

{kind=link}
Welcome to Part 2 in Neural Magic’s five-part blog series on pruning in machine learning. In case you missed it, Part 1 gave a pruning overview, detailed the difference between structured vs. unstructured pruning, and described commonly used algorithms, including Gradual Magnitude Pruning (GMP).
Few algorithms are better than GMP in overall results, and none beat the simplicity of the integration. GMP is implemented in the following way: a trained network is used and, over several training epochs, the weights closest to zero are iteratively removed.
For example, pruning a network will typically look like the following (sparsity and epoch values vary based on the model and training process):
- Begin retraining a network at a slightly higher learning rate than the final one used for the optimizer.
- At the start of epoch 1, set the sparsity for all layers to be pruned to 5%.
- From there, iteratively remove (set to zero) the weights closest to zero once per epoch until 90% sparsity is reached at epoch 35.
- After this, hold the sparsity constant at 90%, continue training, and reduce the learning rate until epoch 60.
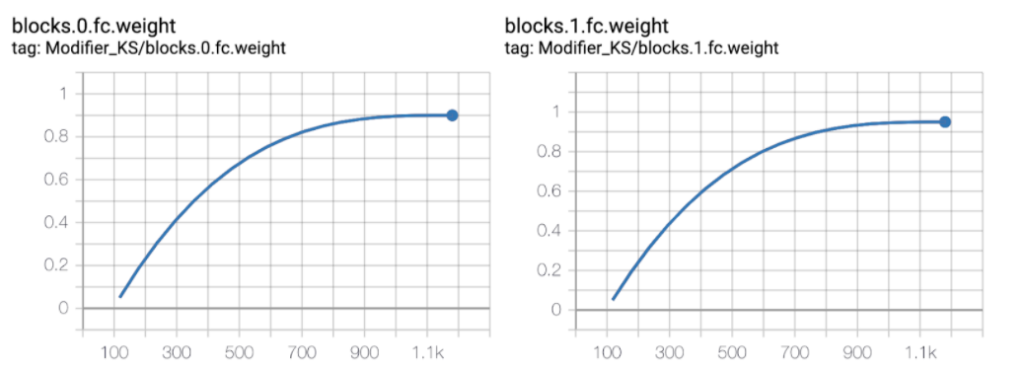
Example of pruning two layers in a neural network using GMP. The x-axis is the number of steps (batches) taken by the optimizer; the y-axis is the total sparsity for the layer.
GMP and its assumption to remove the weights closest to zero works so well because stochastic gradient descent (SGD) is self-regularizing. Therefore optimizing using SGD (or any of its derivatives) along with standard L2 or L1 regularization of the weights pushes unused pathways in the optimization space toward zero. We can then safely set those pathways to zero.
Why not use one-shot pruning, where we cut out all the weights at once instead of over several epochs? Currently, this does not work well experimentally. For example, when attempting to prune ResNet-50 in one shot to 90% with and without retraining after, both the validation and training loss drop significantly from baseline. There are two general reasons for this. First, the correlation of absolute magnitude with the importance of the weights only works at the extremes. Weights are not ordered perfectly between the ranges due to noise in the process. When applying one-shot pruning across a network, essential connections are removed. Second, this is a very lossy process as compared to quantization, for example. When pruning, the information in the network is not compressed; instead, it is completely removed. Taking steps while pruning allows the network to regularize and adjust weights to better reconverge to the previous optimization point.
Stages
When using GMP, there are three general stages:
- Stabilization
- Pruning
- Fine-tuning
Each one is applied immediately after the other. The stages work together to perform an underlying architecture search on the model and converge to an accurate and performant sparse solution. Each stage is enumerated below in addition to how long each typically runs.
![]()
Example for the stages and how they apply to the sparsity of one layer of a GMP run on ResNet-50 trained on the ImageNet dataset. The x-axis is the number of steps (batches) taken by the optimizer; the y-axis is the total sparsity for the layer. The pruning stage ran from epoch 2 to 37 with a pruning update every epoch starting at 5% sparsity and ending at 85%. Fine-tuning ran until epoch 57.
![]()
Example for the stages and how they apply to the SGD learning rate of a GMP run on ResNet-50 trained on the ImageNet dataset. The x-axis is the number of steps (batches) taken by the optimizer; the y-axis is the learning rate used with SGD. The learning rate is initially set to 0.01 and adjusted to 0.001 at epoch 43 and 0.0001 at epoch 50.
Stabilization
Stabilization is the first stage. In general, it is short, running for only one or two epochs. A pretrained network is initialized and a new optimizer is created with the desired learning rate for pruning (we’ll talk more about learning rates in a future post). This allows the training process to converge to a stable point in the optimization space before starting the pruning steps.
Pruning
Pruning is the second stage, and it generally should be run for a third to a half of your total training time. For example, a standard pruning stage on ImageNet lasts 35 epochs (compared with 90 for the original training schedule). With pruning, the sparsity (the number of zeros in a network) is gradually increased until reaching the desired solution. If you run into issues with your network quickly dropping loss and not recovering after the fine-tuning stage, try to lengthen your pruning stage.
Fine-Tuning
Fine-tuning is the final stage, and it generally should be run for a little less than one-fourth of the total training time. For example, a standard fine-tuning stage on ImageNet lasts 20 epochs (compared with 90 for the original training schedule). With fine-tuning, the model can recover any loss suffered during pruning and ideally converge back to the unique optimization point. Preferably, multiple learning rate reduction steps should be taken in this stage if using standard SGD. If you still see the validation loss trending down by the time this stage completes, lengthening and adding another learning rate reduction step can significantly help.
Given that the model is significantly smaller than the original and therefore regularized, it generally helps to remove any weight regularization at this point. In internal experiments, we find this can increase the top1 accuracy when pruning on ImageNet by up to a full percent. The intuition is that the pruned model now has an architecture biased towards generalization; therefore, we do not want to penalize more complex solutions that are likely to continue generalizing.
Learn More About Pruning
In our third post in this series, we’ll elaborate on the general hyperparameters that must be defined to facilitate the GMP process. If you have questions or would like us to help you to speed up your neural networks with pruning, reach out to us!
About the author: Mark Kurtz is the Machine Learning Lead at Neural Magic. He’s an experienced software and machine learning leader with a demonstrated success in making machine learning models successful and performant. Mark manages teams and efforts that ensure organizations realize high returns from their machine learning investments. He is currently building a “software AI” engine at Neural Magic, with a goal to bring GPU-class performance for deep learning to commodity CPUs.