



{kind=link}
This article was published as a part of the Data Science Blogathon.
Introduction
Today, we expect web applications to respond to user queries quickly, if not immediately. As applications cover more aspects of our daily lives, it is increasingly difficult to provide users with a quick response.
Caching is used to solve a wide variety of these problems, but applications require real-time data in many situations. In addition, we have data to be aggregated, enriched, or otherwise transformed for further consumption or further processing. In these cases, Kafka is helpful.
What is Apache Kafka?
It is an open-source platform that ingests and processes streaming data in real time. Streaming data is generated simultaneously by thousands of data sources every second. Apache Kafka uses a Subscribe and Publish model for reading and writing streams of records. Unlike other messaging systems, Kafka has built-in sharding, replication, higher throughput, and is more fault-tolerant, making it an ideal solution for processing large volumes of messages. More about Kafka integration
What is Apache Kafka Used For?
Kafka Use Cases are numerous and found in various industries such as financial services, manufacturing, retail, gaming, transportation and logistics, telecommunications, pharmaceuticals, life sciences, healthcare, automotive, insurance, and more. Kafka is used wherever large-scale streaming data is processed and used for reporting. Kafka use cases include event streaming, data integration and processing, business application development, and microservices. Kafka can be used in the cloud, multi-cloud and hybrid deployments. 6 Reasons to Automate Your Data Pipeline
Kafka Use Case 1: Tracking web activity
Kafka can be used to monitor user activity by creating channels to monitor user activity with real-time publish and subscribe channels. Pages viewed, user searches, user registrations, subscriptions, comments, transactions, etc. can be written to topics and made available for real-time processing for data warehouse analytics on platforms like Snowflake, Amazon Redshift, Amazon S3, ADLS Gen2, Azure Synapse, SQL Server, etc.
Kafka Use Case 2: Operational Metrics
Kafka can report operational metrics when used in operational data feeds. It also collects data from distributed applications to enable alerts and reports for operational metrics by creating centralized data sources of operations data.
Kafka Use Case 3: Aggregating Logs
Kafka collects logs from different services and makes them available in a standard format to multiple consumers. Kafka supports low-latency processing and multiple data sources, which is great for distributed data consumption.
Use Case 4: Stream Processing
In data warehousing systems where data is stored and then processed, you can now process data as it comes in – this is real-time data processing. Real-time processing of data streams, if done continuously, simultaneously, and in a sequence of records, is Kafka stream processing. Real-time stream processing means that Kafka reads data from a topic (source), performs some transformation or analysis, and writes the result to another topic (sink), which applications and users can consume.
How Does Apache Kafka Work?
It is known as an event streaming platform because you can:
• Publish, i.e., write event streams, and Subscribe, i.e., read event streams, including continuous import and export of data from other applications.
• Reliably store event streams for as long as you want.
• Processing of events stream when they occur or after.
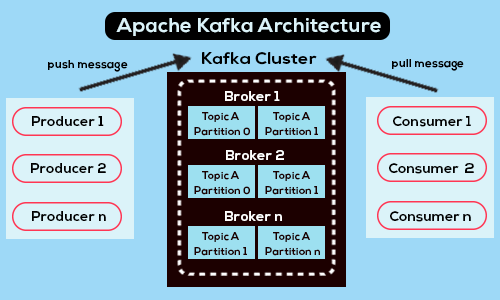
Kafka is highly scalable, elastic, secure, and has a data-distributed publish-subscribe messaging system. The distributed system has servers and clients that work through the TCP network protocol. This TCP (Transmission Control Protocol) helps in transferring data packets from source to destination between processes, applications, and servers. A protocol establishes a connection before communication between two computing systems on a network occurs. Kafka can be deployed on virtual machines, bare hardware, on-premise containers, and in cloud environments.
Kafka’s Architecture – The 1000 Foot View
• Brokers (nodes or servers ) handle client requests for production, consumption, and metadata and enable data replication in clusters. Their several Brokers that can be more than one in a cluster.
• Zookeeper maintains cluster state, topic configuration, leader election, ACLs, broker lists, etc.
• Producer is an application that creates and delivers records to the broker.
• A consumer is a system that consumes records from a broker.
Kafka producers and consumers
Kafka Producers are essentially client applications that publish or write events to Kafka, while Kafka Consumers are systems that receive, read, and process those events. Kafka Producers and Kafka Consumers are completely separate, and they have no dependency. It is one important reason why Apache Kafka is so highly scalable. The ability to process events exactly once is one of Kafka’s guarantees.
Kafka’s themes
A Kafka topic is a category that helps organize and manage messages. The topic will have a unique name within a Kafka group. Messages are sent and read from individual Topics. Kafka producers write data to a topic, and a Kafka consumer reads data from a topic. A Kafka topic can have zero to more subscribers. Each Kafka topic is split and replicated through different Kafka Brokers (Kafka servers or nodes in a Kafka Cluster). Events that include the same event key, such as a specific customer ID or payment ID, will always be written to the same partition, and the consumer of that partition – the topic will always be able to read the events in the same order in which they were written. Partitions are integral to how Kafka works because they enable topic parallelization and high message throughput.
Kafka Records
Entries are event information that is stored in a topic as a record. Applications can connect and transfer the record to the topic. The data is durable and can be stored in the topic long until the specified retention period expires. Records can consist of different types of information – information about a web event such as a purchase transaction, social media feedback, or some data from a sensor-driven device. It can be an event that signals another event. These topic records can be processed and reprocessed by applications that connect to the Kafka system. Records can be described as byte arrays that store objects in any format. An individual record will have two mandatory attributes – key and value and two optional attributes – timestamp and header.
