



{kind=link}
Introduction
Innovative techniques continually reshape how machines understand and generate human language in the rapidly evolving landscape of natural language processing. One such groundbreaking approach is Retrieval Augmented Generation (RAG), which combines the power of generative models like GPT (Generative Pretrained Transformer) with the efficiency of vector databases and langchain.

RAG represents a paradigm shift in the way machines process language, bridging the gap between generative models and retrieval models to achieve a level of contextual understanding and responsiveness that was previously unparalleled. In this blog post, we will explore RAG’s core concepts, integration with GPT models, the role of vector databases, and its real-world applications.
Learning Objectives
- Understand the Fundamentals of Retrieval Augmented Generation (RAG)
- Gain insights into Vector Database and its innovative data storage and retrieval approach using vectors.
- Understand how RAG, LangChain, and Vector Database work in tandem to interpret user queries, retrieve relevant information, and generate coherent responses.
- Develop practical skills in applying integrated technologies for specific applications.
This article was published as a part of the Data Science Blogathon.
Table of contents
- What is RAG?
- Understanding the Essence of RAG
- What is Langchain?
- Vector Databases in RAG
- How do Vector Databases Store and Retrieve Data?
- Benefits of Using Vector Databases in RAG
- Putting Everything Together
- Implementing Question Answering in LangChain
- load_qa_chain
- Retrieval QA Chain
- Conversation Retrieval Chain
- Reducing Hallucinations in GenAI Applications with RAG
- Evaluating RAG Applications
- Ethical Considerations in the Age of Advanced Information Technologies
- Frequently Asked Questions
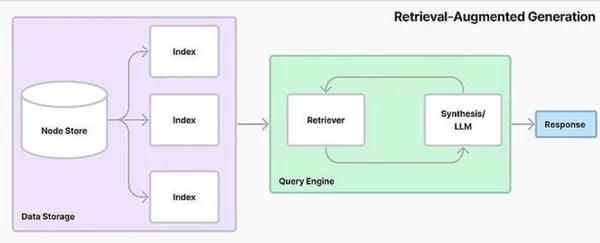
What is RAG?
Retrieval Augmented Generation (RAG) represents a fusion of generative and retrieval models. It seamlessly combines the creative capabilities of generative models with the precision of retrieval systems, allowing for diverse and contextually relevant content generation.
In some traditional language generation tasks, such as text completion or question answering, generative models like GPT (Generative Pre-trained Transformer) have shown excellent capabilities in generating contextually relevant text. However, when the input context is ambiguous or the data is scarce, they may produce incorrect or inconsistent responses.
Retrival-based models, on the other hand, can efficiently extract relevant responses from a vast database of pre-written responses or documents. To deliver accurate responses, chatbots and information retrieval systems frequently utilize them. However, because they are limited to the responses in their database, they lack the originality and adaptability of generative models.
Understanding the Essence of RAG
At its core, RAG is a sophisticated approach that harmoniously blends two fundamental aspects of natural language processing.
Generative Models
Generative models, like OpenAI’s GPT (Generative Pretrained Transformer), have gained widespread recognition for generating coherent and contextually relevant text based on large-scale training datasets. These models employ intricate neural architectures to predict and generate sequences of words, making them highly creative in generating human-like language.
Retrieval Models
On the other hand, retrieval models are designed to efficiently search and retrieve specific pieces of information from vast datasets. These models, often utilizing advanced techniques like vector embeddings, can quickly identify relevant documents, paragraphs, or sentences based on the input query.
What is Langchain?
Let’s first capture the essence of LangChain before we decipher its subtleties. A reliable library called LangChain was created to make interactions with different large language model( LLM) providers, such as OpenAI, Cohere, Bloom, Huggingface, and others, more leisurely. The ability to create Chains and logical connections that aid in bridging one or more LLMs distinguishes LangChain from other platforms.

Why LangChain?
Countless opportunities are available on LangChain; your imagination is the only constraint.
- Imagine chatbots that offer users wit and charm in addition to information.
- Picture e-commerce platforms that accurately recommend products and compel customers to buy.
- Envision healthcare apps provide individualized medical insights, enabling people to choose wisely for their well-being.
