



{kind=link}
Introduction
After the immense success of the Mistral-7b model, the team released a new model named Mixtral, a pre-trained ensemble model of eight Mistral-7bs. This is also known as Mixtral MoE (Mixture Of Experts). It instantly became the best open-access model, topping proprietary models like GPT-3.5, Claude-2.1, and Gemini Pro. This model showed an efficient ensemble of small pre-trained models can be an effective alternative to large dense models.
But can we run it on consumer hardware? Despite not being a dense model, running models of this size is still expensive (Note: Mixtral 8x7b has 47 billion parameters.) And it is almost impossible to run this model on cheaper consumer hardware with traditional methods. But with efficient quantization and MoE offloading strategy, we can run a Mixtral MoE on consumer hardware. We will explore how to run a Mixtral 8x7B on a free Colab T4 runtime.
Learning Objectives
- Explore the concept of Mixture of Experts.
- Learn about the quantization and MoE offloading strategy.
- Explore Mixtral MoE on a free Tesla T4 Colab GPU runtime.
Table of contents
This article was published as a part of the Data Science Blogathon.
Mixture Of Experts
The term has been on everyone’s lips since the Mixtral 8x7b’s launch. So, what is an MoE?
The concept of MoE is relatively old. It first appeared in the paper Adaptive Mixture of Local Experts in 1991. The concept is to ensemble multiple networks called experts, each handling a subset of training cases. It is based on the divide and conquer algorithm. Where a problem is divided into smaller sub-tasks, and experts deal with sub-tasks based on their expertise. Imagine a panel of experts solving a big problem, where each expert only works on the problem they have expertise in.
Traditionally, the experts are a group of neural networks, but in practice, any model can be used, like a regression model, classification model, or even other MoEs. But here, we are concerned with LLMs. So we will talk about transformers.
In the context of transformers, MoE primarily consists of two elements. A sparse MoE layer and a gating network or router. So, what is a sparse MoE and Router?
Sparse MoE
In a dense model, all the weights are used for all the inputs, while in a sparse model, only a subset of the original weights are used. In transformers, the dense feed-forward network is replaced by a sparse MoE layer. It may contain multiple experts, like 8 for Mixtral. Each expert specializes in a particular part of a sentence. For example, after training an MoE model over a dataset, we may have experts in counting and numbers, verbs, conjunctions, articles, etc.