Apache Zookeeper and Kafka
Apache Zookeeper is software that monitors and maintains order in the Kafka system and acts as a centralized, distributed coordination service for the Kafka Cluster. It manages configuration and naming data and is responsible for synchronization across all distributed systems. Apache Zookeeper monitors Kafka cluster node states, Kafka messages, partitions, and topics, among other things. Apache Zookeeper allows multiple clients to read and write simultaneously, issue updates, and act as a shared registry in the system. Apache ZooKeeper is an integral part of distributed application development. It is used by HBase, Apache Hadoop, and other platforms for functions such as node coordination, leader election, configuration management, etc.
Use cases of Apache Zookeeper
Apache Zookeeper coordinates the Kafka Cluster. it needs Zookeeper to be installed before it can be used in production. This is necessary even if the system consists of a single broker, topic, and partition. Zookeeper has five use cases – administrator selection, cluster membership, topic configuration, access control lists (ACLs), and quota tracking. Here are some Apache Zookeeper use cases:
Apache Zookeeper chooses Kafka Controller.
A Kafka Controller is a broker or server that maintains a leader/follower relationship between partitions. Each Kafka cluster has only one driver. In the event of a node shutdown, the controller’s job is to ensure that other replicas take over as partition leaders to replace the partition leaders on the node being shut down.
Apache Zookeeper manages the topic configuration.
Zookeeper software keeps records of all topic configurations, including the list of topics, the number of topic partitions for each topic, overriding topic configurations, preferred leader nodes, and replica locations, among others.
The zookeeper Software maintains access control lists or ACLs
The Zookeeper software also maintains ACLs (Access Control Lists) for all topics. Details such as read/write permissions for each topic, list of consumer groups, group members, and the last offset each consumer group got from the partition are all available.
Installing Kafka – Several Steps
Installing Apache Kafka on Windows OS
Prerequisites: Java must be installed before starting to install Kafka.
Installation – required files
To install Kafka, you will need to download the following files:
• Download ZooKeeper:
• Kafka downloads:
Install Apache ZooKeeper
A. Download and extract Apache ZooKeeper from the above link.
b. Go to the ZooKeeper configuration directory, and change the dataDir Path from “dataDir=/tmp/zookeeper” to “:zookeeper-3.6.3data” in the zoo_sample.cfg file. Please note that the name of the Zookeeper folder may vary depending on the downloaded version.
C. Set system environment variables, add new “ZOOKEEPER_HOME = C:zookeeper-3.6.3”.
d. Edit the system variable named Path and add;%ZOOKEEPER_HOME%bin;
E. Run – “zkserver” from cmd. Now ZooKeeper is up and running on the default port 2181, which can be changed in the zoo_sample.cfg file.
Install Kafka
A. Download and extract Apache Kafka from the above link.
b. In the Kafka configuration directory. replace the log.dir path from “log.dirs=/tmp/kafka-logs” to “C:kafka-3.0.0kafka-logs” in server.properties. Please note that the name of the Kafka folder may vary depending on the downloaded version.
C. In case ZooKeeper is running on a different computer, edit these server.properties __ Here, we will define the private IP of the server
listeners = PLAINTEXT://172.31.33.3:9092## Here, we need to define the public IP address of the server}
advertised.listeners=PLAINTEXT://35.164.149.91:9092
d. Add the below properties to server.properties
advertised.hostname=172.31.33.3
advertised.port=9092
E. Kafka runs as default on port 9092, and it connects to ZooKeeper’s default port which is 2181.
Running Kafka server.
A. From Kafka installation directory C:kafka-3.0.0binwindows, open cmd and run the below command.
>kafka-server-start.bat ../../config/server.properties.
b. The Kafka Server is up and running, and it’s time to create new Kafka Topics to store messages.
Create Kafka Topics
A. Create a new topic as my_new_topic.
b. From C:kafka-3.0.0binwindows, open cmd and run the command below:
Commands For Installing Kafka
A. Open a new command prompt in the location and list Topics.C:kafka-3.0.0binwindows>kafka-topics. bat –list –zookeeper localhost:2181
b. Producer and consumer commands to test messages:>kafka-console-producer.bat –broker-list localhost:9092 –topic my_new_topic>kafka-console-consumer.bat –bootstrap-server localhost:9092 –topic my_new_topic (above Kafka version >2.0 )
Kafka Connectors
How can Kafka be connected to external systems? Kafka Connect is a framework that connects databases, search indexes, file systems, and key-value stores to Kafka using ready-to-use components called Kafka Connectors. Kafka connectors deliver data from external systems to Kafka topics and from Kafka topics to external systems.
Kafka resource connectors
The Kafka Source Connector aggregates data from source systems such as databases, streams, or message brokers. The source connector can also collect metrics from application servers into Kafka topics for near-real-time stream processing.
Kafka sink connectors
The Kafka Sink Connector exports data from Kafka topics to other systems. These can be popular databases like Oracle, SQL Server, SAP or indexes like Elasticsearch, batch systems like Hadoop, cloud platforms like Snowflake, Amazon S3, Redshift, Azure Synapse, and ADLS Gen2, etc.
Conclusion
Kafka has numerous and found in various industries such as financial services, manufacturing, retail, gaming, transportation and logistics, telecommunications, pharmaceuticals, life sciences, healthcare, automotive, insurance, and more. Kafka is used wherever large-scale streaming data is processed and used for reporting.
- It is an open-source platform that ingests and processes streaming data in real time. Streaming data is generated simultaneously by thousands of data sources every second.
- The Kafka Source Connector aggregates data from source systems such as databases, streams, or message brokers. The source connector can also collect metrics from application servers into Kafka topics for near-real-time stream processing.
- Zookeeper software keeps records of all topic configurations, including the list of topics, the number of topic partitions for each topic, overriding topic configurations, preferred leader nodes, and replica locations, among others.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.