



{kind=link}
Introduction
Language Models like ChatGPT have taken the world by storm, and now it is tough to find someone utterly naive to its existence. But do you know the success of ChatGPT is much because of the implementation of this concept of using Human Feedback on Reinforcement Learning?
So in today’s blog, we will look into all the details of Reinforcement Learning with Human Feedback (RLHF). As is quite evident, RLHF is derived from Reinforcement Learning, so let’s do a basic and short primer on Reinforcement Learning.
Learning Objectives
- Understanding Reinforcement Learning and the Need for Human Feedback into RL
- The different kinds of Human Feed and how it can be incorporated into RL algorithms
- Learning the different RLHF algorithms and their demonstrative Python codes
- Understanding the challenges and applications of RLHF
This article was published as a part of the Data Science Blogathon.
Table of contents
Reinforcement Learning (RL) and Human Feedback (HF)
RL is a subfield of Machine Learning that focuses on building algorithms and models capable of learning and making decisions interactively. It incorporates the usage of an entity (agent) that interacts with the external system (environment) to determine the current situation or configuration of the environment that the agent perceives (state) and takes a specific move or decision (action) in that particular state. A direct map between states and actions represents the agent’s strategy or behavior (policy). The policy defines how the agent chooses actions based on the current state and can be deterministic or stochastic.
After taking action in a specific condition, the agent receives a scaler feedback signal from the environment (reward), which helps serve the quality of the agent’s actions and guides it to learn the optimal behavior. The main objective of RL is to find an optimal policy that maximizes the expected cumulative reward over time. Typically, the agent achieves this by exploring different actions to gather information about the environment and exploiting its learned knowledge to make better decisions. Below is a schematic of the RL framework.

There exists an issue in this process of exploration and exploitation. RL agents often start with limited knowledge about the environment and the task. So it might end up consuming more resources than desired. HF helps provide valuable guidance and helps accelerate the process by enabling the agent to learn from human expertise, understand desirable behavior, and avoid unnecessary exploration or suboptimal actions. Human feedback can shape the reward signal to emphasize important aspects of the task, provide demonstrations for imitation, and offer detailed evaluations to refine the agent’s behavior. By leveraging human feedback, RL agents can learn more efficiently and perform better in complex real-world scenarios.
Types of Human Feedback
The input HF in an RL model can take various forms, such as reward shaping, demonstrations, or detailed evaluations, and it plays a crucial role in improving the agent’s performance and accelerating the learning process. Below we will look into each HFs in detail and try to understand their usability and pros and cons.
Reward Shaping
It involves providing explicit rewards or penalties to the RL agent based on its actions. Human experts can design reward functions to reinforce the desired rewards and discourage undesired behavior. This feedback form helps the agent learn the optimal policy by maximizing its cumulative compensation.
Pros:
- Faster Learning: Providing informative rewards helps converge to the optimal policy more quickly.
- Guided Exploration: It only allows exploration of the promising regions of the state-action space.
Cons:
- Potential Bias: Often, it may introduce biases if implemented improperly, thus influencing the agent’s behaviors in the wrong way thus leading to suboptimal policies.
- Incorrect Shaping: Designing the correct shaping functions is challenging and should always be done
Demonstrations
This involves human experts or demonstrators showcasing the desired behavior by showcasing the desired actions or trajectories. The RL agent then learns or imitates these behaviors to develop and generalize policies.
Pros:
- Efficient Learning: The learning process can be increased incrementally by adding the demonstrator’s knowledge to the agent’s initial knowledge.
- Safe Exploration: By imitating expert behavior, the agent can avoid potentially harmful or inefficient actions during the exploration phase.
Cons:
- Lack of Exploration: By solely depending on the expert’s knowledge, the RL agent may be deprived of its inherent tendency to explore and discover novel solutions, thus limiting its capabilities.
- Expert Sub-optimality: The availability of high-quality demonstrators is limited and costly, and using imperfect or suboptimal demonstrators might lead the RL agent to inherit the limitations.
