



{kind=link}
This article was published as a part of the Data Science Blogathon
Introduction
Data Science is an interdisciplinary field that uses various algorithms or techniques to extract information from the data. Data science cannot be learned over a single night. It is a gradual curve. There are various skills to be a data scientist. Most importantly you need to be good at statistics and probability.
You all will have a question in your mind that,
Where these statistics will be used in data science and real life?
In this blog, we will see some basic statistical concepts and where they will be used in data science.

“Statistical methods can help you make the “best educated guess.”
Let us see a quick intro about this blog,
→Population and sample
→→→→Where this population and sample is used in data science?
→ Variable
- Numerical variable
- Categorical variable
→ Random Variable
- Discrete Random variable
→→→→Where we use a discrete random variable in data science?
2. Continuous Random Variable
→→→→Where we use Continuous random variables in data science?
→Advantages of collecting data in Continuous Form
→The disadvantage of collecting data in Discrete form
→Data
- Quantitative data
- Qualitative data
→Percentile
→Quartile
In statistics, the first thing we need to know is population and sampling.
Population & Sample
In stats, we need to study the population. The population may be the number of persons, number of things, or any objects that we take for the analysis. It refers to the total quantity. This must be very big data.
Difficulties in taking population :
→ Collecting the entire population takes lots of time
→ The money required to collect those data is very high
So calculating the population of data is practically difficult. So here comes the new word “Sample”
The core idea of sampling is to select the portion or subset of the whole population and study that specific portion to gain the information of the population. So we were using a sample to gain information on the overall population.
In simple terms, Population is very big data, so, we take a particular part of the information(sample) in population and analyzing and arriving at a conclusion, considering that result shows all extracts of population.

https://pixabay.com/illustrations/human-banner-header-humanity-1375492/
Now you may have a question.
Where this population and sample is used in data science?
Let us see an example, We all know the process of election. All the people of the country elect the candidate by polling in ballots or EVMs etc. In this main election, all the people’s votes are considered. The overall count of the people is population.
Usually, before and after the election, NEWS channels conduct Opinion polls (i.e) entry poll(before the election), and exit poll(after election) surveys. In these opinion polls, the poll samples of 5000–10000 people are taken. This sample represents the views of the people of the country.
Best results depend on how well the sample represents the population. The sample must contain the characteristic of the population. It should represent the population.

https://pixabay.com/illustrations/rare-disease-population-2888820/
Variable
A variable is any characteristics, things, or number that can be measured or counted. They can be weight, height, age, etc.
They can be numerical variables or categorical variables.
Numerical variable:
The numerical variable can be in units or numbers.
Example: Weight of the students in a class, Height of the students in a class, Age of the students in a class.
Categorical Variable:
A categorical Variable can be a person or thing or characteristics.
Example: Analysing the Hair color of the student, or the blood group of the students in a class.

https://pixabay.com/illustrations/blood-hepatitis-scientist-diabetes-4039751/
Random Variable
Variable means a varying process. Random variable refers to a variable that possesses changes randomly. A random variable cannot be a single fixed value. It keeps changing. It changes because of uncertainty(the state of being uncertain). We measure uncertainty by using the probability concept.
Example: The height of the students in a classroom is an example of a random variable. Because it changes concerning time. It cannot be a definite value.
Random Variables can be of two types,
- Discrete Random Variable
- Continuos Random Variable
Let us discuss this in detail.
1. Discrete Random Variable
Any random variables that can be counted are called discrete random variables. There are no in-between values.
Where we use a discrete random variable in data science?
