



{kind=link}
This article was published as a part of the Data Science Blogathon.
Introduction
When you go out to buy a shirt for yourself, you will not buy something which is very fit for your body because then if you eat pizza or biryani and if you become fat it will not be convenient you will not buy something that is very loose because then it looks like a cloth hanging on a skeleton, you will try to buy a right fit for your body the problem of overfitting and underfitting happening in the machine learning project as well, and there are techniques to tackle this overfitting and under fitting issue and these techniques are called regularization techniques.
In the below image, we are applying a dropout on the second hidden layer of a neuron network.
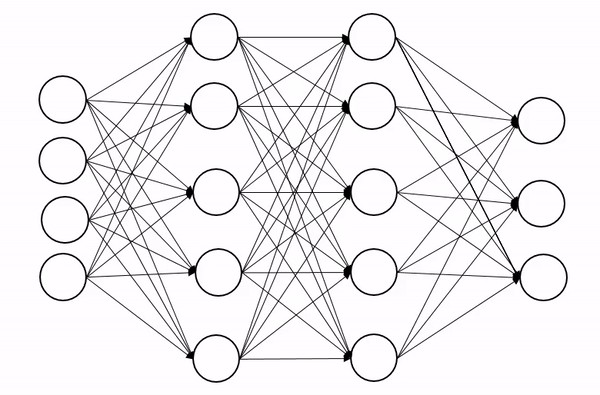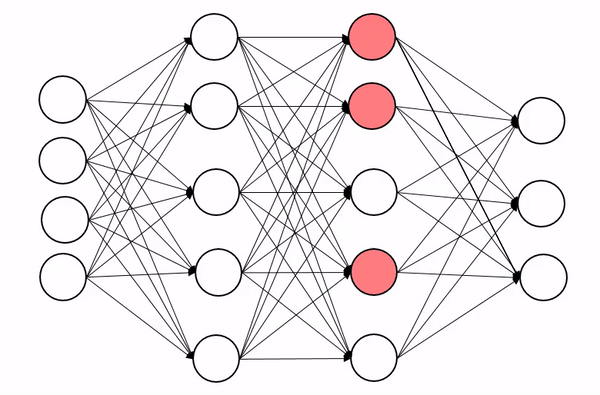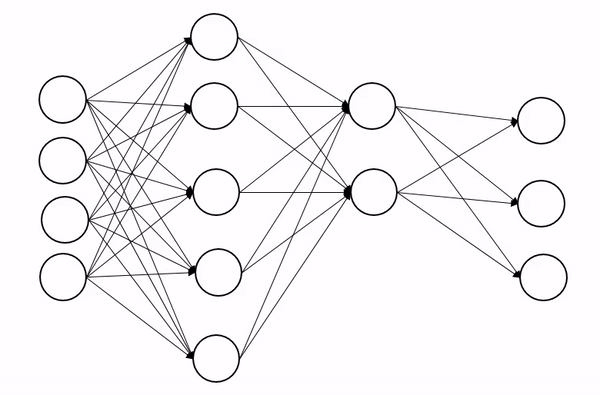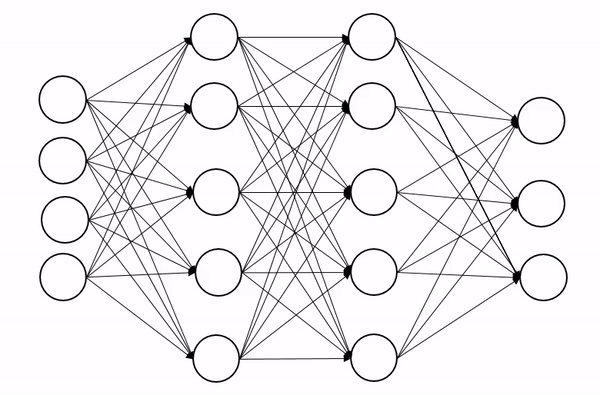
Table of contents
What’s Dropout?
In machine learning, “dropout” refers to the practice of disregarding certain nodes in a layer at random during training. A dropout is a regularization approach that prevents overfitting by ensuring that no units are codependent with one another.
Dropout Regularization
When you have training data, if you try to train your model too much, it might overfit, and when you get the actual test data for making predictions, it will not probably perform well. Dropout regularization is one technique used to tackle overfitting problems in deep learning.
That’s what we are going to look into in this blog, and we’ll go over some theories first, and then we’ll write python code using TensorFlow, and we’ll see how adding a dropout layer increases the performance of your neural network.
Training with Drop-Out Layers
Dropout is a regularization method approximating concurrent training of many neural networks with various designs. During training, some layer outputs are ignored or dropped at random. This makes the layer appear and is regarded as having a different number of nodes and connectedness to the preceding layer. In practice, each layer update during training is carried out with a different perspective of the specified layer. Dropout makes the training process noisy, requiring nodes within a layer to take on more or less responsible for the inputs on a probabilistic basis.
According to this conception, dropout may break apart circumstances in which network tiers co-adapt to fix mistakes committed by prior layers, making the model more robust. Dropout is implemented per layer in a neural network. It works with the vast majority of layers, including dense, fully connected, convolutional, and recurrent layers such as the long short-term memory network layer. Dropout can occur on any or all of the network’s hidden layers as well as the visible or input layer. It is not used on the output layer.
Dropout Implementation
Using the torch. nn, you can easily add a dropout to your PyTorch models. The dropout class accepts the dropout rate (the likelihood of a neuron being deactivated) as a parameter.
self.dropout = nn.Dropout(0.25) Dropout can be used after any non-output layer.