Critiques and Advice
Humans critique or advise the agent’s learned policies in this feedback form. They can evaluate the agent’s behavior or suggest improvements to enhance performance. This feedback helps iteratively refine the agent’s policies and align them more with human preferences.
Pros:
- Fine-grained Guidance: Humans can provide specific feedback to help the agent improve its behavior in a targeted manner.
- Policy Refinement: Iterative feedback and advice can enhance the agent’s policies over time.
Cons:
- Subjectivity: Human feedback may vary, challenging reconciling conflicting advice or critiques.
- Feedback Quality: The quality and relevance of human advice can vary, and suboptimal feedback may hinder learning progress.
Ranking and Preferences
Human experts provide the RL agent with rankings or preferences for the agent’s different actions or policies. By comparing the options, the RL agent can develop the optimal moves.
Pros:
- Preference Learning: Incorporating human preferences allows the agent to focus on actions or policies more likely to be desired by humans.
- Fine-grained Control: Humans can communicate nuanced preferences, enabling the agent to optimize for specific criteria.
Cons:
- Subjectivity: Human preferences may vary, making it challenging to reconcile conflicting feedback.
- Limited Feedback Granularity: Assigning precise scores or rankings to actions or policies may be difficult for humans, leading to less informative feedback.
Approaches to Incorporate HF into RL
We have already explored and become aware of the types of HFs that can be implemented into an RL agent. Now let’s see how we can incorporate these HFs into the RL agent. Several strategies have been implemented, and many new ones are coming up with the passing days. Let’s explore some of these approaches briefly.
Interactive Learning
Interactive learning methods involve the learning agent directly engaging with human experts or users. This engagement can occur in various ways, such as the agent asking humans for advice, clarification, or preferences while learning. The agent actively seeks feedback and adapts its behavior based on input. A schematic of IRL is shown below (src)
- Active Learning: The agent selects informative instances or queries humans for feedback on specific data points to accelerate learning.
- Online Learning: The agent receives real-time feedback from humans, continuously adapting its policy based on the received feedback.

Imitation Learning
Imitation learning, or learning from demonstrations, refers to acquiring a policy by emulating expert behavior. Expert humans provide sample trajectories or actions, and the agent can mimic the demonstrated behavior. A schematic is shown below. (src)
- Behavioral Cloning: The agent learns to mimic the demonstrated behavior by mapping observations to actions. It aims to match the expert’s efforts without considering the underlying reward signal.
- Inverse Reinforcement Learning: The agent infers the underlying reward function from expert demonstrations, enabling it to learn a policy that aligns with the expert’s preferences.

Reward Engineering
Reward engineering involves modifying the reward signal to guide the agent’s learning. Human experts design shaping functions or provide additional rewards that encourage desired behavior or penalize undesirable actions. A generalized integration of the reward function is shown below. (src)
- Reward Shaping: Shaped rewards are added to the environment’s intrinsic reward signal to provide additional guidance to the agent.
- Reward Modelling: Human experts explicitly model the reward function based on their preferences or domain knowledge, allowing the agent to learn from the expert’s reward model.

Preference-based Learning
Preference-based learning methods involve gathering comparisons or rankings of different actions or policies from human evaluators. The agent learns to optimize its behavior based on the observed preferences. A schematic is shown below. (src)
- Pair-wise Comparison: Humans provide preferences by comparing pairs of actions or policies and indicating their preferred option.
- Rank-based Comparison: Humans rank different options based on their desirability, providing a relative ordering of actions or policies.

Natural Language Feedback
This allows humans to communicate using natural language instructions, critiques, or explanations with the learning agent. The agent then processes the textual input and adapts its behavior accordingly. A schematic is shown below. (src)
- Text-based Reinforcement Learning: The agent incorporates natural language instructions or feedback to guide decision-making.
- Language Grounding: The agent learns to associate textual feedback with specific states or actions to understand and respond to human instructions.