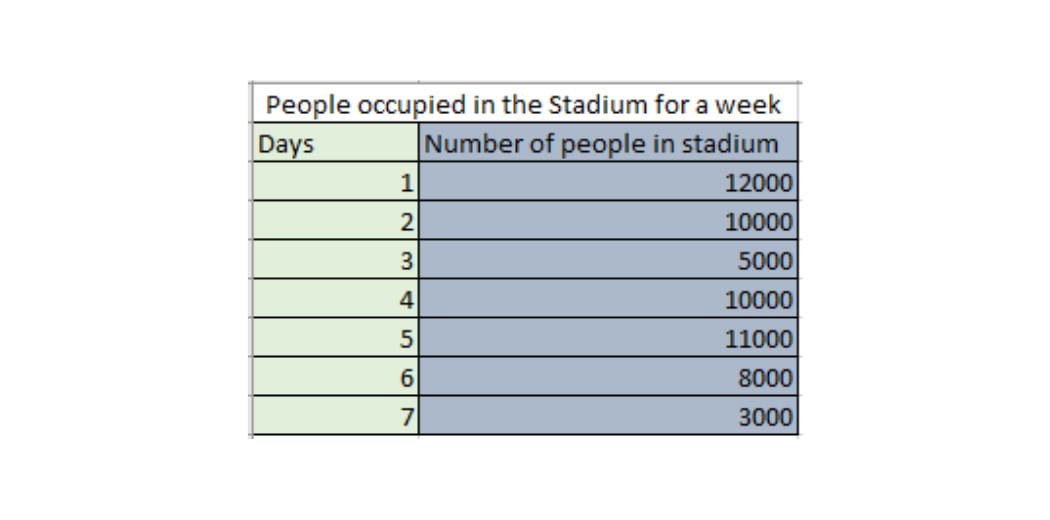
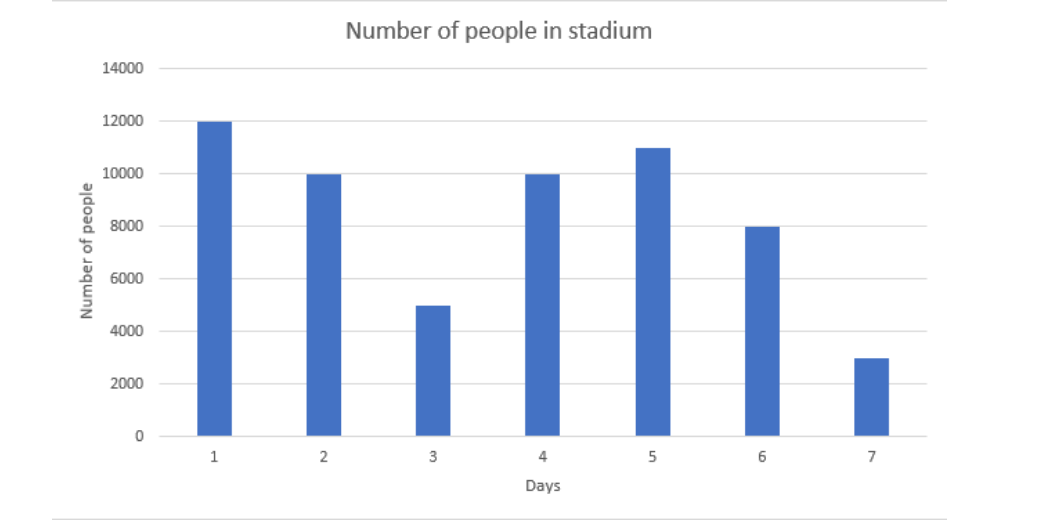
Number of people in a stadium for a week
If you are analyzing a cricket stadium dataset, so you are calculating the number of peoples in a stadium on a particular “day 1”, and you find that there are 12000 peoples on that day. Then this can be expressed as a discrete random variable. This value is definite and it cannot be 11999.50 or 12000.50. It is a countable value, so it comes under discrete random variables.
2. Continuos Random Variable
Any random variable that can be measured and varies continuously is called a continuous random variable. It can have in-between values.
Where we use Continuous random variables in data science?