Gating Model
So, how does the model decide which experts to pick for an input token? The MoE architecture uses a different neural network called Router for this. A Router or Gating model is a neural network, often smaller than an expert model, that routes tokens to appropriate experts. This model is often trained alongside experts to learn which experts to trust for a given type of token.
Consider the following image of a switch transformer. The FFN layer is replaced with an MoE layer with four experts. The tokens “More” and “Parameters” are routed by a gating network to appropriate experts.
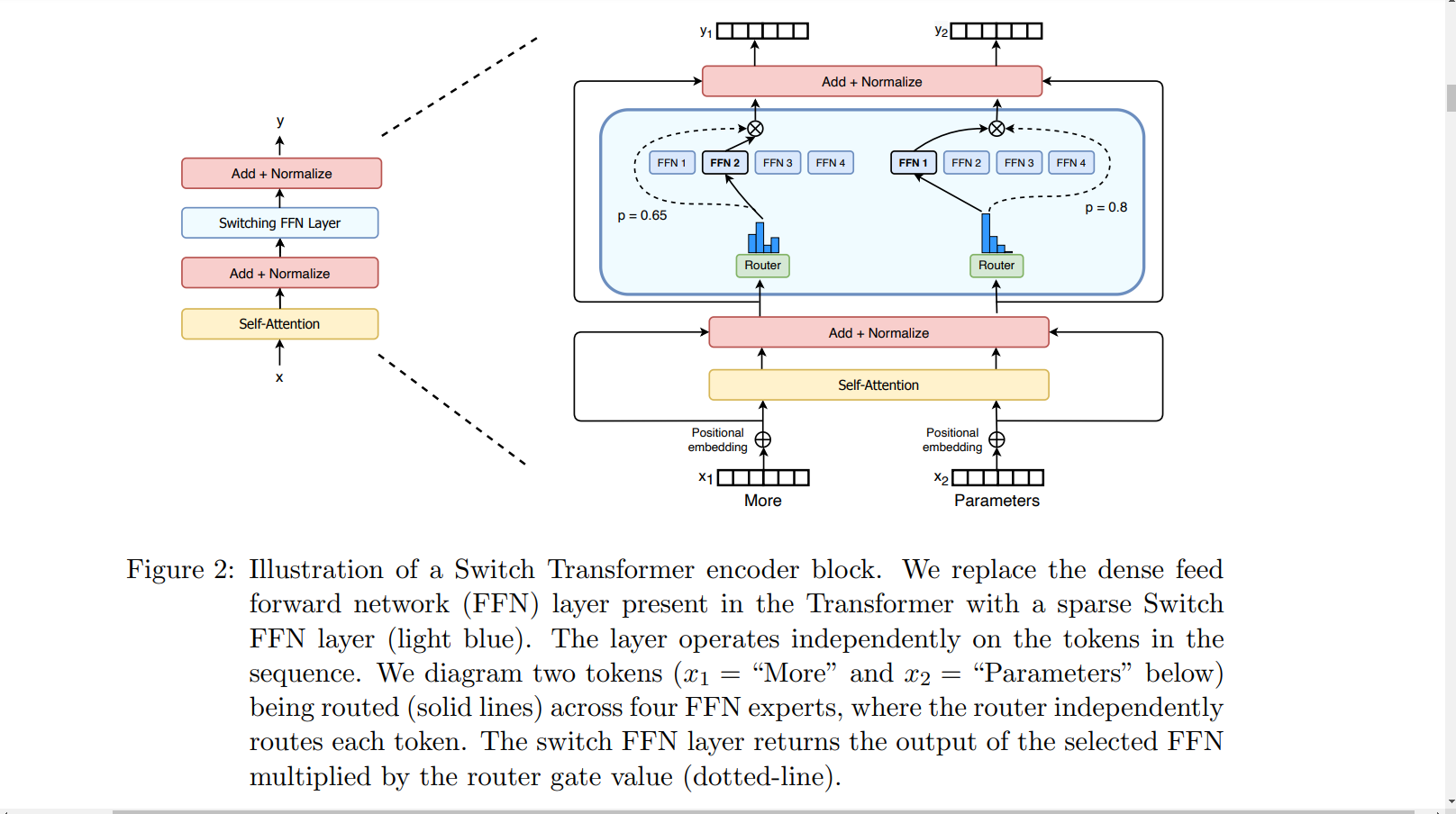
Pros and Cons
The Mixture of Experts has its advantages over the dense models.
- Efficient pre-training: One of the significant benefits of MoEs over dense models is that it is much easier to pre-train MoEs with far less computing than their dense counterparts. The MoEs achieve the same quality of a dense model faster during pre-training.
- Inference Quality: Because multiple expert models are involved during inferencing, the quality of it increases drastically. Due to sparsity, inferencing is faster than the similarly large dense model.
There are also certain shortcomings of MoEs.
- Fine-tuning: One of the bottlenecks for the widespread adoption of MoEs has been the difficulty in fine-tuning the models. There have been active efforts to make fine-tuning easier for MoEs.
- High VRAM usage: The MoEs require high VRAM to be run efficiently, as all the experts need to be loaded into the GPU. This makes it inaccessible from consumer-grade hardware.
So, the question is, how do we run MoEs like Mixtral on cheaper hardware? You must be thinking about quantization. Yes, the quantization technique can help reduce the size of LLMs, but an MoE model with 47B parameters for a 16GB VRAM is still an overkill. But the good thing is some techniques can be leveraged to infer from Mixtral MoE on a T4 GPU.
Parameter Offloading
The authors of this paper came up with a technique to run a quantized Mixtral on consumer hardware using parameter offloading. The process involves a combination of MoE quantization, LRU caching, and speculative expert loading to infer from Mixtral. So, how do we do it?