HF Collection and Annotation
We can now understand the types of HFs and the systematic collection of HFs from humans and experts. The feedback collected is invaluable in understanding desired behavior, refining policies, and accelerating the learning process. Once the input is collected, it undergoes meticulous annotation, which involves labeling actions, states, rewards, or preferences. Annotation provides a structured representation of the feedback, making it easier for RL algorithms to learn from the human expertise encapsulated within the data. By leveraging annotated human feedback, RL agents can align their decision-making processes with desired outcomes and improve performance, ultimately bridging the gap between human intent and machine intelligence.
Algorithms for RLHF
Q-Learning with Human Feedback
Q-learning with human feedback is an approach to reinforcement learning that incorporates human guidance to improve the learning process. In traditional Q-learning, an agent learns by interacting with an environment and updating its Q-values based on rewards. However, in Q-learning with human feedback, humans provide additional information, such as rewards, critiques, or rankings, to guide the learning agent. This human feedback helps accelerate learning, reducing exploration time and avoiding undesirable actions. The agent combines human feedback with exploration to update its Q-values and improve its policy. Q-learning with human feedback enables more efficient and effective learning by leveraging human expertise and preferences.
Below is a code snippet of how you can perform Q-learning with HF.
import numpy as np
# Define the Q-learning agent
class QLearningAgent:
def __init__(self, num_states, num_actions, alpha, gamma):
self.num_states = num_states
self.num_actions = num_actions
self.alpha = alpha # learning rate
self.gamma = gamma # discount factor
self.Q = np.zeros((num_states, num_actions)) # Q-table
def update(self, state, action, reward, next_state):
max_next_action = np.argmax(self.Q[next_state])
self.Q[state, action] += self.alpha * (reward + self.gamma
* self.Q[next_state, max_next_action] - self.Q[state, action])
def get_action(self, state):
return np.argmax(self.Q[state])
# Create the Q-learning agent
num_states = 10
num_actions = 4
alpha = 0.5
gamma = 0.9
agent = QLearningAgent(num_states, num_actions, alpha, gamma)
# Run Q-learning with human feedback
num_episodes = 1000
for episode in range(num_episodes):
state = 0 # initial state
done = False
while not done:
# Get action from Q-learning agent
action = agent.get_action(state)
# Simulate environment and get reward and next state
reward = simulate_environment(state, action)
next_state = get_next_state(state, action)
# Update Q-value using Q-learning
agent.update(state, action, reward, next_state)
# Update state
state = next_state
# Check if the goal state is reached
if state == goal_state:
done = True
print("Episode {}: Goal reached!".format(episode + 1))
break
# Get human feedback for the action
human_feedback = get_human_feedback(state, action)
# Update Q-value using human feedback
agent.update(state, action, human_feedback, next_state)
# Function to simulate the environment and return the reward
def simulate_environment(state, action):
# Your environment simulation code here
# Return the reward for the action in the current state
pass
# Function to get the next state based on the current state and action
def get_next_state(state, action):
# Your code to determine the next state based on the current state and action
pass
# Function to get human feedback for the action in the current state
def get_human_feedback(state, action):
# Your code to get human feedback for the action in the current state
pass
Apprenticeship Learning
Apprenticeship learning is a technique in machine learning that allows an agent to learn from expert demonstrations. In contrast to traditional reinforcement learning, where the agent learns through trial and error, apprenticeship learning focuses on imitating the behavior of human experts. Observing expert demonstrations, the agent infers the underlying reward function or policy and aims to replicate the demonstrated behavior. This approach is instrumental in complex domains where it may be challenging to define a reward function explicitly. Apprenticeship learning enables agents to learn from human demonstrators’ accumulated knowledge and expertise, facilitating efficient and high-quality learning.