You can have extraordinary experiences with LangChain. You have the power to make these concepts a reality right in front of you.
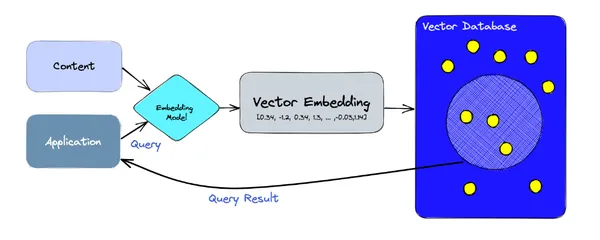
Vector Databases in RAG
A vector database is a sophisticated system that stores and processes data in vector format. Unlike traditional databases that rely on structured tables, vector databases organize information using vector mathematical representations of data points in a multi-dimensional space. This unique approach enables efficient storage, retrieval, and manipulation of vast datasets, making them ideal for handling complex and unstructured data.
How do Vector Databases Store and Retrieve Data?
Storing Data as Vectors
In vector databases, data is stored as vectors to preserve the relationships and similarities between different data points. For example, in a recommendation system, user preferences for movies can be represented as vectors. If two users have similar movie preferences, their respective vectors would be close together in the vector space.
Vector databases utilize specialized data structures and algorithms to store these vectors efficiently. One common technique is the use of embeddings, where raw data is transformed into fixed-size vectors using techniques like word embeddings for natural language processing or image embeddings for computer vision tasks.
Indexing and Retrieving Data
Traditional databases rely heavily on indexing techniques to speed up data retrieval. Vector databases, too, employ indexing strategies, but they focus on the geometric properties of vectors. One widely used method is the creation of spatial indexes, such as tree structures (like R-trees) or approximate nearest neighbor search algorithms (like locality-sensitive hashing). These methods enable the database to identify vectors close to a given query vector quickly.
When a query is made to find similar images to a reference image, the vector representation of the reference image is compared to the vectors of all stored images using proximity measures like cosine similarity or Euclidean distance. This comparison, facilitated by specialized algorithms, allows the database to retrieve similar images efficiently.
Benefits of Using Vector Databases in RAG
RAG combines traditional language generation techniques with retrieval methods, allowing AI systems to pull in specific information from a dataset before generating a response. When integrated with vector databases, RAG becomes a potent tool, offering several distinct advantages:
Contextual Relevance
Vector databases enable the storage of contextual information in a way that preserves relationships and similarities between different data points. When applied to RAG, generated content can be more contextually relevant. By retrieving and analyzing vectors similar to the query context, the AI system can craft responses that align closely with the conversation’s context, enhancing the user experience significantly.
Efficient Information Retrieval
Traditional databases often struggle with large datasets and complex queries, leading to slower response times. Vector databases, optimized for similarity searches, excel at efficient information retrieval. When integrated with RAG models, they enable quick access to relevant data points. This speed is crucial in applications like chatbots, customer support systems, and content recommendation engines where timely responses are paramount.
Accurate Semantics
Vector representations capture semantic similarities between words and phrases. When generating responses using RAG, vector databases assist in understanding the keywords and semantic nuances of the query. This ensures that the generated content is not just a keyword match but a semantically accurate and meaningful response, enhancing the overall quality of interactions.
Enhanced Decision-Making
RAG systems can make more informed decisions by leveraging the wealth of data stored in vector databases. Whether generating product recommendations, answering complex queries, or assisting in data analysis, the comprehensive understanding derived from vector representations aids AI systems in providing valuable insights and recommendations.
Incorporating vector databases into Retrieval Augmented Generation enhances the accuracy and relevance of generated content and opens doors to new possibilities in personalization, contextual understanding, and real-time responsiveness.
Putting Everything Together
We can develop a retrieval-augmented AI system that is both generative and retrieval-based by combining the strength of OpenAI’s GPT models, LangChain, and Pinecone Vector Databases. This system can retrieve and use particular pieces of information in addition to producing creative and human-like text.

- Loading: We must first load our data. Different loaders in LangChain can be used.
- Splitting: Text splitters divide documents into predetermined-size splits.
- Storage: Splits, such as a vector store, will be kept and frequently embedded in storage.
- Retrieval: The app retrieves splits from storage, frequently with similar input question embeddings.