Quantization
The first step is to quantize the Mixtral MoE. Quantization is about reducing the precision of floating point numbers of the model weight. Higher precision in floats indicates a higher capacity to hold and process information. A 16-bit model will be able to perform better than an 8-bit model. However, a higher bit also means larger models. Quantization compresses the size of the model with a slight trade-off in performance.
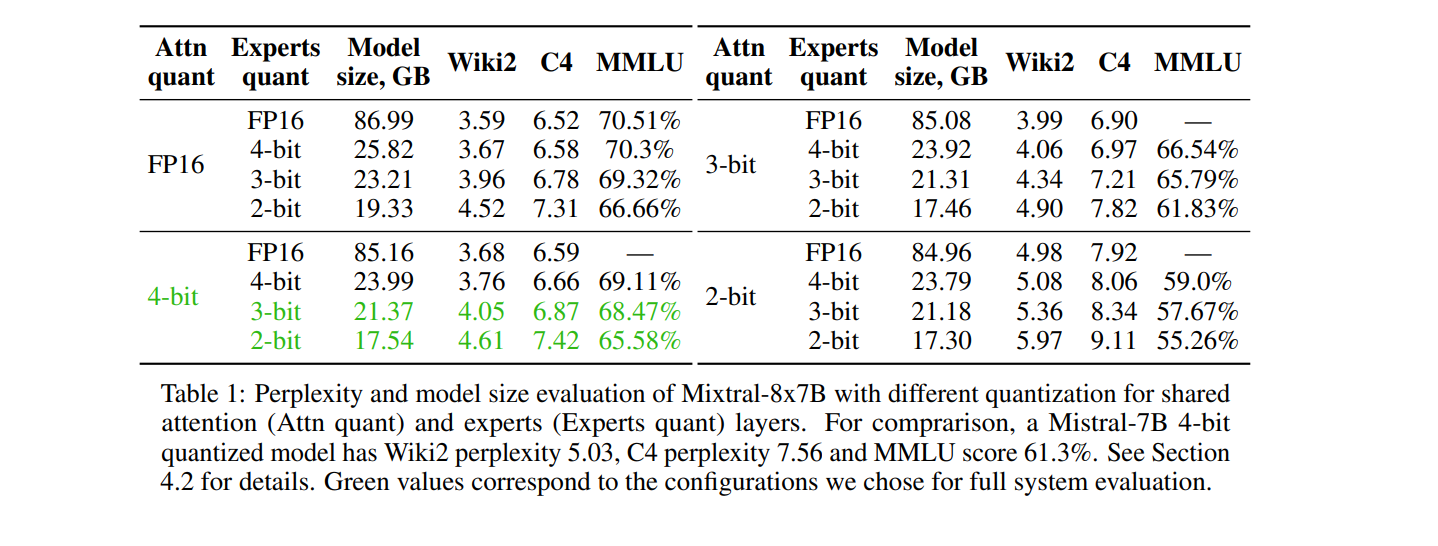
The authors observed a better quality-size trade-off while quantizing experts to lower bitrates. The experts were quantized to 2-bit, while the non-expert layers were quantized to 4-bits. This reduced the full 16-bit Mixtral model of size ~86GB to ~17.54GB with a 5% trade-off on the MMLU benchmark (70.51 to 65.58). This, as you can see, is a significant improvement.
Here’s a chart for other quantization combination
LRU Caching
The next step is to load the experts. As we learned earlier, the MoE allots each token to an expert, but loading all the experts to a T4 VRAM is impossible. To circumvent this, the authors proposed model caching. The algorithm loads the least recently used expert to the GPU. This expert is readily available for input tokens. Thus, inferencing will be fast if a token is routed to this expert. But if it misses, a different expert is activated. In this way, there are no sacrifices in model performances while still achieving faster inferencing. The number of experts(k) in the cache depends on the size of the GPU. If k is greater than the number of active experts, the cache will save experts from previous tokens.