To investigate the impact of dropout, train an image classification model. I’ll start with an unregularized network and then use Dropout to train a regularised network. The Cifar-10 dataset is used to train the models over 15 epochs.
A complete example of introducing dropout to a PyTorch model is provided.
class Net(nn.Module):
def __init__(self, input_shape=(3,32,32)):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 32, 3)
self.conv2 = nn.Conv2d(32, 64, 3)
self.conv3 = nn.Conv2d(64, 128, 3)
self.pool = nn.MaxPool2d(2,2)
n_size = self._get_conv_output(input_shape)
self.fc1 = nn.Linear(n_size, 512)
self.fc2 = nn.Linear(512, 10)
self.dropout = nn.Dropout(0.25)
def forward(self, x):
x = self._forward_features(x)
x = x.view(x.size(0), -1)
x = self.dropout(x)
x = F.relu(self.fc1(x))
# Apply dropout
x = self.dropout(x)
x = self.fc2(x)
return x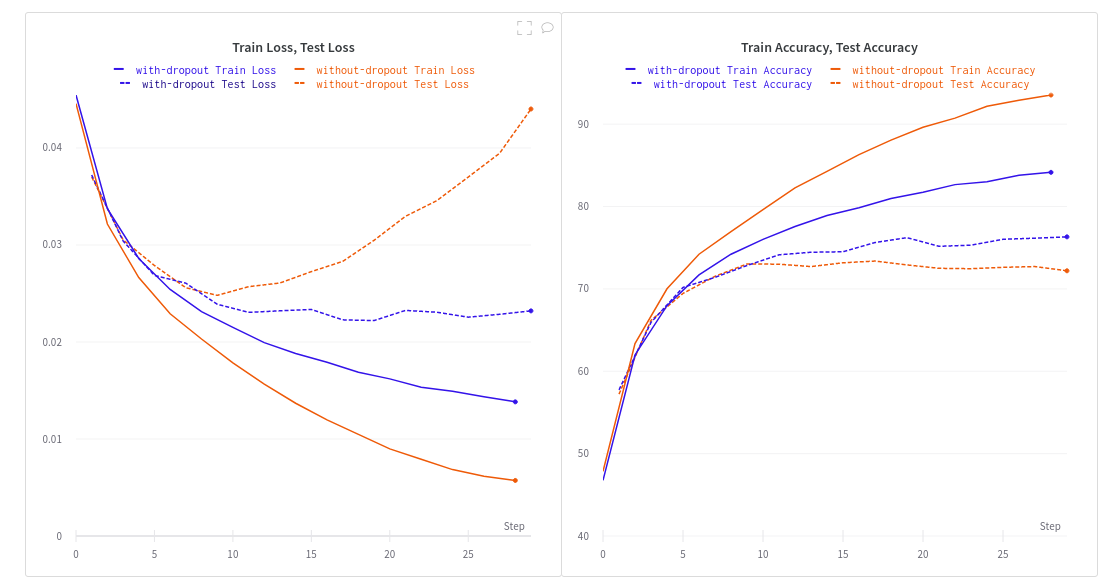
An unregularized network overfits instantly on the training dataset. Take note of how the validation loss for the no-dropout run diverges dramatically after only a few epochs. This explains why the generalization error has grown.
Overfitting is avoided by training with two dropout layers and a dropout probability of 25%. However, this affects training accuracy, necessitating the training of a regularised network over a longer period.
Leaving improves model generalisation. Although the training accuracy is lower than that of the unregularized network, the total validation accuracy has improved. This explains why the generalization error has decreased.
Why will dropout help with overfitting?
- It can’t rely on one input as it might be randomly dropped out.
- Neurons will not learn redundant details of inputs
Other Popular Regularization Techniques
When combating overfitting, dropping out is far from the only choice. Regularization techniques commonly used include:
Early stopping: automatically terminates training when a performance measure (e.g., validation loss, accuracy) ceases to improve.
Weight decay: add a penalty to the loss function to motivate the network to utilize lesser weights.
Noise: Allow some random variations in the data through augmentation to create noise (which makes the network robust to a larger distribution of inputs and hence improves generalization).
Model Combination: the outputs of separately trained neural networks are averaged (which requires a lot of computational power, data, and time).
Dropout Regularization Hyperparameters
A big decaying learning rate and a high momentum are two hyperparameter values that have been discovered to function well with dropout regularisation. Limiting our weight vectors using dropout allows us to employ a high learning rate without fear of the weights blowing up. Dropout noise, along with our big decaying learning rate, allows us to explore alternative areas of our loss function and, hopefully, reach a better minimum.
The Drawbacks of Dropout
Although dropout is a potent tool, it has certain downsides. A dropout network may take 2-3 times longer to train than a normal network. Finding a regularizer virtually comparable to a dropout layer is one method to reap the benefits of dropout without slowing down training. This regularizer is a modified variant of L2 regularisation for linear regression. An analogous regularizer for more complex models has yet to be discovered until that time when doubt drops out.
Conclusion
Computer vision systems usually never have enough training data; dropout is extremely common in computer vision applications. Convolutional neural networks are computer vision’s most widely used deep learning models. Dropout, on the other hand, is not particularly useful on convolutional layers. This is because dropout tries to increase robustness by making neurons redundant. Without relying on single neurons, a model should learn parameters. This is very helpful if your layer has a lot of parameters.
Key Takeaways :
-
As a result, dropout layers in convolutional neural networks are often found after fully connected layers but not after convolutional layers.
- Other regularising techniques, such as batch normalization in convolutional networks, have largely overtaken dropout in recent years.
- Because convolutional layers have fewer parameters, they necessitate less regularisation.
Thanks for reading!
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.