- Generation: An LLM uses a prompt containing the query and the retrieved data to generate an answer.
Implementing Question Answering in LangChain
There are different ways to do question answering in LangChain. Some of them are discussed below:
1. load_qa_chain
It performs Question Answering every time it is called on all documents passed. It is straightforward and thorough, but because it might not concentrate on the most crucial components of the question, it may be slower and less effective than RetrievalQA.
2. RetrievalQA
RetrievalQA performs QA on the portion of the text that is most pertinent. It is quicker and more effective than the load_qa_chain and uses it under the hood on each chunk. Since the documents may not always provide the best text chunks for the question, these performance gains come at the risk of losing some context or information.
3. VectorstoreIndexCreator
RetrievalQA can run with fewer lines of code thanks to VectorstoreIndexCreator, a higher-level wrapper.
4. ConversationalRetrievalChain
A chat history component is offered by ConversationalRetrievalChain, which is an advancement of RetriervalQAChat.
Let us discuss these in detail.
Import Necessary Libraries
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
from langchain.document_loaders import TextLoader
from langchain.document_loaders import PyPDFLoader
from langchain.indexes import VectorstoreIndexCreator
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
import os
os.environ["OPENAI_API_KEY"] = ""
llm = OpenAI()
load_qa_chain
This Loads a chain that you can use to answer questions over a set of documents. This uses all the documents, so there might be a problem when using huge files.
from langchain.chains.question_answering import load_qa_chain
# load document
loader = PyPDFLoader("/content/example.pdf")
documents = loader.load()
chain = load_qa_chain(llm=OpenAI(), chain_type="map_reduce")
query = "How many AI Publications in 2021?"
chain.run(input_documents=documents, question=query)
We are using the chain type of map_reduce. If stuff is used, the number of tokens exceeds the limit as it takes a list of documents, inserts them all into a prompt, and passes that prompt to an LLM.
For Multiple Documents
For multiple documents
loaders = [....]
documents = []
for loader in loaders:
documents.extend(loader.load())
chain = load_qa_chain(llm=OpenAI(), chain_type="map_reduce")
query = "How many AI Publications in 2021?"
chain.run(input_documents=documents, question=query)
Retrieval QA Chain
RetrievalQA chain uses load_qa_chain under the hood. We retrieve the most relevant chunk of text and feed those to the large language model of our choice.
Loading the Document
The first step is to load the data we need for answering questions. We can use one of Langchain’s many built-in data loaders. Here, we use PyPDFLoader, which loads the present pdf file data from the p.
loader = PyPDFLoader("/content/example.pdf")
documents = loader.load()
Splitting the Documents
After you complete the scraping and loading, we move on to chunking and cleaning the data. It is crucial to chunk the data to embed a substantial amount of context within our vector index. Embed only a few words because they don’t contain enough information to match relevant vectors, and embedding an entire page would take up too much space in the prompt’s context window.
There are many text splitters that Langchain supports. Here, we are using split by character as that would make it easier to manage the context length directly, choosing a chunk size of about 1000 tokens for this use case. We also set a small overlap length to preserve text continuity between our chunks.
# split the documents into chunks
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=20)
texts = text_splitter.split_documents(documents)
Using Embedding and Vector Database
After gathering our data sources, it’s time to create our knowledge base index. You can quickly locate vectors based on specific criteria, such as similarity or distance, by creating an index, essentially a map or reference.
Use OpenAI for the Embeddings and ChromaDB as the vector database. The document vectors can be added to the index once created.
# select which embeddings we want to use
embeddings = OpenAIEmbeddings()
# create the vectorestore to use as the index
db = Chroma.from_documents(texts, embeddings)Using Retrieval
It’s time to define our retriever once our vector store has been indexed. The retrieval module uses its search algorithm to determine how the pertinent documents are retrieved from the vector database.
In NLP, retrieval is crucial, especially in applications that use search engines, question-answering systems, and information retrievals. A retriever’s objective is to effectively search through a sizable corpus of documents to find the most likely to contain user-specific information.
# expose this index in a retriever interface
retriever = db.as_retriever(search_type="similarity", search_kwargs={"k":2})Search Types
Different types of searches can be used in the retrieval.