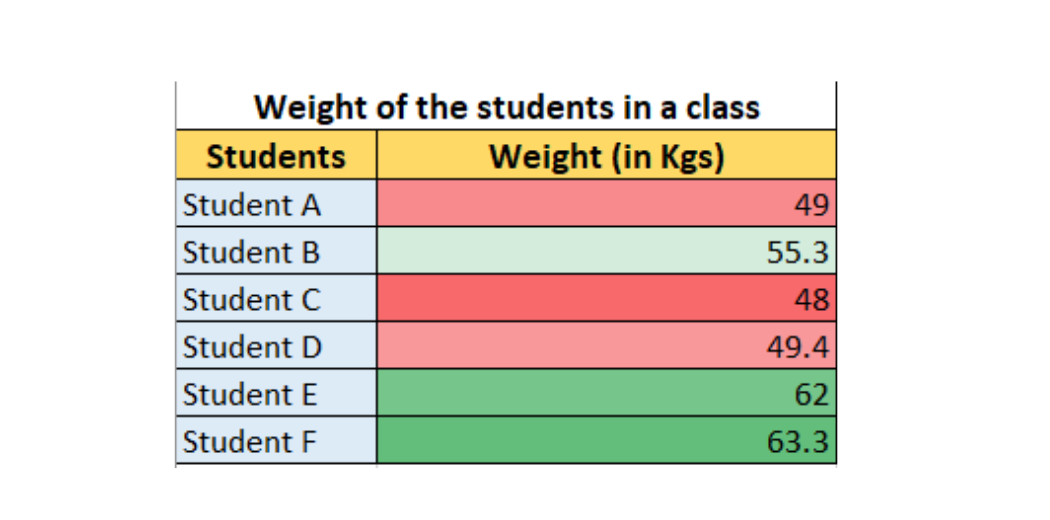
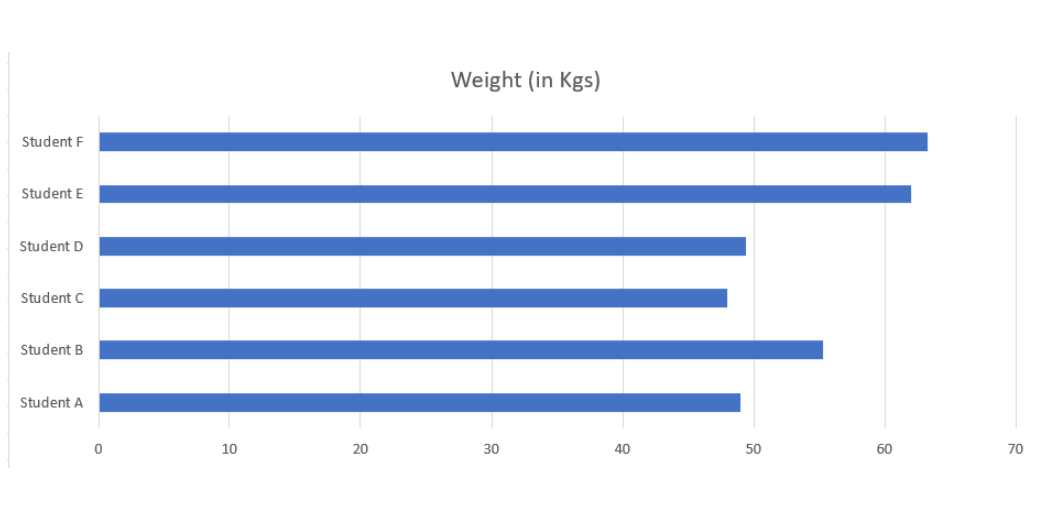
If you are analyzing the weight of the students in a class, then it can be expressed as a continuous random variable. So a “Student A” have 49 Kg and “Student B” have 55.3 Kg. It will not be the same and it varies. It can also have in-between values. So it comes under continuous random variable.
Advantages of collecting data in Continuous Form
→ In Shifting data from the continuous form to discrete, there is no loss in data.
The disadvantage of collecting data in Discrete form
→ In Shifting Data from Discrete form to Continuous form, there is always a loss in data.
Let us see some important terminologies.
Data
Data is pieces of information that can be from a population or sample. Data can be of two types.
Quantitative data
It always represents numbers (i.e) Numerical data. This can be age, height weight, etc. The mean or average taken from the quantitative data is highly useful.
Example: Average weight of the students in a class
Qualitative data
It always represents categorical data. This can be blood group, address of the person, the vehicle of the person, etc. It will be mostly in the form of words or letters. The mean or average taken from the qualitative data doesn’t make sense.
Example: Average blood group or average vehicle name doesn’t make sense.
Percentile
A percentile is a number where a certain percentage of the score falls below that number. It is a relative measure and is identified based on ranking.
