of above command find the class name of right table.
right_table=soup.find(‘table’, class_=’wikitable sortable plainrowheaders’) right_table
 Above, we are able to identify right table.
Above, we are able to identify right table. - Extract the information to DataFrame: Here, we need to iterate through each row (tr) and then assign each element of tr (td) to a variable and append it to a list. Let’s first look at the HTML structure of the table (I am not going to extract information for table heading <th>)
 Above, you can notice that second element of <tr> is within tag <th> not <td> so we need to take care for this. Now to access value of each element, we will use “find(text=True)” option with each element. Let’s look at the code:
Above, you can notice that second element of <tr> is within tag <th> not <td> so we need to take care for this. Now to access value of each element, we will use “find(text=True)” option with each element. Let’s look at the code:
{kind=link}
#Generate lists
A=[]
B=[]
C=[]
D=[]
E=[]
F=[]
G=[]
for row in right_table.findAll("tr"):
cells = row.findAll('td')
states=row.findAll('th') #To store second column data
if len(cells)==6: #Only extract table body not heading
A.append(cells[0].find(text=True))
B.append(states[0].find(text=True))
C.append(cells[1].find(text=True))
D.append(cells[2].find(text=True))
E.append(cells[3].find(text=True))
F.append(cells[4].find(text=True))
G.append(cells[5].find(text=True))
#import pandas to convert list to data frame
import pandas as pd
df=pd.DataFrame(A,columns=['Number'])
df['State/UT']=B
df['Admin_Capital']=C
df['Legislative_Capital']=D
df['Judiciary_Capital']=E
df['Year_Capital']=F
df['Former_Capital']=G
df
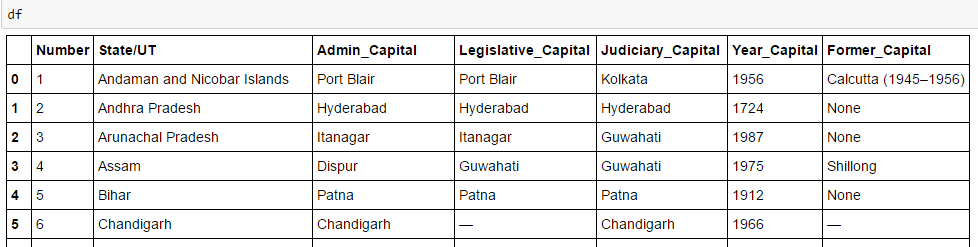
Finally, we have data in dataframe:
Similarly, you can perform various other types of web scraping using “BeautifulSoup“. This will reduce your manual efforts to collect data from web pages. You can also look at the other attributes like .parent, .contents, .descendants and .next_sibling, .prev_sibling and various attributes to navigate using tag name. These will help you to scrap the web pages effectively.-
But, why can’t I just use Regular Expressions?
Now, if you know regular expressions, you might be thinking that you can write code using regular expression which can do the same thing for you. I definitely had this question. In my experience with BeautifulSoup and Regular expressions to do same thing I found out:
- Code written in BeautifulSoup is usually more robust than the one written using regular expressions. Codes written with regular expressions need to be altered with any changes in pages. Even BeautifulSoup needs that in some cases, it is just that BeautifulSoup is relatively better.
- Regular expressions are much faster than BeautifulSoup, usually by a factor of 100 in giving the same outcome.
So, it boils down to speed vs. robustness of the code and there is no universal winner here. If the information you are looking for can be extracted with simple regex statements, you should go ahead and use them. For almost any complex work, I usually recommend BeautifulSoup more than regex.
Conclusion
In this article, we looked at web scraping methods using “BeautifulSoup” and “urllib2” in Python. We also looked at the basics of HTML and perform the web scraping step by step while solving a challenge. I’d recommend you to practice this and use it for collecting data from web pages.
Did you find this article helpful? Please share your opinions / thoughts in the comments section below.
Note: We have also created a free course for this article – Introduction to Web Scraping using Python. This structured format will help you learn better.
If you like what you just read & want to continue your analytics learning, subscribe to our emails, follow us on twitter or like our facebook page.
Frequently Asked Questions
1. Install BeautifulSoup: pip install beautifulsoup4
2. Use it to parse HTML content and extract data.
3.Example code:
from bs4 import BeautifulSoup
import requests
url = ‘https://example.com’
response = requests.get(url)
html_content = response.content
soup = BeautifulSoup(html_content, ‘html.parser’)
links = soup.find_all(‘a’)
for link in links:
print(link.get(‘href’))
1.”BS4″ stands for BeautifulSoup version 4, the latest version of the library.
2.BeautifulSoup is a Python library for web scraping.
3.It simplifies parsing HTML and XML to extract desired data.
1.BeautifulSoup is widely used and user-friendly.
2. Whether it’s the best depends on the project needs.
3.Other options like Scrapy, lxml, and Selenium also suit specific requirements. Choose based on project complexity and preferences.
I am a Business Analytics and Intelligence professional with deep experience in the Indian Insurance industry. I have worked for various multi-national Insurance companies in last 7 years.