- Semantic Similarity: The semantic search fetches all similar documents but does not enforce diversity.
- MMR (Maximal Marginal Relevance): Not only looks at similarity but also looks at diversity. The first chunk is a little different from the second one
Creating the Chain
We can construct the Conversational Retrieval Chain now that we have all the necessary parts. In order to facilitate conversational interactions, this chain expands on RetrievalQAChain by including a chat history element. We are using the chain type of stuff.
# create a chain to answer questions
qa = RetrievalQA.from_chain_type(
llm=OpenAI(), chain_type="stuff", retriever=retriever, return_source_documents=True)
query = "what is the total number of AI publications?"
result = qa({"query": query})
Conversation Retrieval Chain
The ConversationalRetrievalQA chain builds on RetrievalQAChain to provide a chat history component.
- It first combines the chat history and the question into a single question.
- After that, it looks up relevant documents from the retriever.
- And then passes those documents and the question to a question-answering chain to return a response.
from langchain.chains import ConversationalRetrievalChain
# load document
loader = PyPDFLoader("/content/example.pdf")
documents = loader.load()
# split the documents into chunks
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# select which embeddings we want to use
embeddings = OpenAIEmbeddings()
# create the vectorestore to use as the index
db = Chroma.from_documents(texts, embeddings)
# expose this index in a retriever interface
retriever = db.as_retriever(search_type="similarity", search_kwargs={"k":2})
# create a chain to answer questions
qa = ConversationalRetrievalChain.from_llm(OpenAI(), retriever)
First query
We first create an empty chat history and append all the user queries and chatbot responses.
chat_history = []
query = "what is the total number of AI publications?"
result = qa({"question": query, "chat_history": chat_history})
Second Query
The chat history now contains the previous user query and chatbot response.
chat_history = [(query, result["answer"])]
query = "What is this number divided by 2?"
result = qa({"question": query, "chat_history": chat_history})

Reducing Hallucinations in GenAI Applications with RAG
In the context of Generative AI, particularly with models like Retrieval-Augmented Generation (RAG), mitigating hallucinations is pivotal. RAG combines information retrieval and language generation techniques, allowing AI systems to generate content based on retrieved, relevant information. However, hallucinations can still occur.
Causes of Hallucinations
- Data Biases: The model might generate biased or hallucinated content if the training data contains biased information.
- Over-Optimization: Models that are overly complex or trained for too long can memorize rare patterns in the training data, leading to hallucinations.
- Ambiguity in Training Data: If the training data lacks context or contains ambiguous information, the model might fill in the gaps with hallucinated content.
Here’s how you can employ RAG effectively to reduce these hallucinations:
Use of Targeted Queries
Craft precise queries for information retrieval. By formulating focused queries, irrelevant or misleading information is less likely to be retrieved, reducing the chances of hallucinations.
# Example of a targeted query using RAG
query = "Relevant context for generating response."
retrieved_information = retrieve_information(query)
Incorporate Rich Context
RAG allows for the inclusion of context when generating responses. Including relevant context from retrieved information makes the generated content more grounded and less prone to hallucinations.
# Incorporating retrieved information as context for generation
context = preprocess_retrieved_info(retrieved_information)
generated_response = generate_response_with_context(user_query, context)
Confidence Scores
Assign confidence scores to retrieved information. Higher confidence scores indicate reliable information. Filter responses based on these confidence scores to ensure that only trustworthy information contributes to the generated content.
# Filtering retrieved information based on confidence scores
confident_retrieved_info = filter_high_confidence_info(retrieved_information)
generated_response = generate_response(user_query, confident_retrieved_info)
Human Validation Loop
Introduce a human validation step. Human moderators can review generated responses. If a response contains potentially hallucinated content, the system can flag it for human review before presenting it to users.
# Human validation loop for generated responses
generated_response = generate_response(user_query, retrieved_information)
if requires_human_validation(generated_response):
reviewed_response = human_review(generated_response)
send_response_to_user(reviewed_response)
else:
send_response_to_user(generated_response)
By integrating these strategies, RAG can significantly reduce hallucinations in Generative AI applications.
