



{kind=link}
This article was published as a part of the Data Science Blogathon.
Introduction
An ultimate beginners guide on Apache Spark & RDDs!
As we all have observed, the growth of data how helps the companies to get insights into data, and that insight is used for the growth of Business. Personal assistants like Alexa, Siri, and Google Home uses Big Data and IoT technologies to gather data and get answers.
In this article, we will discuss the role of Pyspark in big data and how it influences the big-data ecosystem, and we will get some hands-on experience with Pyspark.
Due to the increasing demand for data-driven technologies, data grows so rapidly that we need to process these enormous amounts of data using fast computers.
Processing of Big Data:
Big data can be processed in two ways, either using a powerful computer or by using a distributed computer system that works parallel. Since a large volume of data can’t be processed using a single computer.
Parallel Computation:
In simple words, the processing tasks workload is divided and run independently. If any single computer(Node) is failed to process the data, other nodes take the job.
A distributed system cluster is a collection of Node (single computer) that works together in synchronization.
Open-Source projects like Hadoop projects and big data tools like Apache Hive and Apache Spark run the world of big data since they are free and completely transparent.
Big Data EcoSystem:
The big data ecosystem requires work on various tools according to their need. It requires cloud management, Data processing tools, Databases, Business intelligence tools, and Programming language.
These are the categorized tools required
- Programming Tools
- Databases (NoSql and SQL )
- Business Intelligence tools
- Data technologies
- Analytics and visualization
- Cloud Technologies
Hadoop Ecosystem:
There are components that support one another
- Ingest Data( Flume , Sqoop)
- Store Data (HDFS, HBase)
- Process and Analyze Data (Pig & Hive)
- Access Data ( Impala, Hue)
Why Spark?
Companies like Uber, Netflix, Tencent, and Alibaba all run Apache spark operations.
Spark is a powerful complement to Apache Hadoop. Spark is more powerful, accessible, and capable of processing massive amounts of data in the distributed system.
Spark is an open-source application that is based on the in-memory framework for distributed data processing on massive data volumes.
Top Features of Apache Spark:

These are the top features of apache spark that make it widely popular.
1) Fast Processing
Spark has set the world record for on-disk data sorting. It processes data 100x faster in memory and 10 times faster in the Hadoop cluster.
2) Supports various APIs
Spark applications can be written in various programming languages like SCALA, JAVA, PYTHON, R, CLOJURE. Spark supports various high-level language APIs that make it easier to work on it.
Spark Core is a base engine for spark; it performs large-scale distributed and parallels data processing, its fault-tolerant means if a node goes down, it doesn’t stop processing. It contains various elements that are able to work in a parallel way across the cluster.
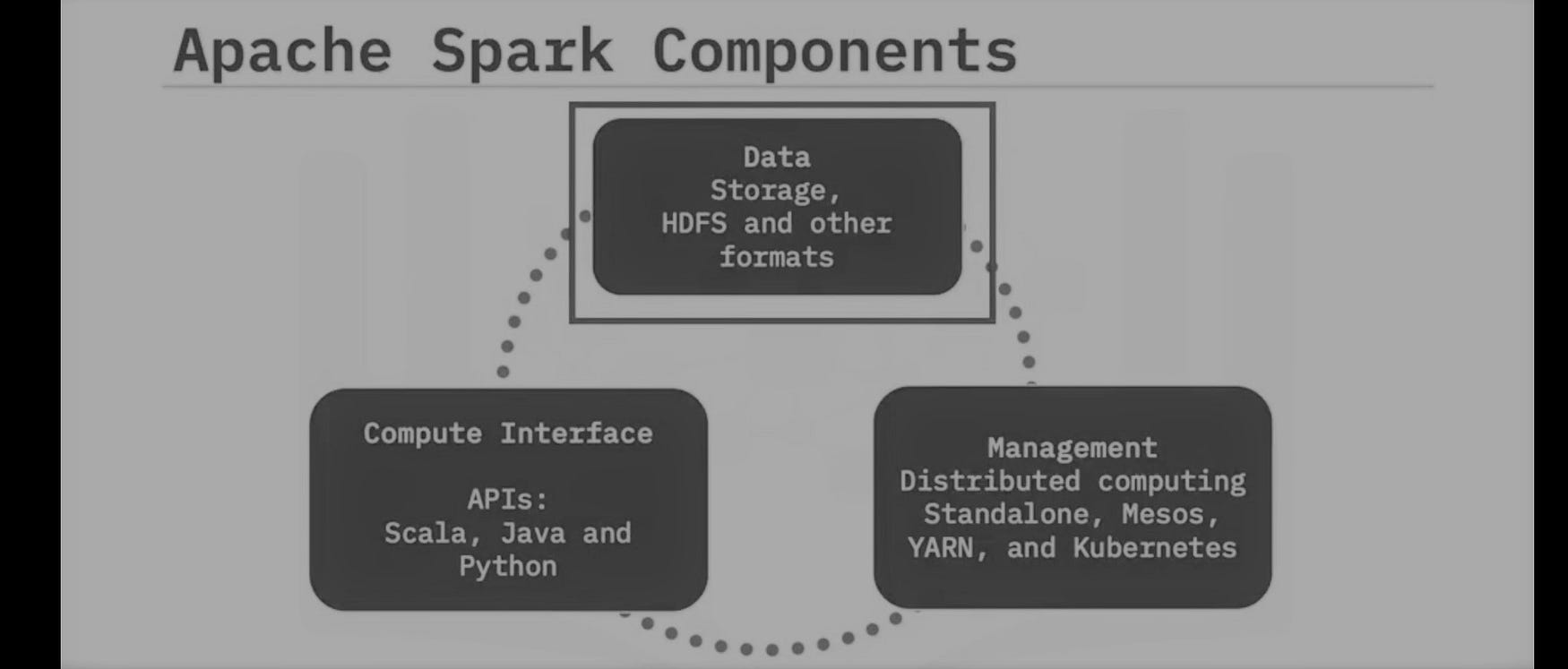
In this article, we will work on Spark using Python API.
3) PowerFul libraries
It supports Map-Reduce functions; It facilitates SQL and data frames. It provides MLlib for machine learning tasks and Spark Streaming which is made for real-time data analytics.
4) Real-Time Processing
Spark supports MapReduce, which is capable of processing data stored in the Hadoop cluster and HDFS files. Spart streaming can handle real-time data.
5) Compatibility and Deployment
Spark is able to run on Hadoop, Kubernetes, Mesos, or in any cloud services really easily.
Apache Spark Run-Time Architecture
Apache spark contains 3 high-level components.
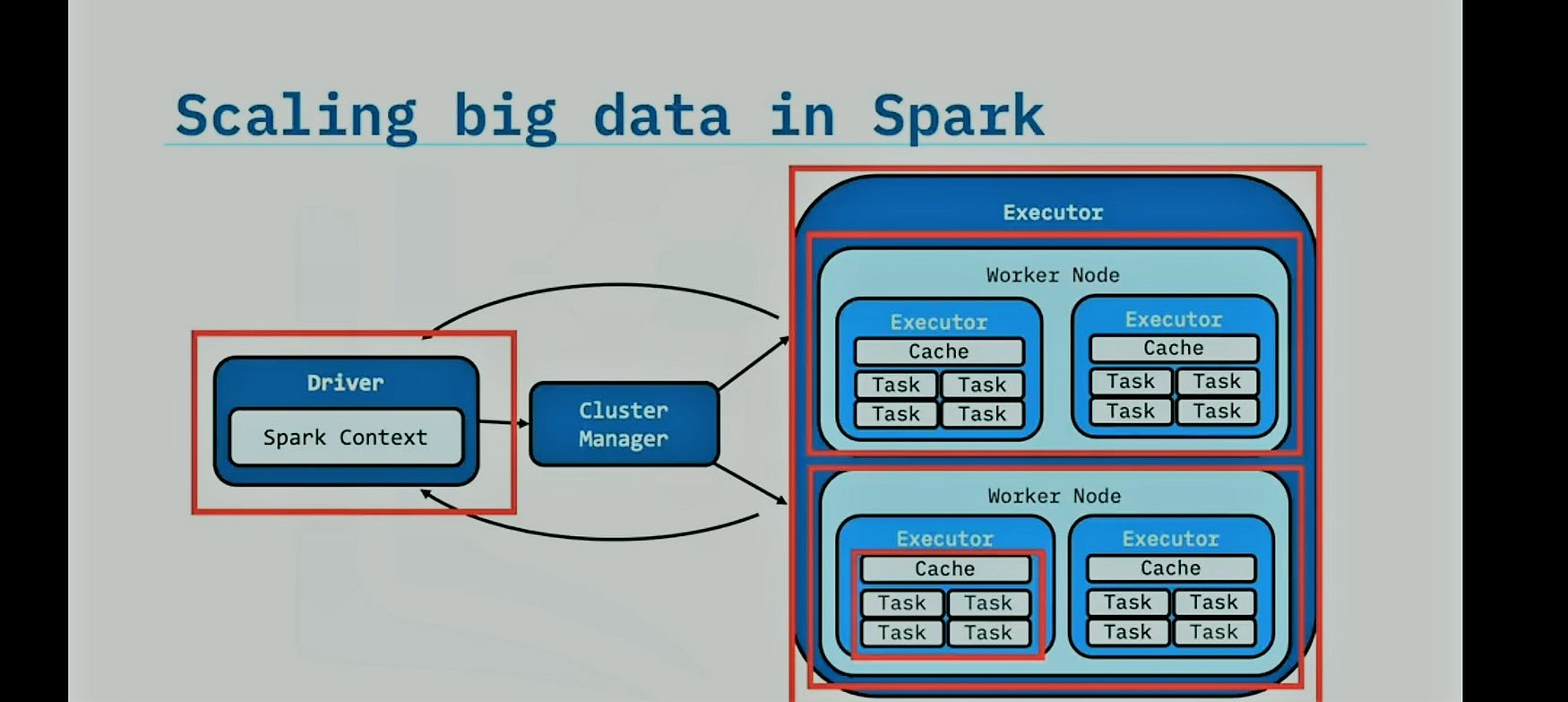
- Spark Driver
- Cluster Manager
- Executors
Getting Started with Apache Spark with Python
Spark is originally written in Scala that compiles in java bytecode, but we can write python code to communicate with JVM (java virtual machine) using py4j. Hence we can write spark applications using python.
Objectives
- Start Pyspark
- Initialize context and session
- Create RDD
- Apply transformation and actions
- Caching
For Running Spark, you can choose any cloud notebook, but I highly encourage you to create a data-bricks spark cluster; this is a step-by-step guide on how to spin spark clusters on data-bricks for free.
PySpark is the Spark API made for python. In this article, we will use Pyspark to initialize and work on Spark
Installing required packages.
!pip install pyspark
!pip install findspark
Findspark It adds a startup file to the current IPython profile and makes the environment ready for running Spark.
import findspark
findspark.init()
Creating the Spark Context and Spark Session.
Spark session is needed for SparkSQL and Dataframes.
SparkContext is the entry point for Spark applications and it contains functions to create RDDs(Resilient distributed databases) likeparallelize().
# Initialization spark context class
sc = SparkContext()
# Create spark session
spark = SparkSession
.builder
.appName("Python Spark DataFrames basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate()
Initialize Spark Session
After Creating Spark Context we need to verify the spark session instance which is just has been created.
spark

