



{kind=link}
This article was published as a part of the Data Science Blogathon.
Introduction
This article is the second part of the Data Science interview series, and so far, we have covered Regression Analysis. This article will discuss Random Forest, SVM, bias-variance tradeoff, and ensemble methods. These concepts are being asked very often in interviews. Therefore, before sitting into any data science interview, one must have clarity of these concepts with mathematical models.
Frequently Asked Interview Questions
Below listed are some questions covering the topics- Random Forest, SVM, bias-variance tradeoff, and ensemble methods.
How does a decision tree handle numerical and categorical data?
Decision trees are capable of handling both: numerical and categorical features.
Each split in a decision tree based on a feature:
- The categorical variable elements in the split belong to a particular class.
- The continuous variable elements in the split are higher than a threshold.
Moreover, the better approach is to convert a categorical variable into a continuous variable using an encoding technique, such as LabelEncoding or OneHotEncoding.
What is Random Forest Algorithm?
Random Forest is an ensemble algorithm that follows the bagging approach. The Decision Tree is the base estimator for a Random Forest. As the name suggests, a forest is a group of many trees, and a random forest is a set of various Decision Trees. Random Forest selects a feature set randomly to choose the best split at each decision tree node.
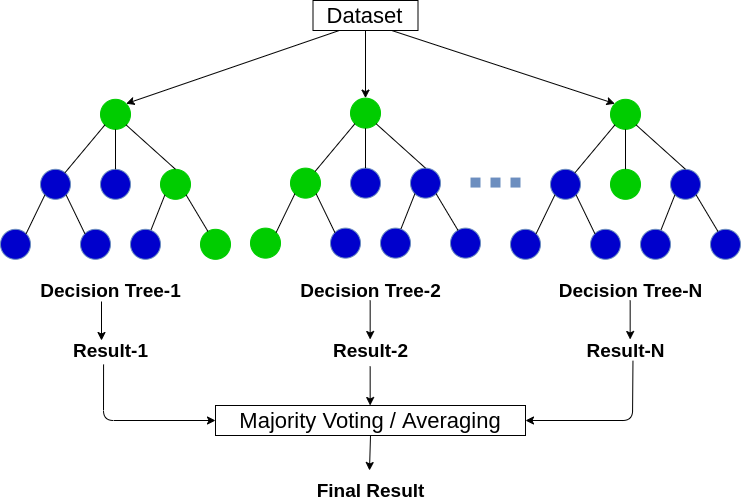
Random Forest is a supervised Machine Learning algorithm used for regression and classification problems.
Model
- Creating random subsets from the dataset is also known as bootstrapping.
- A random set of features will decide the best split at each Decision Tree node.
- It fits a decision tree model on each subset.
- The final prediction will be the average of the predictions from all the decision trees.
Random Forest is majorly applicable for feature importance selection. The method (._feature_importances_) finds the feature importance for the Random Forest model.
Some Important Parameters:-
1. n_estimators:- Number of decision trees in a random forest.
2. criterion:- “Gini” or “Entropy.”
3. min_samples_split:- Minimum number of samples or data points in a leaf node before a split.
4. max_features: -Maximum number of features for the split in each decision tree.
5. n_jobs:- Number of jobs to execute in resemblance for both fit and predict. Set as (-1) to utilize all available cores for parallel processing.
The random Forest method is available in the Scikit-Learn library and can be imported and used with the following code:
from sklearn.ensemble import RandomForestClassifier model = RandomForestClassifier()
What is Bias and Variance tradeoff?
The prediction errors in a prediction model occur majorly due to two reasons:
- Bias
- Variance
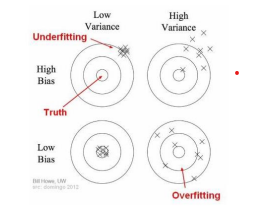
The Bias-variance tradeoff tells us to minimize the Bias and Variance in the prediction to avoid underfitting and overfitting the model.
Bias
Bias error of the model occurs due to oversimplification of the machine learning algorithm. The error is the difference between the average prediction and the actual value. So, bias measures how far the model prediction is from the correct prediction. The high bias always leads to high error training and test sets.
Variance
Variance error occurs due to complex machine learning algorithms. Variance indicates the variability of the prediction from the actual value for a given data point. Variance is how much the model prediction varies between different model realizations.
For example: In an election, voting Jack 13, voting John 16, and non-respondent 21 total of 50. The probability of voting Jack is 13/50, or 44.8%. We predicted that John would win by 10 points, but when the election results came out, he lost by 10 points. But where did we go wrong?