Expert Loading
LRU caching of models speeds up inferencing. But it is still not sufficient. Most of the time during inferencing is spent on loading the next expert. For an MoE, it is difficult to reliably predict which experts to load, as the experts are chosen just in time for computation. However, it was observed that it is possible to make an educated guess of the future expert by applying the next layer’s gating function to the hidden states of the previous layer. If the guess is correct, we get a faster inference. If not, the expert is loaded as usual.
The number of experts to be cached is 2 for 12GB GPU and 4 for 16GB GPU. Once the experts are loaded for a layer, 1-2 experts are fetched with speculative expert loading. If the speculatively loaded expert is used for consecutive tokens, it replaces the least recently used expert in the cache. To make it more efficient while loading experts to the GPU cache, the system offloads the current LRU expert back to RAM.
Mixtral in Colab
Now that we know the strategies. Let’s see it in practice. Open a Colab notebook with T4 GPU runtime.
Fix Triton and install the required dependencies.
import numpy
from IPython.display import clear_output
# fix triton in colab
!export LC_ALL="en_US.UTF-8"
!export LD_LIBRARY_PATH="/usr/lib64-nvidia"
!export LIBRARY_PATH="/usr/local/cuda/lib64/stubs"
!ldconfig /usr/lib64-nvidia
!git clone https://github.com/dvmazur/mixtral-offloading.git --quiet
!cd mixtral-offloading && pip install -q -r requirements.txt
!huggingface-cli download lavawolfiee/Mixtral-8x7B-Instruct-v0.1-offloading-demo \
--quiet --local-dir \
Mixtral-8x7B-Instruct-v0.1-offloading-demo
clear_output()We are downloading a flavor Mixtral Instruct model, which has already been quantized. This will take a while.
Now, import all the dependencies.
import sys
sys.path.append("mixtral-offloading")
import torch
from torch.nn import functional as F
from hqq.core.quantize import BaseQuantizeConfig
from huggingface_hub import snapshot_download
from IPython.display import clear_output
from tqdm.auto import trange
from transformers import AutoConfig, AutoTokenizer
from transformers.utils import logging as hf_logging
from src.build_model import OffloadConfig, QuantConfig, build_modelWe will define the Offload Config, Attention layer quantization config, and Expert or FFN layer config and initialize the model.
model_name = "mistralai/Mixtral-8x7B-Instruct-v0.1"
quantized_model_name = "lavawolfiee/Mixtral-8x7B-Instruct-v0.1-offloading-demo"
state_path = "Mixtral-8x7B-Instruct-v0.1-offloading-demo"
config = AutoConfig.from_pretrained(quantized_model_name)
device = torch.device("cuda:0")
##### Change this to 5 if you have only 12 GB of GPU VRAM #####
offload_per_layer = 4
# offload_per_layer = 5
###############################################################
num_experts = config.num_local_experts
offload_config = OffloadConfig(
main_size=config.num_hidden_layers * (num_experts - offload_per_layer),
offload_size=config.num_hidden_layers * offload_per_layer,
buffer_size=4,
offload_per_layer=offload_per_layer,
)
attn_config = BaseQuantizeConfig(
nbits=4,
group_size=64,
quant_zero=True,
quant_scale=True,
)
attn_config["scale_quant_params"]["group_size"] = 256
ffn_config = BaseQuantizeConfig(
nbits=2,
group_size=16,
quant_zero=True,
quant_scale=True,
)
quant_config = QuantConfig(ffn_config=ffn_config, attn_config=attn_config)
model = build_model(
device=device,
quant_config=quant_config,
offload_config=offload_config,
state_path=state_path,
)The model is loaded, and now we can infer from it.