Evaluating RAG Applications
For the various components of our RAG application, we have so far selected typical/ arbitrary values. However, if we changed something, like our LLM, embedding model, or chunking logic, how can we be sure that our configuration is better than it was? We must create trustworthy methods to quantitatively assess a generative task like this because it is very challenging. We must conduct both unit or component and end-to-end evaluations because our application contains numerous moving parts.
Component-wise Evaluation
It can necessitate evaluating the following:
Retrieval in isolation: This is the best source in our retrieved chunks.
LLM’s response: Can the LLM produce a high-quality answer given that source?

Overall, the System’s Quality Evaluation
Additionally, we can evaluate the overall system’s quality, which accesses the data sources, and the quality of the response for end-to-end evaluation.

Ethical Considerations in the Age of Advanced Information Technologies
Ethical considerations are pivotal in shaping the innovation trajectory in advanced information technologies, where Retrieval Augmented Generation (RAG), LangChain, and Vector Databases seamlessly intertwine. As these cutting-edge technologies redefine how we process information and interact with data, examining the ethical implications in this transformative landscape is imperative.
Privacy and Data Security
The amalgamation of RAG, LangChain, and Vector Databases processes, retrieves, and generates vast amounts of data. Ethical concerns arise regarding the privacy and security of this data. Ensuring robust encryption, strict access controls, and transparent data usage policies are essential to protect user information from unauthorized access and misuse.
Bias and Fairness
These technologies train algorithms on extensive datasets, potentially inheriting biases present in the data. Addressing algorithmic bias is crucial to preventing discriminatory outcomes, especially in language processing and content generation applications.
Accountability and Transparency
Developers, organizations, and policymakers must be accountable for their creations as these technologies evolve. Transparent communication about how these systems operate, the sources of data, and the algorithms employed fosters trust among users.
Conclusion
In conclusion, the fusion of cutting-edge technologies like Retrieval Augmented Generation (RAG), LangChain, and Vector Database marks a significant milestone in natural language processing and information retrieval. The synergy between these advanced tools amplifies the efficiency of data retrieval and elevates the quality of generated content to unprecedented levels.
With Retrieval Augmented Generation, we have bridged the gap between traditional search methods and natural language understanding. By integrating LangChain’s linguistic prowess and Vector Database’s robust data structuring, we have created a seamless ecosystem where machines swiftly comprehend human language intricacies, access relevant information, and produce contextually rich, coherent, and accurate content. As we move forward, the collaboration between RAG, LangChain, and Vector Database promises a future where human-machine interaction is both efficient and deeply meaningful. The journey doesn’t end here; it merely evolves, and with each step, we get closer to a world where technology truly augments our capabilities, making the complex simple and the unimaginable attainable.
Key Takeaways
- Businesses and individuals can efficiently access pertinent information by harnessing RAG’s natural language understanding alongside LangChain’s linguistic analysis and Vector Database’s structured data retrieval capabilities.
- The collaboration between RAG, LangChain, and Vector Database elevates content generation to unprecedented levels.
- More brilliant virtual assistants, intuitive chatbots, and insightful data analysis tools become possible, enhancing user experiences across various applications. This transformative shift ensures that technology serves as an actual augmentation of human capabilities.
Frequently Asked Questions
A1. Retrieval Augmented Generation (RAG) is an advanced technology that integrates natural language understanding and generation with information retrieval. RAG comprehends user queries, retrieves relevant information from large datasets using the Vector Database, and generates human-like responses. Combined with LangChain’s linguistic analysis, it ensures accurate interpretation of queries, allowing for the generation of contextually rich and coherent responses.
A2. LangChain is a linguistic analysis tool that dissects the intricacies of language, including grammar, syntax, and semantics. By integrating LangChain with RAG, the system gains a deep understanding of the nuances of human language. LangChain’s analysis ensures that RAG comprehends queries with precision, accurately interpreting the meaning behind the words. This synergy results in more accurate and contextually relevant responses.
A3. Vector Database is a revolutionary data storage system that organizes data points using vectors, capturing semantic relationships between them. The Vector Database efficiently stores and retrieves structured information in this integrated system. By understanding the semantic context of data, it ensures that the retrieved information is not only relevant but also contextually accurate. This innovative approach significantly improves the speed and accuracy of information retrieval.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.