



{kind=link}
This article was published as a part of the Data Science Blogathon
Introduction
Hey all,
I am sure you must have played pokemon games at some point in time and must have hated the issue of creating an optimal and balanced team to gain an advantage. What if I say one can do this by having some knowledge of python, data science, and python. Pretty interesting, right?
This article is a walkthrough to perform just that using PuLp, the linear programming and optimization library.
Here is a quick summary of the gameplay, which will be helpful later on.
A Quick Refresher
(You may skip if already known :)
This section is optional and contains a summary of game mechanics in a few points:
1. Pokemon are animal-like creatures that are obtainable by battling them. Each one has its primary Type and weakness or advantage over the others. They can also undergo a genetic transformation two times called evolution. (later has mega-evolution!)
2. Evolution allows an increase in overall strengths, changes in forms, and even provides additional typings.
3. The game mechanics also allow for powerful pokemon(legendaries) caught at the end of the game and give upper advantages to the yielder.
For gameplay:
1. One starts as a lead character who can choose their first pokemon called stater pokemon out of 3.
2. Having chosen, they embark on a journey to defeat eight gym leaders, specializing in a specific type, to enter a Pokemon league tournament.
3. Once entered, they are required to defeat four powerful trainers and the champion(uses a variety of different pokemon types)
Finally, this clarifies our goal: Can we create a helpful team in fighting these 12 trainers and probably the last one?.
Dataset
For the Problem in hand, we will be using two datasets:
Pokemon dataset from Kaggle: For pokemon names and stats.
Type_chart: For type matchups and effects.
It will be great to download both datasets(pokemon.csv & Pokemon Type Chart.csv), save them in a separate folder(datasets), and follow along.
Loading the Dataset
We start by loading the CSV file using pandas and printing a few results:
import numpy as np import pandas as pd
team_df = pd.read_csv("Datasets/pokemon.csv")
team_df.head()
Output:
pokemon-dataset – Image by Author
The dataset consists of 721 pokemon, including their id, name, generation, stats, legendary and original stats breakdown. Table 1.1 shows the details:

table 1.1 – Image By Author
Note: We will use pokemon data until generation 4 and remove legendaries and mega evolved to get a fair dataset.
Changing column names
Now, for understanding purposes, let’s change the name of # to id :
team_df = team_df.rename(columns= {"#" : "id"})
team_df.head()
Output:
# -> id – Image by Author
Filtering the Pokemons
Since the dataset consists of extra pokemons, filter the dataset to only include pokemons up to required, achieved by filtering over the “id” column. However, one needs to store all the indices first; gen 4 is easy, but for gen1-3, only was is to hold the index manually:

The image shows the code which keeps the index of 110 pokemons quickly verifiable using:
# checking len len(gen1_gen3)
>> 110
By performing filtering operation on Pokedex results in desires dataset
# creating pokedex pokedex = gen4+gen1_gen3 # filtering out the dataset based on pokedex till gen 4 gen4_dex = team_df[team_df.id.isin(pokedex)] gen4_dex
Output:
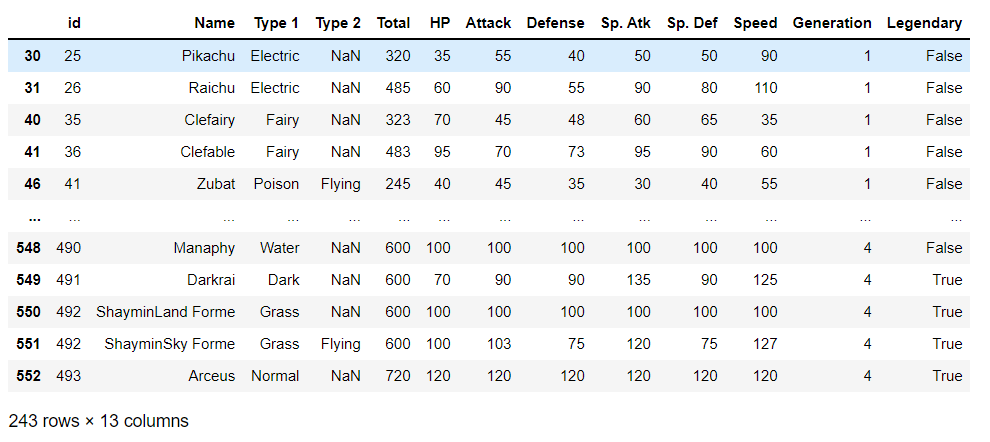
Notice how the no of rows decreased from 721 to 243; this represents the filtering was successful.
Expelling duplicate & legendaries
A careful evaluation of the above image reveals the same names for some pokemon(Shaymin). As our constraint is not to use those, we will drop them using their id’s
# removing dupilacates like id -550,551 - Shaymin forms gen4_dex= gen4_dex.drop_duplicates(subset = ['id'])
Legendaries – “represented using True/ False,” so the filtering becomes easy.
# removing Legendary pokemon for fairness - just filtering non legendaries gen4_dex = gen4_dex[gen4_dex.Legendary == False] gen4_dex
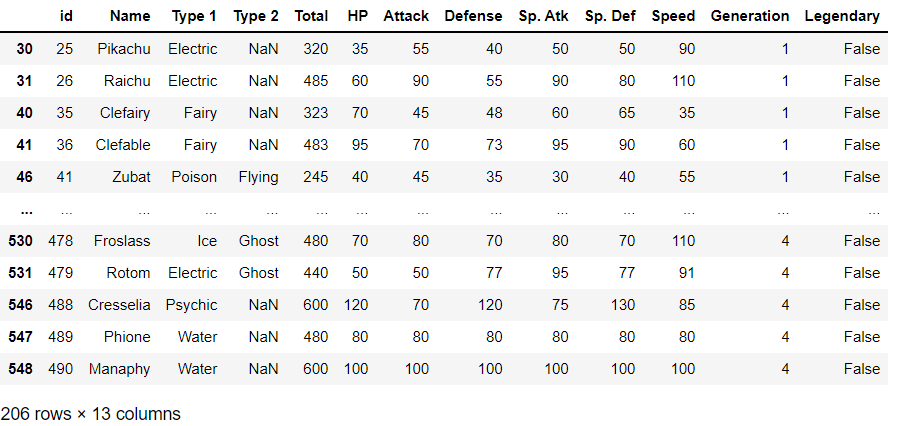
Output: The result is a dataset with all filtering performed.
Loading Type Chart
As our data is now ready for analysis, we now need to load the type chart which will help us in creating a matrix:
# loading dataset- type_chart
type_chart = pd.read_csv("Datasets/pkmn_type_chart.csv" , index_col=[0])
Here index_col =[0] is because we don’t want to include our 1st column( numbers)
Output:
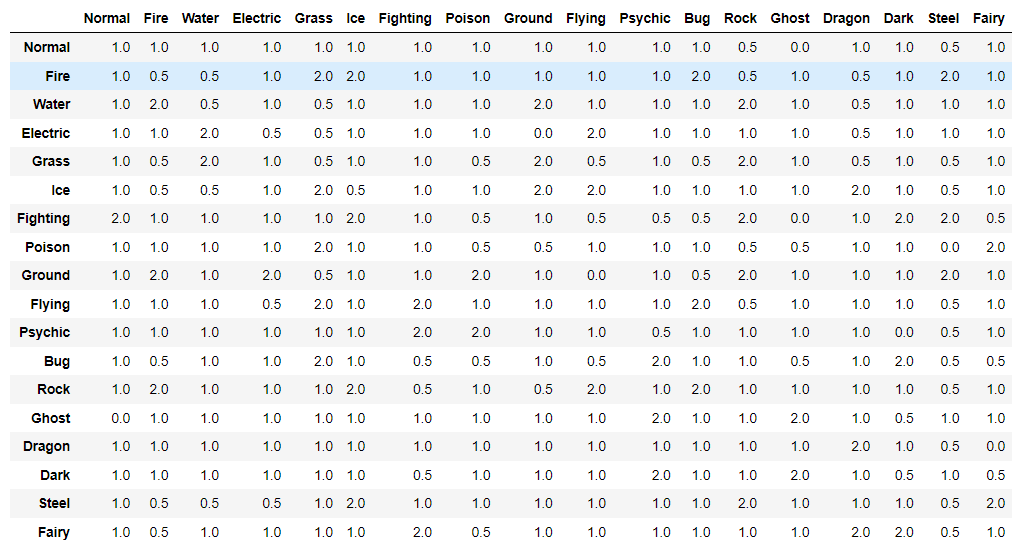
The numeric values in the dataset are just quantification of how each move affects the other. For easy understanding. I have summarized the dataset below:

Selecting Pokemon Types Based On Gym Leaders And Elite Fours
The idea of using a type chart was to track which pokemon type has an advantage over gym leaders and elite four’s, i.e. 12 types. We can achieve this by filtering our dataset over the types used by the leaders and elites.
# storing types for reference
pkmn_types = ['Rock', 'Grass', 'Fighting', 'Water', 'Ghost', 'Steel',
'Ice', 'Electric', 'Bug', 'Ground', 'Fire', 'Psychic']
# filtering
gym_elite_four = type_chart[[c for c in type_chart.columns if c in pkmn_types]]
gym_elite_four
Output:

Removal of fairy type confirms the filtering executed favourably.
Objective Function
Recall the objective – We need a set of 6 pokemon that are super effective against at least one of the gym and elite fours, with the constraints :
1. No legendaries, mythical or mega evolution [C, S] allowed (gen 4 – has no mega evolution)
2. The team has at least one starter pokemon[S] + their evolutions (optional).
With the rules defined, we can refer to the above as an LPP, and the goal is to optimize the below function:
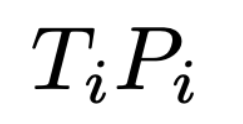
Under the imposed restrictions:
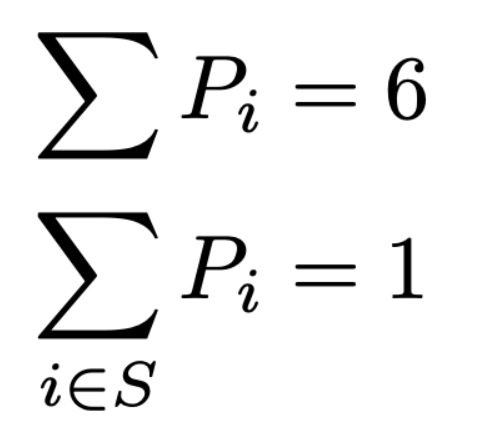
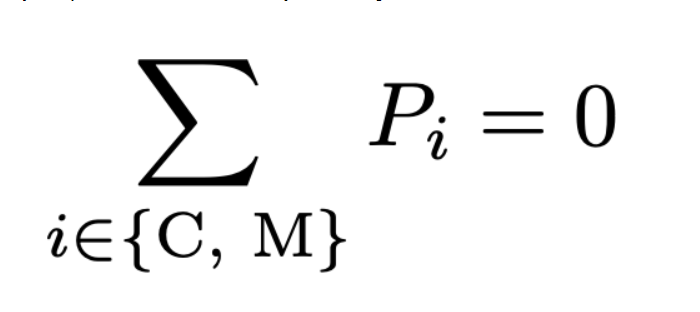
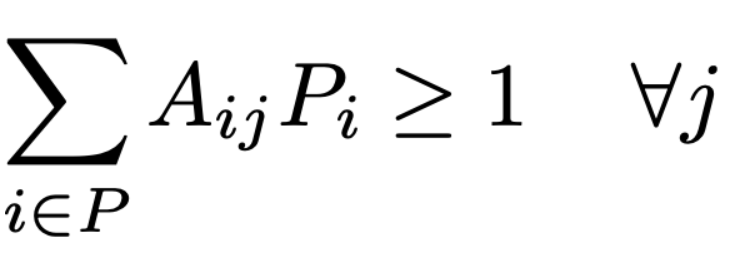
Images By Author
Where :