The answer is our prediction might have done on biased source data, or the sample size was small. The small sample size would increase the variance. Increasing the sample size would make the results more consistent but still might be highly inaccurate due to biased sources. However, this would have reduced the variance.
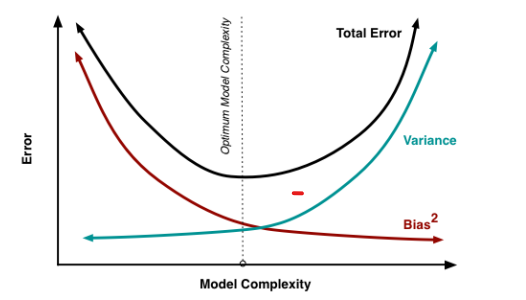
Thus, if we try to decrease the bias, the variance will increase and vice-versa. Therefore, we trade one for the other based on our requirements and try to keep both as minimum as possible.
What are Ensemble Methods? What is the difference between Bagging and Boosting?
An ensemble method is a group of weak learners who come together to make a strong learner. There are two techniques available to make ensemble models:
- Bagging (Bootstrap Aggregation)
- Boosting
Bagging
If our objective is to reduce the variance of an overfitted model, then we use the Bootstrapped ensemble model. Let’s understand the working of the bagging technique with a decision tree model.
The concept is to produce several random subsets from the training data with replacement. Now, each collection of subset data gets used to train their decision trees. As a result, we end up with an ensemble of different models. An average of all the predictions from all trees gets used, which is more robust than a single decision tree.
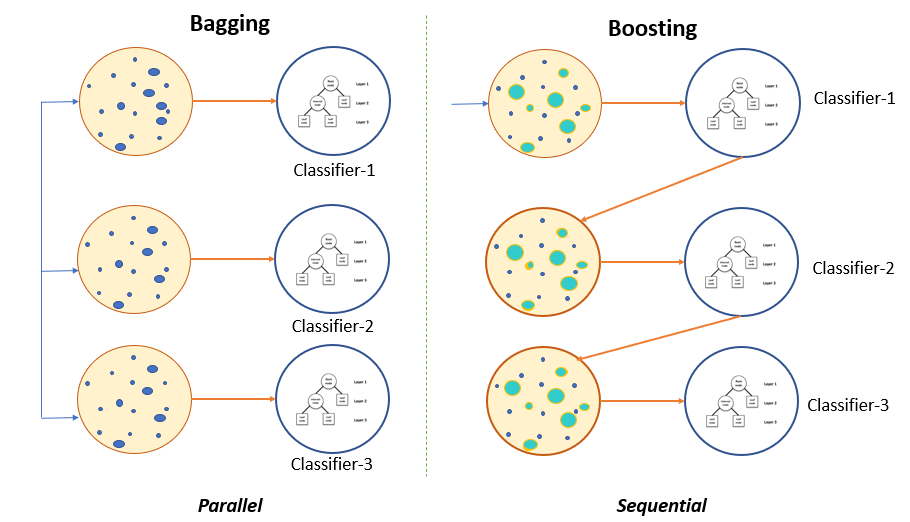
We can clearly identify the difference between Bagging and Boosting with the above image.
Boosting
The boosting techniques fit early learners with a simple model to learn sequentially and analyze data for errors. In other words, boosting fits successive trees with random samples and reduces the net error from the preliminary decision tree at each step.
When a hypothesis incorrectly predicts an input, its weight gets updated. Therefore, the upcoming hypothesis is more likely to predict the output correctly. Blending the entire set at the end transforms vulnerable learners into a better-performing model.
The different types of Boosting algorithms are:
- AdaBoost
- Gradient Boosting
- XGBoost
What is SVM Classification?
The SVM or Support Vector Machine is a supervised Machine Learning algorithm that uses two types of SVM classifiers for classification:
- Linear SVM
- Non-Linear SVM
Linear SVM
Linear SVM separates the data points by a straight line hyperplane that divides the two classes. This hyperplane is also called a maximum-margin hyperplane.
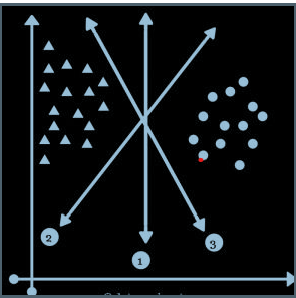
The above image shows the Linear SVM model building process with three hyperplanes. These hyperplanes are separating the data points into two classes, but hyperplane 1 has the maximal margin to the nearest data sample. Hence, it will be chosen for the final prediction.

The above image shows the Python code for executing the SVM for binary classification. The SVM uses a Linear kernel by default. The SVM object has an SVC method for the support vector classifier.