Below is an example of Python code for Apprenticeship Learning using the Inverse Reinforcement Learning (IRL) algorithm.
import numpy as np
# Define the expert's policy
def expert_policy(state):
# Your expert policy implementation here
pass
# Define the feature function
def compute_features(state):
# Your feature computation code here
pass
# Define the IRL algorithm
def irl_algorithm(states, actions, expert_policy, compute_features,
num_iterations):
num_states = len(states)
num_actions = len(actions)
num_features = len(compute_features(states[0]))
# Initialize the reward weights randomly
weights = np.random.rand(num_features)
for iteration in range(num_iterations):
# Accumulate feature expectations under the current policy
feature_expectations = np.zeros(num_features)
for state in states:
expert_action = expert_policy(state)
state_features = compute_features(state)
feature_expectations += state_features
# Compute the policy using the current reward weights
policy = compute_policy(states, actions, weights, compute_features)
# Accumulate feature expectations under the learned policy
learned_expectations = np.zeros(num_features)
for state in states:
learned_action = policy[state]
state_features = compute_features(state)
learned_expectations += state_features
# Update the reward weights using the difference between the
feature expectations
weights += (feature_expectations - learned_expectations)
return weights
# Define the policy computation function
def compute_policy(states, actions, weights, compute_features):
policy = {}
for state in states:
max_value = float('-inf')
max_action = None
for action in actions:
state_features = compute_features(state)
action_value = np.dot(state_features, weights)
if action_value > max_value:
max_value = action_value
max_action = action
policy[state] = max_action
return policy
# Example usage
states = [1, 2, 3, 4] # List of possible states
actions = [0, 1, 2] # List of possible actions
# Run the IRL algorithm
num_iterations = 1000
learned_weights = irl_algorithm(states, actions, expert_policy,
compute_features, num_iterations)
print("Learned weights:", learned_weights)Deep Reinforcement Learning with Human Feedback
Deep Reinforcement Learning (DRL) with Human Feedback combines deep learning techniques with reinforcement learning and human guidance. This approach employs a deep neural network as a function approximator to learn from the environment and human feedback. Human feedback can be provided in various forms, such as demonstrations, reward shaping, critiques, or preference rankings. The deep network, often a deep Q-network (DQN), is trained to optimize its policy by integrating environmental rewards and human feedback signals. This fusion of human expertise and deep reinforcement learning allows agents to leverage the power of deep neural networks while benefiting from the guidance and knowledge provided by human evaluators, leading to more efficient learning and improved performance in complex environments.
Below is an example of Python code for Deep Reinforcement Learning with Human Feedback using the Deep Q-Network (DQN) algorithm.
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam
# Define the DQN agent
class DQNAgent:
def __init__(self, state_size, action_size, learning_rate, gamma):
self.state_size = state_size
self.action_size = action_size
self.learning_rate = learning_rate
self.gamma = gamma
self.epsilon = 1.0 # exploration rate
self.epsilon_decay = 0.995 # exploration decay rate
self.epsilon_min = 0.01 # minimum exploration rate
self.model = self.build_model()
def build_model(self):
model = Sequential()
model.add(Dense(24, input_dim=self.state_size, activation='relu'))
model.add(Dense(24, activation='relu'))
model.add(Dense(self.action_size, activation='linear'))
model.compile(loss='mse', optimizer=Adam(learning_rate=self.learning_rate))
return model
def act(self, state):
if np.random.rand() <= self.epsilon:
return np.random.randint(self.action_size)
q_values = self.model.predict(state)
return np.argmax(q_values[0])
def update(self, state, action, reward, next_state, done):
target = self.model.predict(state)
if done:
target[0][action] = reward
else:
q_future = max(self.model.predict(next_state)[0])
target[0][action] = reward + self.gamma * q_future
self.model.fit(state, target, epochs=1, verbose=0)
def decay_epsilon(self):
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
# Define the environment
class Environment:
def __init__(self, num_states, num_actions):
self.num_states = num_states
self.num_actions = num_actions
def step(self, action):