Creating Binary Matrix Aij
According to the equation, we must store all the variable values; achieved by iterating through all the required columns.
# changing Types 1 to Type to insure no error
#while iterating using pandas
gen4_dex = gen4_dex.rename(columns= {"Type 1" : "Type1"})
gen4_dex = gen4_dex.rename(columns= {"Type 2" : "Type2"})
# creating list
ids = [] # contains the id of each pokemon
names = [] # list containg all the pokemon names
total_stats = [] # total stats/ total column of pokemon dataset
effective_type =[] # store pokemon type which are effective agaist the opponents pokemon
# iterating through entire data to store different variables
i = 0 # counter/ iterator
for row in gen4_dex.itertuples(index=True, name='Pandas'):
ids.append(row.id)
names.append(row.Name)
# Check what types the Pokemon is strong against
effective_type.append([1 if s >= 2.0 else 0 for s in list(gym_elite_four.loc[row.Type1])])
total_stats.append(row.Total)
# Accounting for any secondary typings, and adding onto any advantages conferred
try:
effective_type[i] = list(np.add(strengths[i],
[1 if s >= 2.0 else 0
for s in list(gym_elite_four.loc[row.Type2])]))
except:
KeyError
i += 1
# Equals 1 if the Pokemon is strong against the type indicated; 0 otherwise
#--> 206 by 18 matrix # Aij
advantage = [[1 if r >= 1 else 0 for r in effective_type[i]] for i in range(206)]
# Create the set of starter Pokemon
starterNames = ['Turtwig', 'Grotle', 'Torterra',
'Chimchar', 'Monferno', 'Infernape',
'Piplup', 'Prinplup', 'Empoleon']
starter_idx = []
for pkmn in starterNames:
starter_idx.append(names.index(pkmn))
# creating mythyical indices list to later include the constraints
mythical_names = ['Cresselia', 'Manaphy'] # list of names
# using names to find the index of pokemon and adding mythical index
mythical_idx = []
for i in mythical_names:
mythical_idx.append(names.index(i))
The above code is self-explanatory and requires a bit of intermediate python knowledge. The different variable represents the equation , e.g staterName – S in eq
The Final Piece – Using the PuLp Library
Now that we have Aij(sparse matrix) & all the required values stored as a list, it is time to use PuLp library to solve our optimization problem. So let’s do that!
Understanding PuLP Library
Plup is a python library for construction solving optimization problems as us Linear Programing. It is very intuitive and user-friendly due to its syntax. Also, it has a wide variety of integration to create LP files, such as GNU Language Programming Kit (GLPK), CBC, CPLEX, etc. which makes it easy to work with and is ideal for our use case:
Usage of PuLp Library
Plup library utilizes classes and their associated functions to carry out the optimization. So let’s understand them first:
LpProblem – Base Class for Linear Problem – Problem Initialization
# start a linear problem
P = LpProblem("name",objective) # LpMaximize/LpMinimize
LpVariable – Class to Store added variables – Add Variables
# adding variable # start , end : 1,5 i.e 1<=var<=5
var = LpVariable("var_name", start, end)
IpSum – function to create a linear expression; can be used as constraint or variable later on
#expression of form var1*var2+c exp = lpSum([var1*var2+c])
#returns : [a1*x1, a2x2, …, anxn]
solve: solves the Problem:
P.solve()
For more info on the library, refer to the original documentation. I have only included those that we will be using.
With this, we can now proceed to our final code.
The Code
Install Pulp:
!pip install pulp
# import everthying from plup
from pulp import *
# define model name and objective end goal - max/min
best_team = LpProblem("optimal_team", LpMaximize)
# defining a sparce matrix for pokemon i.e mask with 0 & 1s which will be later populated
Pokemon = LpVariable.dicts("Pokemon", range(206), cat=LpBinary) # 206 pokemon to consider - Binary - O,1
# defining the objective fn to maximize - defined earlier
# TiPi - # pkmn is the iterator variable used
best_team += lpSum([total_stats[pkmn] * Pokemon[pkmn]
for pkmn in range(206)])
# adding contraint that we need only 6 pokemon on team(pi = 6)
best_team += lpSum([Pokemon[pkmn] for pkmn in range(206)]) == 6
# adding 2nd constraint that out team should have one starter pokemon(S)
best_team += lpSum([Pokemon[pkmn] for pkmn in starter_idx]) == 1
# adding contraints that we can't use mythical pokemon(C,M)
best_team += lpSum([Pokemon[pkmn] for pkmn in mythical_idx]) == 0
# adding contraint that team should have
#atleast one pokemon which has type advantage against
#one of the Gym leader/Elite Four
for i in range(12):
best_team += lpSum([advantage[pkmn][i] * Pokemon[pkmn]
for pkmn in range(206)]) >=1
# finding the soltution
best_team.solve()
>> 1
6 Names can be checked by iterating through the mask model(Pokemon):
# printing out results - > Best 6 pokemons
for i in range(206):
if Pokemon[i].value() == 1:
print(names[i])
Output:

Image By Author
As can be seen, we have all the six pokemon where infernape is the final form of chimchar (fire type starter ), and at least one is super effective against each gym and elite. For, E.g. Togekiss – Fairy Type has a super advantage over dragon types.
Additional
Now let’s look into another beneficial aspect of Linear Programing for creating pokemon teams. Notably, we will include only one stater/evolution chain (suitable for specific starter lovers), later extending it to have at least one of our desired pokemon.
A particular use case would be :
Objective1 – I am fond of grass staters, and our code returned me fire ones: (evident from the output of the last article):
so it’s beneficial to include them (no others) while keeping the team optimized.
Objective2 – Similarly, you like Pikachu but as apparent not in the returned team, and you desperately need it.
So to optimize our team, let’s start our journey.
Objective 1 – Including Only A Specific Set Of Starters
If you revise our optimization code, all we did was keep imposing restrictions on our optimization problem. We can perform the same for this objective, but the issue is, we can’t control whether to include other staters or not.
To solve this issue, we can take the help of a set difference(complement) operation as all of them can be thought of as elements of the list(universal set in black), and differencing the required will give rest for which we can apply constraints.
Here is a visual representation of the same:
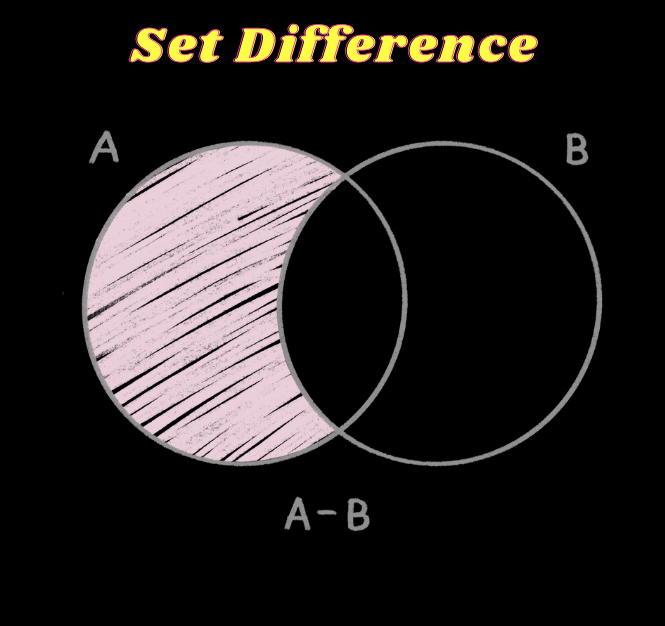
As evident for any specific set, if the set difference is applied, it returns a new group without any particular set element. Now, this allows up to control our point, as mentioned earlier.
With this, let’s now modify our code a bit:
# Storing starter index -> full evolution chain water_starters = [116, 117, 118] grass_starters = [110,111,112] fire_starters = [113,114,115] # creating a list of non stater_types using set diffrence not_water_starters = list(set(starter_idx)- set(water_starters)) not_fire_starters = list(set(starter_idx)- set(fire_starters)) not_grass_starters = list(set(starter_idx)- set(grass_starters))
The above code is equivalent to(represented using colored circles):