Non-Linear SVM
The data points in a multiclass classification task lie in more than two-dimensional space. Therefore, separating these using a linear hyperplane is not feasible in p-dimensions. Because in p-dimension, data becomes non-linearly separable and can not be separated using a Linear kernel. Hence, we use higher dimensions for the linear separation using Kernel tricks. A Kernel draws non-linear hyperplanes that make the distinction easy.
Some standard Kernels are :
- Polynomial Kernel
- RBF Kernel
- Gaussian Kernel
You can learn more about these Kernels in another article here.
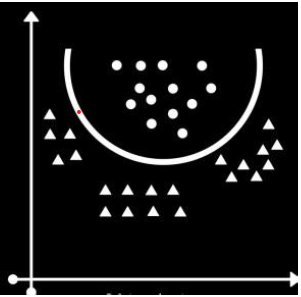
The above image represents an SVM model-building process for a multi-class classification problem. This model uses a Kernel as a hyperplane to classify the data points into their respective class or label.
Although the Python code for linear and non-linear SVM remains the same with just a change in Kernel. Let us understand the difference with the following example:
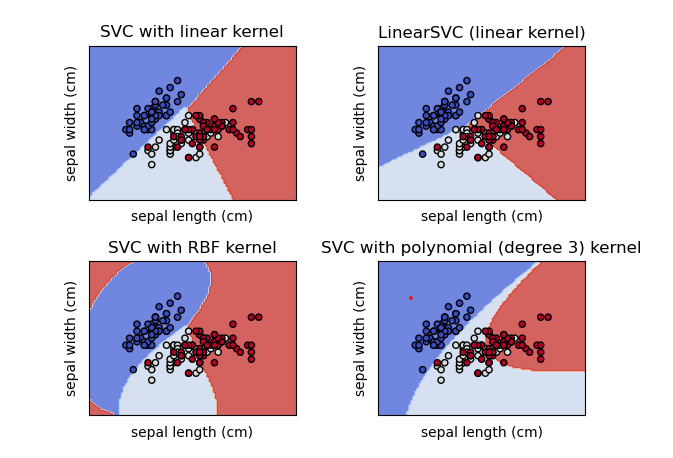
The above image shows a multi-class classification done on the iris dataset. There are three classes for classification: Iris Setosa, Iris Versicolour, and Iris Virginica. This image shows the classification with different kernels concerning two features, sepal length and sepal width.
The SVC with the Linear kernel is the same as the LinearSVC. While RBF kernel and Polynomial kernels separate data with non-linear hyperplanes. Since all these models only use two dimensions, the classification with kernels looks like the one with linear. However, if we use multi-dimensional space, the classification will be more accurate by the Kernels, but unfortunately, we can not visualize the multi-dimensional space here. So we just have to imagine that.
Advantages of SVM Classifier
- SVM is very effective with a large number of features as well.
- We can also classify the Non-linear data using Kernel tricks.
- SVM tends to work well with text classification, such as Spam or Ham classification.
- SVM is a robust classification model since it maximizes the margin.
Disadvantages of SVM Classifier
- The major challenge of the SVM is to choose a Kernel. The wrong kernel can increase the error more.
- It performs poorly with a large number of samples.
- SVM can be extremely slow in the test phase.
- SVM algorithm is highly complex and consumes extensive memory due to quadratic programming.
Conclusion
We have discussed some data science interview questions covering decision trees, Random Forest, Ensemble learning, and SVM. All these concepts are essential for interviews. These concepts are often used in real-life projects; hence, it is essential to have a good understanding of these concepts when preparing for a data science interview. The real-life applications of SVM are Bioinformatics, handwriting recognition, face detection, image classification, Text Classification, Spam Detection, etc. Moreover, Random Forest, as you have heard, is used in most projects to find feature importance. Random Forest and Tree-based algorithms are also very effective in getting good scores in any Hackathon and Kaggle competitions.
Let’s summarize the article with a few key takeaways:
- To handle categorical variables, use an encoding technique.
- Random Forest is a bootstrapped model of Decision Trees.
- We should always keep the Bias and Variance as minimum as practicable.
- The bagging Ensemble technique makes a group of weak learners create a strong learner; Boosting fits early learners with a simple model to learn sequentially to lessen the error.
- SVM uses hyperplanes to separate the data points and maximizes the margin.
- Linear SVM can only separate the data points which are linearly separable. Hence, we use Kernel tricks to separate the non-linearly separable data.
- The Ensemble technique often works better with tree-based algorithms and gives the best results.
- Many Data Scientists use the Ensemble technique to win the Data Science Hackathons and Kaggle competitions.
I hope you have learned something from reading this article. If you have any questions, doubts, or feedback regarding data science interview questions, feel free to reach me on Linkedin.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.