Let us see an example with common percentiles,
We are analyzing the sales made by each sales representative in a textile shop in a month
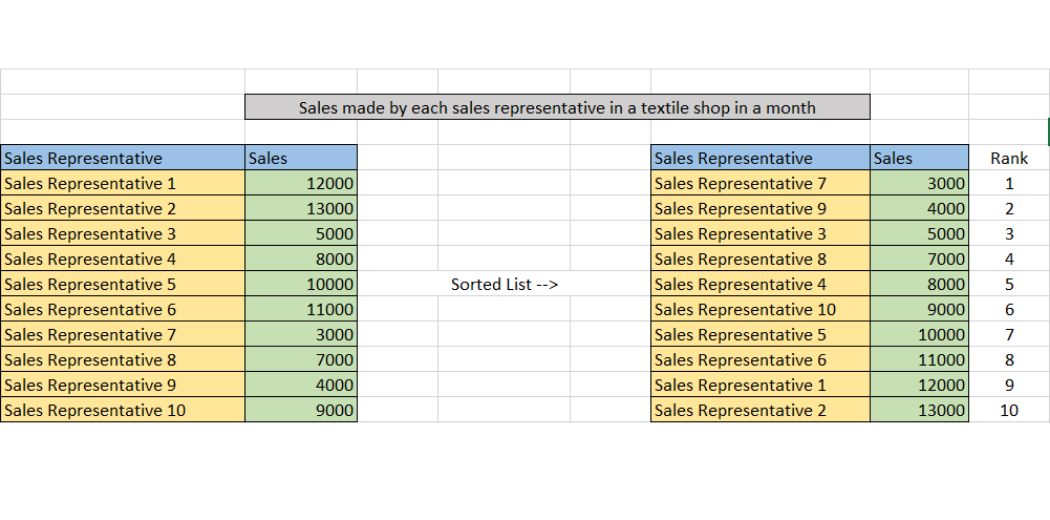
Sales made by each sales representative in a textile shop in a month
Now we can calculate the percentile, First, we will sort the table for better understanding.
Excel gives us a predefined function to calculate percentile.
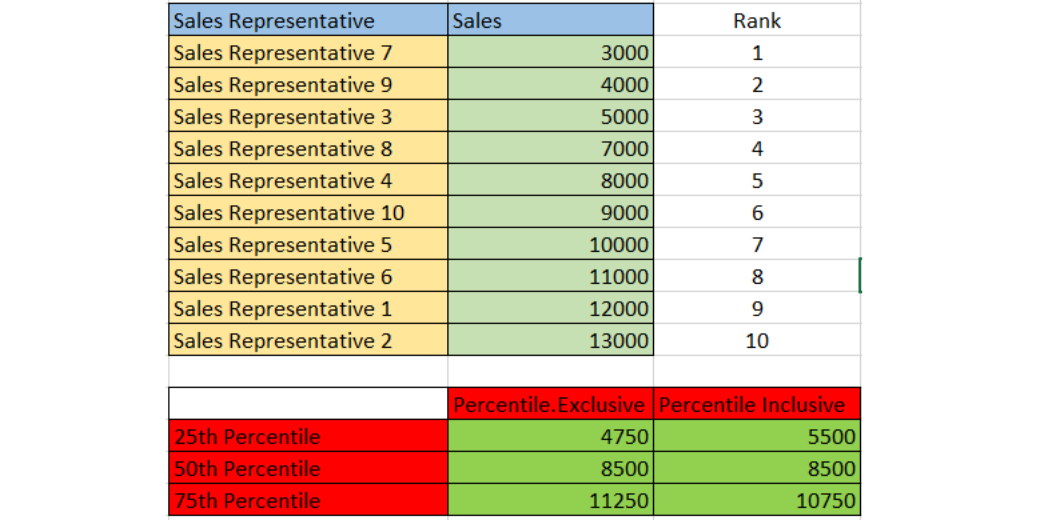
Let us see the meaning of percentile,
For this example, we take percentile inclusive,
25th percentile: 25 % of Salesmen made the sales less than 5500
50th percentile: 50% of Salesmen made the sales less than 8500
75th percentile: 75% of salesmen made the sales less than 10750
Percentile is respect to 100 parts.
if we want to take the whole sales into 100 parts, is percentile.
Decile
if we want to take the whole sales into 10 parts, then it is Decile.
Quartile
If we want to take the whole sales into 4 parts, then it is Quartile
Endnotes
We have seen some basic stat concepts and where it is practically used in datasets. Thanks for reading!
I hope you enjoyed the article and increased your knowledge about Statistics.
Please feel free to contact me at [email protected]
Want to share your thoughts? Feel free to comment below
About the author
Mohamed Illiyas
Currently, I am pursuing my Bachelor of Engineering (B.E) in Computer Science from the Government College of Engineering, Srirangam, Tamil Nadu. I am very enthusiastic about Statistics, Machine Learning, and Data Science.
Connect with me on Linkedin Mohamed Illiyas
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.