



{kind=link}
This article was published as a part of the Data Science Blogathon
Introduction
Model overfitting is a serious problem and can cause the model to produce misleading information. One of the techniques to overcome overfitting is Regularization. Regularization, in general, penalizes the coefficients that cause the overfitting of the model. There are two norms in regularization that can be used as per the scenarios.
In this article, we will learn about Regularization, the two norms of Regularization, and the Regression techniques based on these Regularization techniques.

Image by Victor Freitas from Pexels
Table of Contents
- Overfitting and Regularization
- L1 Regularization or LASSO
- L2 Regularization or Ridge
- LASSO Regression
- Ridge Regression
- ElasticNet Regression
- Conclusions
Overfitting and Regularization
Overfitting of the model occurs when the model learns just ‘too-well’ on the train data. This would sound like an advantage but it is not. When a model is overtrained on training data, it performs worst on the test data or any new data provided. Technically, the model learns the details as well as the noise of the train data. This would hinder the performance of any new data provided to the model as the learned details and noise cannot be applied to the new data. This is the case when we say the performance of the model is not adequate. There are several ways of avoiding the overfitting of the model such as K-fold cross-validation, resampling, reducing the number of features, etc. One of the ways is to apply Regularization to the model. Regularization is a better technique than Reducing the number of features to overcome the overfitting problem as in Regularization we do not discard the features of the model.
Regularization is a technique that penalizes the coefficient. In an overfit model, the coefficients are generally inflated. Thus, Regularization adds penalties to the parameters and avoids them weigh heavily. The coefficients are added to the cost function of the linear equation. Thus, if the coefficient inflates, the cost function will increase. And Linear regression model will try to optimize the coefficient in order to minimize the cost function.
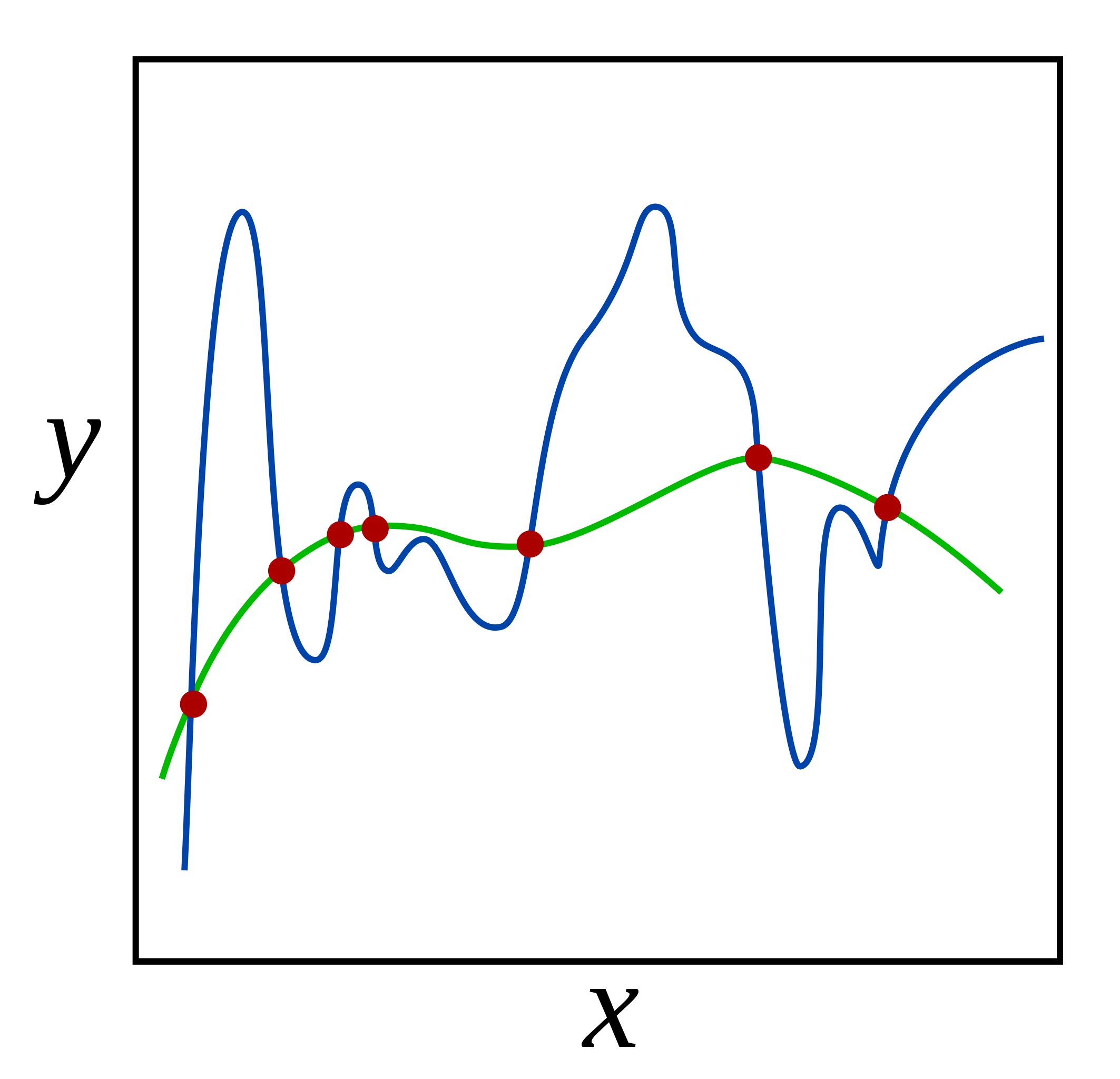
Image by Nicoguaro
Practically, you can check if the regression model is overfitting or not by RMSE. A good model has a similar RMSE for the train and test sets. If the difference is too large, we can say the model is overfitting to the training set. There are two kinds of techniques for adding penalities to the cost function, L1 Norm or LASSO term and L2 Norm or Ridge Term.
L1 Regularization or LASSO
L1 Regularization technique is also known as LASSO or Least Absolute Shrinkage and Selection Operator. In this, the penalty term added to the cost function is the summation of absolute values of the coefficients. Since the absolute value of the coefficients is used, it can reduce the coefficient to 0 and such features may completely get discarded in LASSO. Thus, we can say, LASSO helps in Regularization as well as Feature Selection.
Following is the equation of Cost function with L1 penalty term:
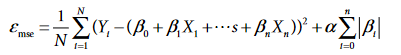
Cost Function after adding L1 Penalty (Source – Personal Computer)
Here, alpha is the multiplier term.
L2 Regularization or Ridge
L2 Regularization technique is also known as Ridge. In this, the penalty term added to the cost function is the summation of the squared value of coefficients. Unlike the LASSO term, the Ridge term uses squared values of the coefficient and can reduce the coefficient value near to 0 but not exactly 0. Ridge distributes the coefficient value across all the features.
Following is the equation of Cost function with L2 penalty term:
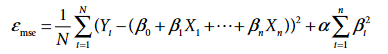
Cost Function after adding L2 Penalty (Source – Personal Computer)
Here, alpha is the multiplier term.
LASSO Regression
LASSO Regression is a linear model built by applying the L1 or LASSO penalty term. Let’s see how to build a LASSO regression model in Python.
Importing the Libraries
import numpy as np import pandas as pd from sklearn import metrics from sklearn.linear_model import Lasso
Importing the Dataset
df_train = pd.read_csv('train.csv')
df_test = pd.read_csv('test.csv')
The dataset has been taken from Kaggle.
Drop Duplicates if Any
df_train = df_train.dropna() df_test = df_test.dropna()
Specifying x_train, x_test, y_train, y_test variables for Regression
Building LASSO Regression Model
lasso = Lasso()
Fitting the Model on Train Set
lasso.fit(x_train, y_train)
Calculating Train RMSE for Lasso Regression
print("Lasso Train RMSE:", np.round(np.sqrt(metrics.mean_quared_error(y_train, lasso.predict(x_train))), 5))
Calculating Test RMSE for Lasso Regression
print("Lasso Test RMSE:", np.round(np.sqrt(metrics.mean_quared_error(y_test, lasso.predict(x_test))), 5))
Putting it all together
import numpy as np
import pandas as pd
from sklearn import metrics
from sklearn.linear_model import Lasso
df_train = pd.read_csv('train.csv')
df_test = pd.read_csv('test.csv')
df_train = df_train.dropna()
df_test = df_test.dropna()
x_train = df_train['x']
x_train = x_train.values.reshape(-1,1)
y_train = df_train['y']
y_train = y_train.values.reshape(-1,1)
x_test = df_test['x']
x_test = x_test.values.reshape(-1,1)
y_test = df_test['y']
y_test = y_test.values.reshape(-1,1)
lasso = Lasso()
lasso.fit(x_train, y_train)
print("Lasso Train RMSE:", np.round(np.sqrt(metrics.mean_quared_error(y_train, lasso.predict(x_train))), 5))
print("Lasso Test RMSE:", np.round(np.sqrt(metrics.mean_quared_error(y_test, lasso.predict(x_test))), 5))
On executing this code, we get:

Source – Personal Computer
We can tune the hyperparameters of the LASSO model to find the appropriate alpha value using LassoCV or GridSearchCV.
Ridge Regression
Ridge Regression is a linear model built by applying the L2 or Ridge penalty term. Let’s see how to build a Ridge regression model in Python.
Importing the Libraries
import numpy as np import pandas as pd from sklearn import metrics from sklearn.linear_model import Ridge
Importing the Dataset
df_train = pd.read_csv('train.csv')
df_test = pd.read_csv('test.csv')
The dataset has been taken from Kaggle.
Drop Duplicates if Any
df_train = df_train.dropna() df_test = df_test.dropna()
Specifying x_train, x_test, y_train, y_test variables for Regression
x_train = df_train['x'] x_train = x_train.values.reshape(-1,1) y_train = df_train['y'] y_train = y_train.values.reshape(-1,1) x_test = df_test['x'] x_test = x_test.values.reshape(-1,1) y_test = df_test['y'] y_test = y_test.values.reshape(-1,1)
Building Ridge Regression Model
ridge = Ridge()
Fitting the Model on Train Set
ridge.fit(x_train, y_train)
Calculating Train RMSE for Ridge Regression
print("Ridge Train RMSE:", np.round(np.sqrt(metrics.mean_quared_error(y_train, ridge.predict(x_train))), 5))
Calculating Test RMSE for Ridge Regression
print("Ridge Test RMSE:", np.round(np.sqrt(metrics.mean_quared_error(y_test, ridge.predict(x_test))), 5))
Putting it all together
import numpy as np
import pandas as pd
from sklearn import metrics
from sklearn.linear_model import Ridge
df_train = pd.read_csv('train.csv')
df_test = pd.read_csv('test.csv')
df_train = df_train.dropna()
df_test = df_test.dropna()
x_train = df_train['x']
x_train = x_train.values.reshape(-1,1)
y_train = df_train['y']
y_train = y_train.values.reshape(-1,1)
x_test = df_test['x']
x_test = x_test.values.reshape(-1,1)
y_test = df_test['y']
y_test = y_test.values.reshape(-1,1)
ridge = Ridge()
ridge.fit(x_train, y_train)
print("Ridge Train RMSE:", np.round(np.sqrt(metrics.mean_quared_error(y_train, ridge.predict(x_train))), 5))
print("Ridge Test RMSE:", np.round(np.sqrt(metrics.mean_quared_error(y_test, ridge.predict(x_test))), 5))
On executing this code, we get:

Source – Personal Computer
We can tune the hyperparameters of the Ridge model to find the appropriate alpha value using RidgeCV or GridSearchCV.
ElasticNet Regression
ElasticNet Regression is a linear model built by applying both L1 and L2 penalty terms. Let’s see how to build an ElasticNet regression model in Python.
Importing the Libraries
import numpy as np import pandas as pd from sklearn import metrics from sklearn.linear_model import ElasticNet
Importing the Dataset
df_train = pd.read_csv('train.csv')
df_test = pd.read_csv('test.csv')
The dataset has been taken from Kaggle.
Drop Duplicates if Any
df_train = df_train.dropna() df_test = df_test.dropna()
Specifying x_train, x_test, y_train, y_test variables for Regression
x_train = df_train['x'] x_train = x_train.values.reshape(-1,1) y_train = df_train['y'] y_train = y_train.values.reshape(-1,1) x_test = df_test['x'] x_test = x_test.values.reshape(-1,1) y_test = df_test['y'] y_test = y_test.values.reshape(-1,1)
Building ElasticNet Regression Model
enet = ElasticNet()
Fitting the Model on Train Set
enet.fit(x_train, y_train)
Calculating Train RMSE for ElasticNet Regression
print("ElasticNet Train RMSE:", np.round(np.sqrt(metrics.mean_quared_error(y_train, enet.predict(x_train))), 5))
Calculating Test RMSE for ElasticNet Regression
print("ElasticNet Test RMSE:", np.round(np.sqrt(metrics.mean_quared_error(y_test, enet.predict(x_test))), 5))
Putting it all together
import numpy as np
import pandas as pd
from sklearn import metrics
from sklearn.linear_model import ElasticNet
df_train = pd.read_csv('train.csv')
df_test = pd.read_csv('test.csv')
df_train = df_train.dropna()
df_test = df_test.dropna()
x_train = df_train['x']
x_train = x_train.values.reshape(-1,1)
y_train = df_train['y']
y_train = y_train.values.reshape(-1,1)
x_test = df_test['x']
x_test = x_test.values.reshape(-1,1)
y_test = df_test['y']
y_test = y_test.values.reshape(-1,1)
enet = ElasticNet()
enet.fit(x_train, y_train)
print("ElasticNet Train RMSE:", np.round(np.sqrt(metrics.mean_quared_error(y_train, enet.predict(x_train))), 5))
print("ElasticNet Test RMSE:", np.round(np.sqrt(metrics.mean_quared_error(y_test, enet.predict(x_test))), 5))
On executing this code, we get:

Source – Personal Computer
We can tune the hyperparameters of the Ridge model to find the appropriate alpha value using ElasticNetCV or GridSearchCV.
Conclusions
In this article, we learned about Overfitting in linear models and Regularization to avoid this problem. We learned about L1 and L2 penalty terms that get added into the cost function. We looked at three regression algorithms based on L1 and L2 Regularization techniques. We can set specify several hyperparameters in each of these algorithms. To find the optimal hyperparameters, we can use GridSearchCV or relevant Hyperparameter Tuning algorithms of that respective regression model. One can try comparing the performance of these algorithms on a dataset to check which algorithm performed better using a performance metric such as Root Mean Square Error or RMSE.
About the Author
Connect with me on LinkedIn Here.
Check out my other Articles Here and on Medium
You can provide your valuable feedback to me on LinkedIn.
Thanks for giving your time!
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.
IT Engineering Graduate currently pursuing Post Graduate Diploma in Data Science.