from transformers import TextStreamer
tokenizer = AutoTokenizer.from_pretrained(model_name)
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
past_key_values = None
sequence = None
seq_len = 0
print("User: ", end="")
user_input = input()
print("\n")
user_entry = dict(role="user", content=user_input)
input_ids = tokenizer.apply_chat_template([user_entry], return_tensors="pt").to(device)
if past_key_values is None:
attention_mask = torch.ones_like(input_ids)
else:
seq_len = input_ids.size(1) + past_key_values[0][0][0].size(1)
attention_mask = torch.ones([1, seq_len - 1], dtype=torch.int, device=device)
print("Mixtral: ", end="")
result = model.generate(
input_ids=input_ids,
attention_mask=attention_mask,
past_key_values=past_key_values,
streamer=streamer,
do_sample=True,
temperature=0.9,
top_p=0.9,
max_new_tokens=512,
pad_token_id=tokenizer.eos_token_id,
return_dict_in_generate=True,
output_hidden_states=True,
)
print("\n")
sequence = result["sequences"]
past_key_values = result["past_key_values"]This will ask for an input string. Once the input is entered, it will generate a response. Below is a query I asked the model to answer.
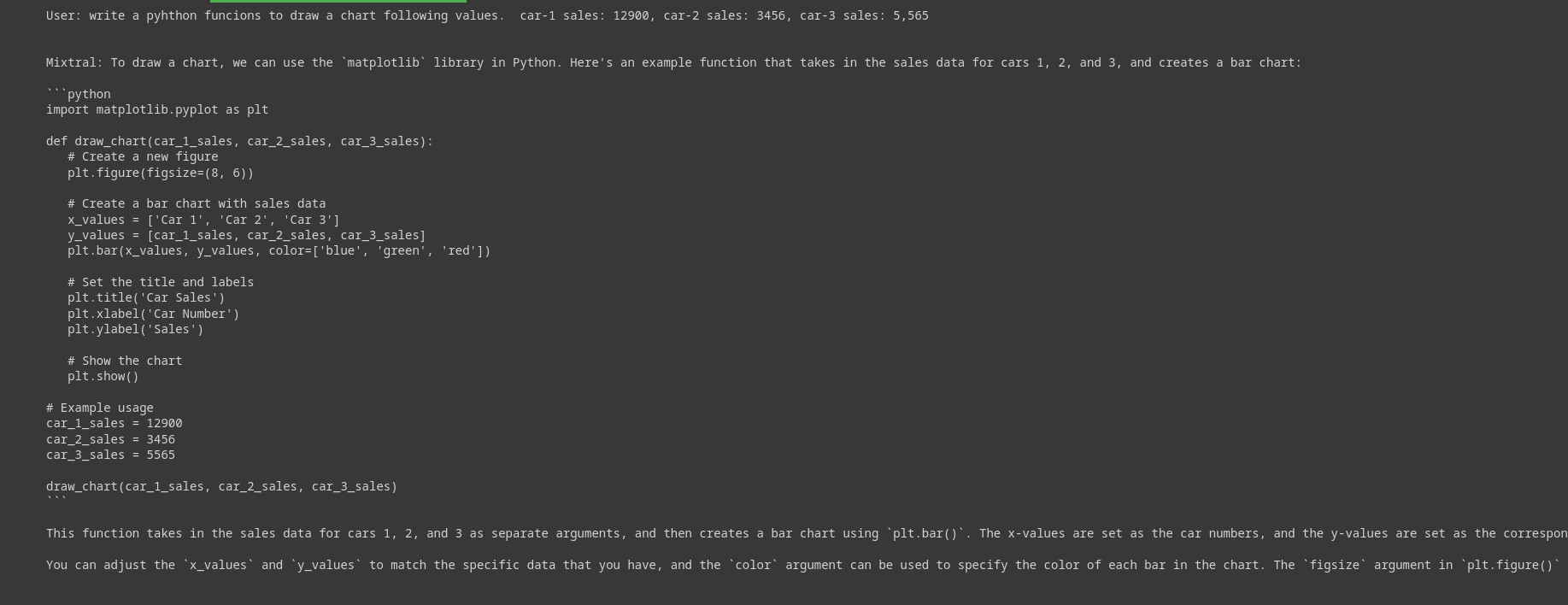
The generation speed is slow, about 2-3 tokens per second. The model is quite heavy and hogs up almost all the resources. This is a resource chart for Mixtral with off-loading on T4 GPU.