# Your code to perform a step in the environment and return
the next state, reward, and done flag
pass
def get_human_feedback(self, state, action):
# Your code to obtain human feedback for the given state and action
pass
# Create the DQN agent and the environment
num_states = 10
num_actions = 4
learning_rate = 0.001
gamma = 0.99
agent = DQNAgent(num_states, num_actions, learning_rate, gamma)
env = Environment(num_states, num_actions)
# Run the DQN agent with human feedback
num_episodes = 1000
for episode in range(num_episodes):
state = 0 # initial state
state = np.reshape(state, [1, num_states])
done = False
while not done:
# Get action from DQN agent
action = agent.act(state)
# Simulate environment and get reward, next state, and done flag
next_state, reward, done = env.step(action)
# Get human feedback for the action
human_feedback = env.get_human_feedback(state, action)
# Update DQN agent based on human feedback
agent.update(state, action, human_feedback, next_state, done)
# Update state
state = next_state
# Decay exploration rate
agent.decay_epsilon()
# Check if the goal state is reached
if done:
printPolicy Search Methods Incorporating Human Feedback
Policy search methods incorporating human feedback aim to optimize the policy of a reinforcement learning agent by leveraging human expertise. These methods involve iteratively updating the approach based on human feedback signals such as demonstrations, critiques, or preferences. A parametric model, typically representing the policy and human feedback, guides exploring and exploiting the policy space. Additionally, by incorporating human feedback, we can accelerate learning of policy search methods, improve sample efficiency, and align the agent’s behavior with human preferences. The combination of policy search and human feedback enables the agent to benefit from the rich knowledge and guidance human evaluators provide. Thus, leading to more effective and reliable policy optimization.
Here is an example of Python code for a Policy Search method that incorporates Human Feedback:
import numpy as np
# Define the policy
def policy(state, theta):
# Your policy implementation here
pass
# Define the reward function
def reward(state, action):
# Your reward function implementation here
pass
# Define the policy search algorithm with human feedback
def policy_search_with_feedback(states, actions, policy, reward, num_iterations):
num_states = len(states)
num_actions = len(actions)
num_features = len(states[0]) # Assuming states are feature vectors
# Initialize the policy weights randomly
theta = np.random.rand(num_features)
for iteration in range(num_iterations):
gradient = np.zeros(num_features)
for state in states:
action = policy(state, theta)
action_index = actions.index(action)
state_features = np.array(state)
# Obtain human feedback for the action
human_feedback = get_human_feedback(state, action)
# Update the gradient based on the human feedback
gradient += human_feedback * state_features
# Update the policy weights using the gradient
theta += gradient
return theta
# Function to obtain human feedback for the given state and action
def get_human_feedback(state, action):
# Your code to obtain human feedback for the given state and action
pass
# Example usage
states = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] # List of states (feature vectors)
actions = [0, 1, 2] # List of possible actions
# Run the policy search algorithm with human feedback
num_iterations = 1000
learned_weights = policy_search_with_feedback(states, actions, policy,
reward, num_iterations)
print("Learned weights:", learned_weights)
Model-Based Reinforcement Learning with Human Feedback
Model-based reinforcement learning with human feedback involves incorporating human guidance and expertise into the building and utilizing a learned environment model. This approach combines model-based RL techniques with human feedback, such as demonstrations or critiques, to improve the accuracy and generalization capabilities of the learned model. We can use human feedback to refine the model’s predictions and guide the agent’s decision-making process. Also, by leveraging human knowledge and model-based RL with human feedback, we can enhance sample efficiency, accelerate learning, and enable better policy optimization. This integration of human feedback within the model-based RL framework allows agents to leverage the strengths of human expertise and learned models. Thus, resulting in more effective and robust decision-making in complex environments.
Here’s an example of Python code for Model-Based Reinforcement Learning with Human Feedback.