Spark RDDs
RDDs are primitive data abstraction in spark, and we use functional programming concepts to work with RDDs.
RDD supports various types of files, including —
- Text, Sequence Files, Avro, Parquet, Hadoop inputs, etc.
- Cassandra, HBase, HDFS, Amazon S3, etc.
RDDs are immutable in order to maintain data integrity. RDDs work in a parallel distributed way.
RDDs work in a distributed way; RDDs are partitioned across the nodes of the cluster.
RDDs support lazy evaluation means it won’t apply any transformation until we call the action.
For example, we are creating an RDD in spark by calling the function parallelize.
sc.parallelize takes data list and converts it into RDD.
data = range(1,30) # print first element of iterator print(data[0]) len(data) xrangeRDD = sc.parallelize(data, 4) # This will make sure if RDD has created xrangeRDD
RDD Transformation
As we discussed that RDDs are immutable; when we apply a transformation, it returns a new RDD. RDD is lazy evaluated means no calculation is carried out when a new RDD is generated. New RDD will contain some series of rules of transformation. As soon as we call an action all transformation gets executed.
# Reduces each number by 1 subRDD = xrangeRDD.map(lambda x: x-1)
# selects all number less than 10 filteredRDD = subRDD.filter(lambda x : x<10)
Calling Action
When we call an action on RDD our RDD instantly performs all the series of transformations and returns the result.
print(filteredRDD.collect()) filteredRDD.count()

Caching Data
Caching in Spark Improves the speed up to 20 times. We can cache our RDD for faster transformation and processing. Let’s observe the result after caching and before caching.
import time
test = sc.parallelize(range(1,50000),4)
test.cache()
t1 = time.time()
# first count will trigger evaluation of count *and* cache
count1 = test.count()
dt1 = time.time() - t1
print("dt1: ", dt1)
t2 = time.time()
# second count operates on cached data only
count2 = test.count()
dt2 = time.time() - t2
print("dt2: ", dt2)
#test.count()

dt1 is the time is taken before caching and dt2 is the time taken after caching.
Conclusion:
In this article, we discussed the word Big Data and the various categories of tools required for big data. We saw the Hadoop ecosystem and How it works, and we also discussed Running Apache spark with python and creating RDDs.
This was just the beginning of Spark; in the upcoming article, we will discuss the following concepts:
- DataFrames and SparkSQL
- Spark Streaming
- Running Spark on Kubernetes.
Thanks for reading this article !!