Printing List proves the diagrams:
# quick verify
print("Not water staters: ",not_water_starters)
print("Not fire staters: ",not_fire_starters)
print("Not grass staters: ",not_grass_starters)

Having defined our compliments, let’s add the new rules. For this, we will take our old code and impose new constraints:
“The team should not have any complements and must have at least one starter/its evolved form.”
The below code is equivalent to the same:
# Intialize problem using name and objective
best_team = LpProblem("optimal_team", LpMaximize)
# defining a sparce matrix for pokemon i.e mask with 0 & 1s which will be later populated
Pokemon = LpVariable.dicts("Pokemon", range(206), cat=LpBinary) # 206 pokemon to consider
# defining the objective fn to maximize TiPi
best_team += lpSum([total_stats[pkmn] * Pokemon[pkmn] for pkmn in range(206)])
# adding contraint that we need only 6 pokemon on team
best_team += lpSum([Pokemon[pkmn] for pkmn in range(206)]) == 6
# constraint that we cant have mythical and pseudo legendary pokemons
best_team += lpSum([Pokemon[pkmn] for pkmn in mythical_idx]) == 0
# need alteast 1 user defined stater - here water
best_team += lpSum([Pokemon[pkmn] for pkmn in water_staters]) == 1
# No other staters
best_team += lpSum([Pokemon[pkmn] for pkmn in not_water_staters]) == 0
# adding contraint that team should have atleast one pokemon which has type
# advantage against one of the Gym leader/Elite Four
for i in range(12):
best_team += lpSum([advantage[pkmn][i] * Pokemon[pkmn] for pkmn in range(206)]) >=1
# finding the soltution
best_team.solve()
>> 1
Excellent one represents the operation was successful. Let’s now print the result.
for i in range(206):
if Pokemon[i].value() == 1:
print(names[i])
Returns:
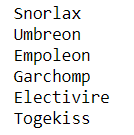
The previous code can be modified to include others but complement the same(not_fire_stater/water/grass stater).
Objective 2 – Party Must-Have Our Desired Pokemon
Let’s now move to our second use case. Here we need to include our desired pokemon on the team, but the problem is we don’t know the index of the same, and it’s cumbersome to look through the entire database to find one and store it.
Don’t worry. The solution is in the code itself. Remember, we have found the mystical index using the same procedure, for reuse lets wrap the code as fn:
def index_finder(desired_namem, name_list):
# iterate throught the name_list
idx = []
for i in desired_name:
idx.append(names.index((i)))
return idx
To use all needed is to pass the pokemon name in a list, and voila, you have the index :
>> [130]
Note: this code only generates an index for gen four pokemon, for please change the names list(more specifically gen1_gen3).
Anyways let’s add our index to include at least just that in our above code. One-liner to perform this is :
# must have desired one best_team += lpSum([Pokemon[pkmn] for pkmn in desired_idx]) == 1
After executing, results are evident and is as desired:
for i in range(206):
if Pokemon[i].value() == 1:
print(names[i])
Output:

Also, note nothing is stopping you from adding multiple pokemon to the list and get at least one:
Returns:

References
Learn Pulp: Toward Data Science Blog
Contact: LinkedIn | Twitter | Github
Code Files: Github
Inspiration: Code Basics, Jamshaid Shahir
Hey All✋,
My name is Purnendu Shukla a.k.a Harsh. I am a passionate individual who likes exploring & learning new technologies, creating real-life projects, and returning to the community as blogs.
My Blogs range from various topics, including Data Science, Machine Learning, Deep Learning, Optimization Problems, Excel and Python Guides, MLOps, Cloud Technologies, Crypto Mining, Quantum Computing.