import numpy as np
# Define the environment dynamics model
class EnvironmentModel:
def __init__(self, num_states, num_actions):
self.num_states = num_states
self.num_actions = num_actions
self.transition_model = np.zeros((num_states, num_actions, num_states))
self.reward_model = np.zeros((num_states, num_actions))
def update_model(self, state, action, next_state, reward):
self.transition_model[state, action, next_state] += 1
self.reward_model[state, action] = reward
def get_transition_probability(self, state, action, next_state):
count = self.transition_model[state, action, next_state]
total_count = np.sum(self.transition_model[state, action])
if total_count == 0:
return 0
return count / total_count
def get_reward(self, state, action):
return self.reward_model[state, action]
# Define the policy
def policy(state):
# Your policy implementation here
pass
# Define the Q-learning algorithm
def q_learning(environment_model, num_states, num_actions,
num_episodes, alpha, gamma, epsilon):
Q = np.zeros((num_states, num_actions))
for episode in range(num_episodes):
state = 0 # initial state
while state != goal_state:
if np.random.rand() <= epsilon:
action = np.random.randint(num_actions)
else:
action = np.argmax(Q[state])
next_state = np.random.choice(num_states,
p=environment_model.transition_model[state, action])
reward = environment_model.reward_model[state, action]
Q[state, action] += alpha * (reward + gamma *
np.max(Q[next_state]) - Q[state, action])
state = next_state
return Q
# Function to obtain human feedback for the given state and action
def get_human_feedback(state, action):
# Your code to obtain human feedback for the given state and action
pass
# Example usage
num_states = 10
num_actions = 4
num_episodes = 1000
alpha = 0.5
gamma = 0.9
epsilon = 0.1
# Create the environment model
environment_model = EnvironmentModel(num_states, num_actions)
# Collect human feedback and update the environment model
for episode in range(num_episodes):
state = 0 # initial state
while state != goal_state:
action = policy(state)
next_state = get_next_state(state, action)
reward = get_reward(state, action)
environment_model.update_model(state, action, next_state, reward)
state = next_state
# Run Q-learning with the learned environment model
Q = q_learning(environment_model, num_states, num_actions,
num_episodes, alpha, gamma, epsilon)
print("Learned Q-values:", Q)Challenges of RLHF
We must address the challenges that Reinforcement learning with human feedback presents to integrate and utilize human guidance effectively. Some of the key challenges include:
- Feedback Quality and Consistency: Human feedback can be subjective and inconsistent, making it challenging to interpret and use effectively. Different humans may have other preferences, leading to conflicting guidance. Ensuring high-quality and reliable feedback becomes crucial for training accurate and robust reinforcement learning models.
- Scalability and Cost: Collecting and annotating human feedback can be resource-intensive, time-consuming, and costly. As the complexity of tasks and environments increases, obtaining sufficient and diverse feedback becomes more challenging, especially with large-scale or real-time systems.
- Exploration-Exploitation Tradeoff: Balancing exploration and exploitation in reinforcement learning is crucial for learning optimal policies. Incorporating human feedback without undermining exploration becomes a challenge. Over-reliance on human guidance can limit the agent’s ability to explore and discover novel solutions.
- Generalization and Transfer Learning: Human feedback is often specific to a particular task or environment. Generalizing human guidance to new scenarios or domains becomes non-trivial. Ensuring that the learned policies and models can transfer knowledge from one context to another is a significant challenge.
- Subjectivity and Bias: Human feedback can be subjective and influenced by personal preferences, biases, or context-dependent factors. Addressing bias in feedback and ensuring fairness and inclusivity become essential considerations.
- Feedback Delay and Feedback Inconsistency: Obtaining real-time feedback from humans may not always be feasible. Feedback delays can hinder the learning process, especially in dynamic environments. Additionally, inconsistencies or changing feedback over time can challenge maintaining policy coherence.
Understanding human feedback’s limitations and potential biases is crucial for practical integration into reinforcement learning systems.
Applications of RLHF
Reinforcement learning with human feedback has found applications in various domains where human guidance and expertise are valuable for enhancing the learning process and improving the performance of intelligent systems. Some common areas where you can find applications of reinforcement learning with human feedback include:
- Robotics: Firstly, one can employ Reinforcement learning with human feedback in robotics for tasks such as robot manipulation, object grasping, and locomotion. Human experts can provide demonstrations or critiques to guide the robot’s learning and improve its performance in real-world environments.
- Game Playing: Additionally, we can use reinforcement learning with human feedback to train game-playing agents. Human experts can provide demonstrations or rankings to enhance the agent’s decision-making, strategy, and overall gameplay.