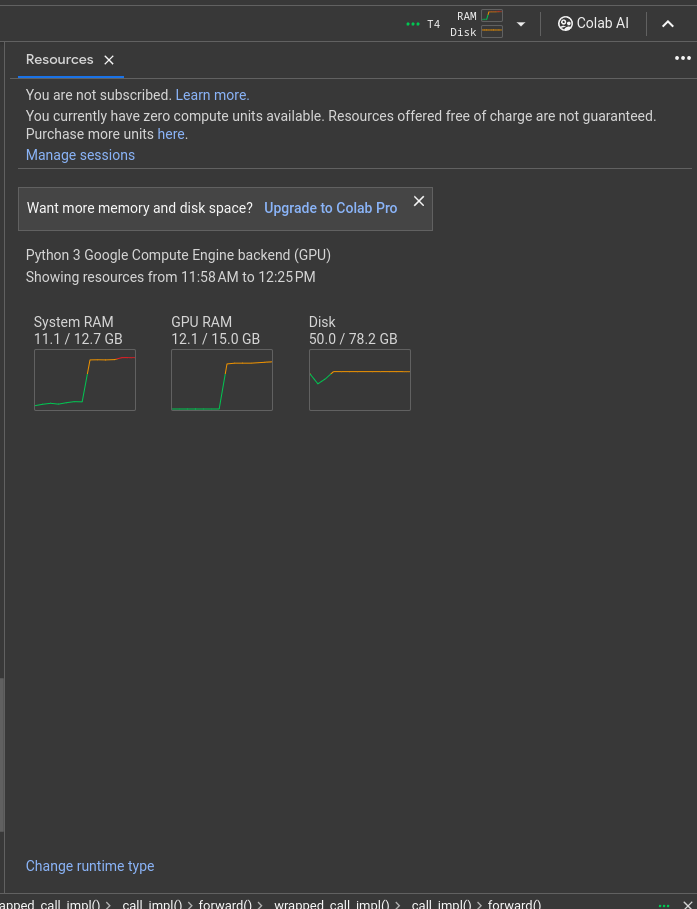
I believe with a 2xT4 instance, the inference will be much better. Nonetheless, cramming up a huge model on a 16GB VRAM and making it work is a big feat.
Conclusion
Mixtral MoE is one of the hottest topics right now for every good reason. It became the first open-access model to dethrone GPT-3.5 on all benchmarks. But Mixtral with 47B parameter is still not accessible to indie developers. In this article, we deep dive into the methods and techniques to run a Mixtral on a free T4 Colab runtime.
So, here are the key takeaways from the article
- The Mixture of Experts is a machine learning method where multiple neural networks, each with its expertise ensemble together to solve a predictive problem.
- In transformers, the dense feed-forward network is replaced by a sparse MoE layer consisting of multiple feed-forward networks.
- The MoE system has a gating network or router for routing tokens to appropriate experts.
- Mixtral is an open-access mixture of expert models from MistralAI. It is an ensemble of eight 7B models. It has a total of 46.7B parameters.
- With MoE quantization, LRU caching, and speculative expert loading, it is possible to infer from Mixtral 8x7b.
References:
- Fast Inference of Mixture-of-Experts Language Models with Offloading
- Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity (Jan 2022)
- Mixture Of Experts Explained
Frequently Asked Question
A. The Mixture of Experts is a machine learning method where multiple neural networks are ensembled to solve a predictive modeling problem in terms of sub-tasks.
A. Mixtral 8x7b is a sparse Mixture of Expert models with state-of-the-art text generation performance among open-access models.
A. Mistral 7b is a dense model with 7 billion parameters, while Mixtral 8x7b is a sparse Mixture of Expert models with 46.7 billion parameters.
A. Mixtral 8x7b is an open-access model under the Apache 2.0 license, meaning it can be used for any commercial activity. So yes, Mixtral 8x7b is an open-source model.
A. With enough GPU, Mixtral 8x7b can be run through tools like Ollama, LM Studio, etc. For limited GPU, it can be run with LRU caching, quantization, and parameter offloading
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.