- Autonomous Vehicles: One can apply Reinforcement learning with human feedback to autonomous vehicle systems. Human feedback can help train the vehicle to navigate complex traffic scenarios, improve safety, and handle challenging driving situations.
- Dialogue Systems: In addition, we can train conversational agents to train using reinforcement learning with human feedback in natural language processing and dialogue systems. Human evaluations, critiques, or preferences can guide the agent’s responses, improve dialogue coherence, and enhance user satisfaction.
- Healthcare: Furthermore, we can explore Reinforcement learning with human feedback in healthcare applications, such as personalized treatment planning, medical diagnosis, and drug discovery. Human feedback can aid in optimizing treatment decisions and improving patient outcomes.
- Recommender Systems: Lastly, we can employ reinforcement learning with human feedback in recommendation systems to learn user preferences and provide personalized recommendations. Human feedback in the form of ratings, reviews, or explicit preferences can guide the system to make more accurate and relevant recommendations.
These are just a few examples, and the applications of reinforcement learning with human feedback are expanding across various domains, including education, finance, intelligent homes, and more.
ChatGPT: A Success Story in RLHF
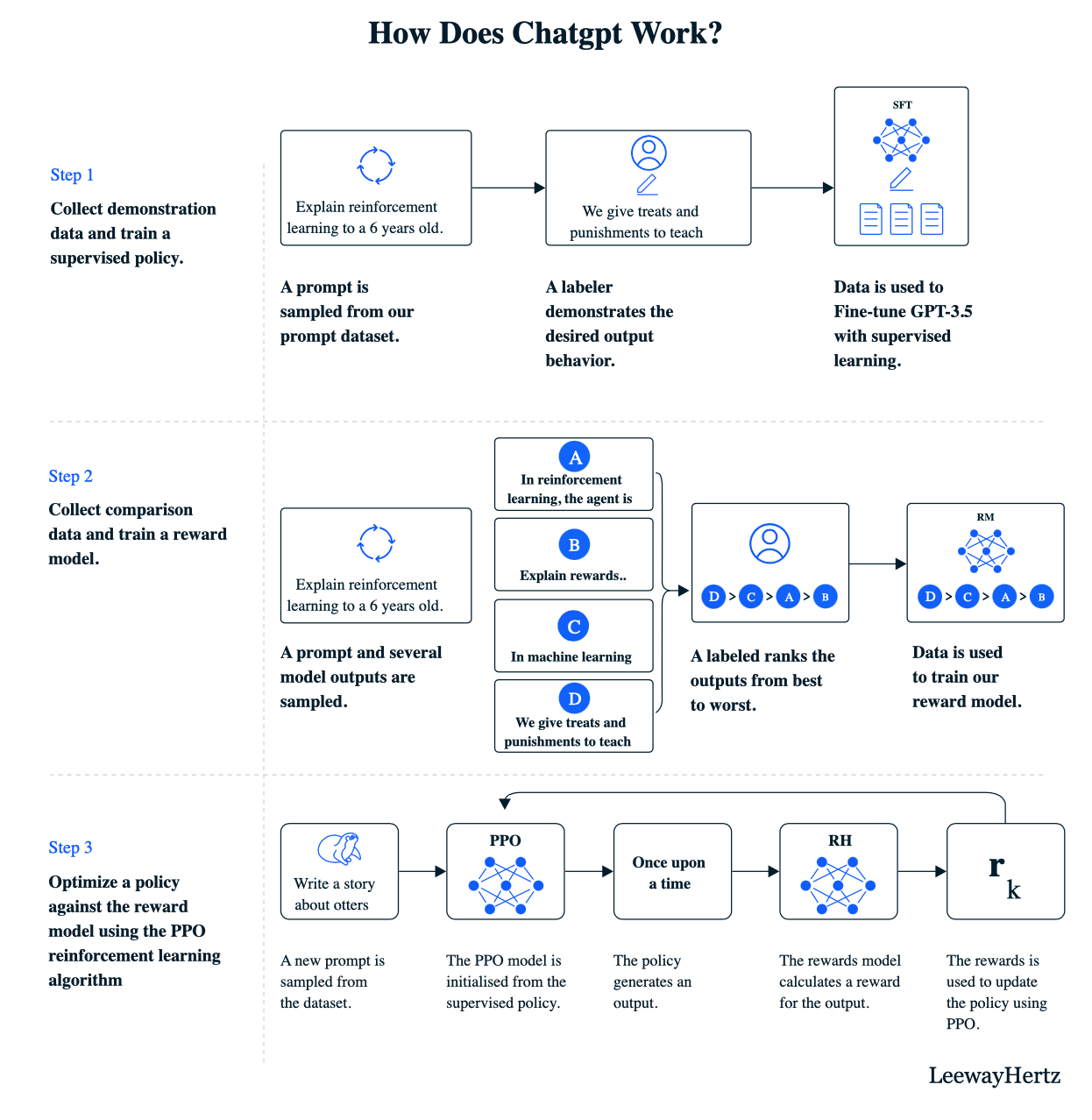
Remember how we started with ChatGPT? Now that we completely understand all the concepts involved in RLHF, let’s have the final strike at today’s learning and finish understanding how ChatGPT works! Exciting right?
Large Language Models (LLMs) initially undergo unsupervised training on vast amounts of text data to understand language patterns. Introducing RLHF to address limitations like low-quality and irrelevant outputs. This involves training a reward model using human evaluators who rank the LLM-generated text based on quality. The reward model predicts these scores, capturing human preferences. In a feedback loop, the LLM acts as an RL agent, receiving prompts and generating text, which the reward model then evaluates. The LLM updates its output based on higher reward scores, improving performance through reinforcement learning. RLHF enhances LLMs by incorporating human feedback and optimizing textual outputs.
Below is a schematic of how ChatGPT works.
Conclusion
Reinforcement Learning (RL) is a machine learning technique where the agent knows to make decisions by interacting with an environment and receiving feedback in the form of rewards or penalties. Now, the exploration process of RL can be slow, and hence it is desirable to improve it by adding Human Factors (HFs). You can incorporate these HFs in many ways with the RL algorithm. Once you gather the feedback, you must adequately annotate and label it as actions, states, and rewards.
Thus, several RLHF algorithms are architected for that purpose: Q-Learning with HF, Apprenticeship Learning, DRL with HF, and Model-based RL with HF. Although it may appear that including HF solves all the problems and now our RL models should be perfect, there exist challenges to the same, the predominant one being the feedback quality, consistency, and biases in feedback.
The key takeaways from the blog include the following:
- An understanding of all the critical terms in RL and how agent, environment, action, and reward interplay to help achieve the optimal outcome
- Why we need Human Feedback on Rl and how it improves the output of the model
- The different types of HFs, namely reward shaping, demonstration, critique and advice, ranking and preference, and their useability
- The algorithms for RLHF and the corresponding Python codes
- Challenges of RLHF
- Applications of RLHF
- Understanding of the working of ChatGPT and how it incorporated RLHF into its architecture
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Frequently Asked Questions
A. Reinforcement learning from human feedback involves training AI models by combining reinforcement learning techniques with human-provided feedback. Humans act as evaluators, guiding the model’s learning process by providing feedback on its actions, thereby refining its decision-making abilities.
A. Reinforcement learning from human feedback builds upon prior work in reinforcement learning and interactive machine learning. While various researchers have contributed to this field, it is challenging to attribute its invention to a single individual due to its collaborative and iterative nature.
A. Yes, reinforcement learning from human feedback can be categorized as a feedback-based machine learning algorithm. It leverages human feedback to shape the model’s behavior and optimize its performance over time.
A. Reinforcement learning plays a crucial role in AI by enabling machines to learn optimal behaviors through trial and error. It empowers AI agents to make decisions and take actions in dynamic and uncertain environments, making it applicable in areas such as robotics, game playing, autonomous systems, and more.