



{kind=link}
An Introduction to Decision Tree
In this tutorial, we will explore one of the most rampantly used and fundamental machine learning models, decision tree (DT). A decision tree is a very powerful model which can help us to classify labeled data and make predictions. It also enlightens us with lots of information about the data and most importantly, it’s effortlessly easy to interpret.
If you are a software engineer, you would probably know ”If-else” conditions, and we all love it because it’s very simple to understand, imagine, and code. A decision tree can be thought of as nothing but a “nested if-else classifier.”
A decision tree is one of the classifiers we have in the world of machine learning, which closely resembles human reasoning. It is also one of the models we have, which comes under the category of supervised machine learning. In supervised machine learning, we are always given the input data (also referred to as features or independent features) and class labels(also referred to as target feature or dependent feature).
Supervised learning is the machine learning task of learning a function that maps an input to an output based on example input-output pairs. It infers a function from labeled training data consisting of a set of training examples. In supervised learning, each example is a pair consisting of an input object (typically a vector) and the desired output value.
Let’s try to understand this with a simple example, suppose we have a data set of 50 fruits, out of which a few are lemons and a few are apples, and we are given fruit color and fruit size as the input feature(so these are our 2 independent features).

The decision tree for this problem might look like this:
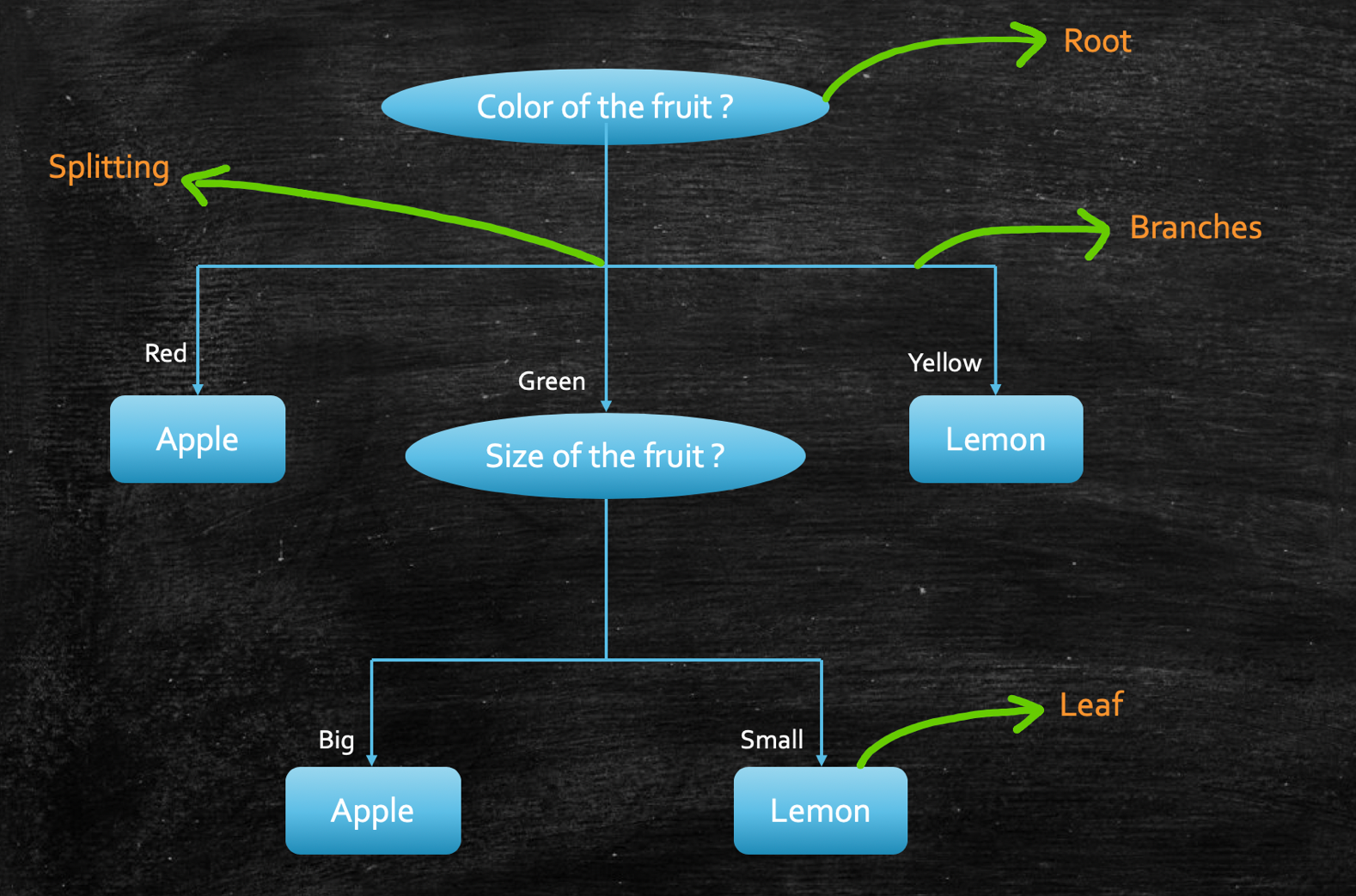
But the question is, given a dataset, how can we build a tree like this? To understand this, we need to look into the ”math” behind this, which we will see in the next section. But before that, let’s try to learn some key terminologies we must be aware of to work with a decision tree:
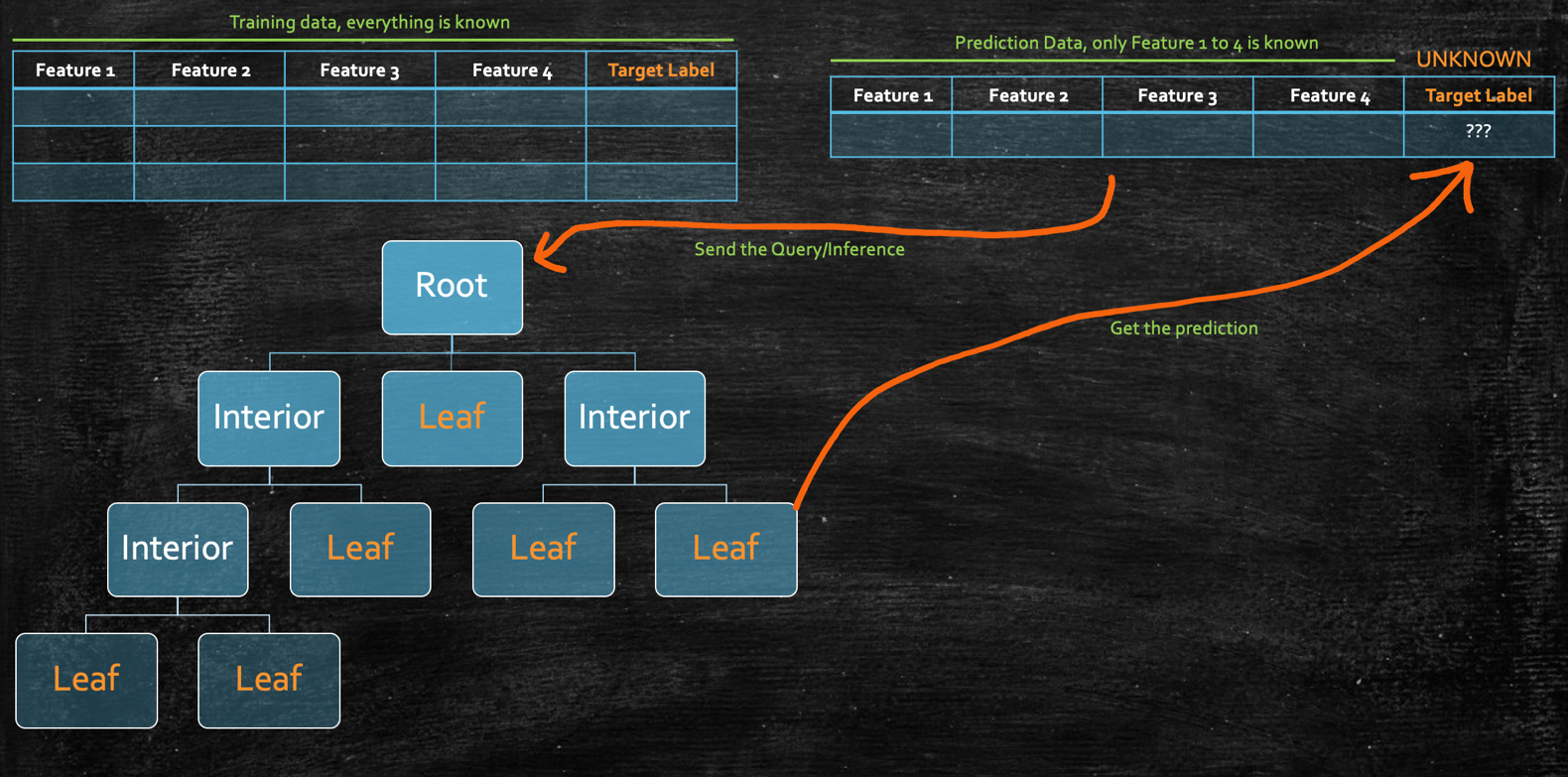
- NODE: Each time we ask a question or make a decision stump, we represent the same as a NODE.
- ROOT: The topmost node of the tree which we start questioning with.
- INTERIOR: Any node, except the ROOT node, where we again ask a question.
- LEAF: When we reach a point where we don’t ask a question, but instead make a decision, we call it as LEAF node.
So here is the general decision tree structure example:

Decision trees are “supervised” learning algorithms, which means, we need to have a labeled dataset and it can be used for both classification and regression tasks, which means we can have it for categorical data or continuous data.
Training flow of a decision tree:
- Prepare the labeled data set, with independent feature{1, 2, 3, …, n} and dependent feature(target or class label).
- Try to pick the best feature as the `root` node and thereafter, use intelligent strategies to split the nodes into multiple branches.
- Grow the tree until we get a `stopping` criteria, i.e. the leaf node which would be the actual prediction when we make any query or ask for prediction.
- Pass through the prediction data query through the tree until we arrive at some `leaf node`
- Once we get the leaf node, we have the prediction!
The math behind a decision tree
Now that we know what a decision tree looks like, the next step to think about is (and it’s the most important task to accomplish), how can we go from training data to a decision tree? And to understand this, we need to go over a bunch of very important concepts.
Entropy
Entropy is a very interesting concept in the field of Information Theory. It is the notion of the “impurity” of the data. But hold on, what is this new term “impurity” of the data?
Let’s take an example, we have this node:

We can say that, this node is “pure” because there is only one class, no ambiguity in the class label(i.e. it’s all APPLE), Now, let’s say this node:

We can say, that it’s a little “less pure” w.r.t to the previous node, as there is some small amount of ambiguity that exists in the class label (as few LEMONs are present, along with APPLE). And finally, let’s see this node:

This is very much an “impure” node, as we have mixed classes (red APPLE, green APPLE, and yellow LEMON).
Now, let’s go back to the definition of “Entropy.” It’s the notion of impurity of a node, in other words, the more the impurity the more the entropy, and vice versa.
Let’s say we have Random Variable, X, where x can be x1, x2, x3, x4,… xn.
Then, mathematically, Entropy can be defined as (also known as Shannon’s entropy) this:

where:
k = ranges from 1 through n
H(x) = entropy of x
P(k) = Probability of random variable X when (X = k)
Now, let’s take an example to understand it little better:
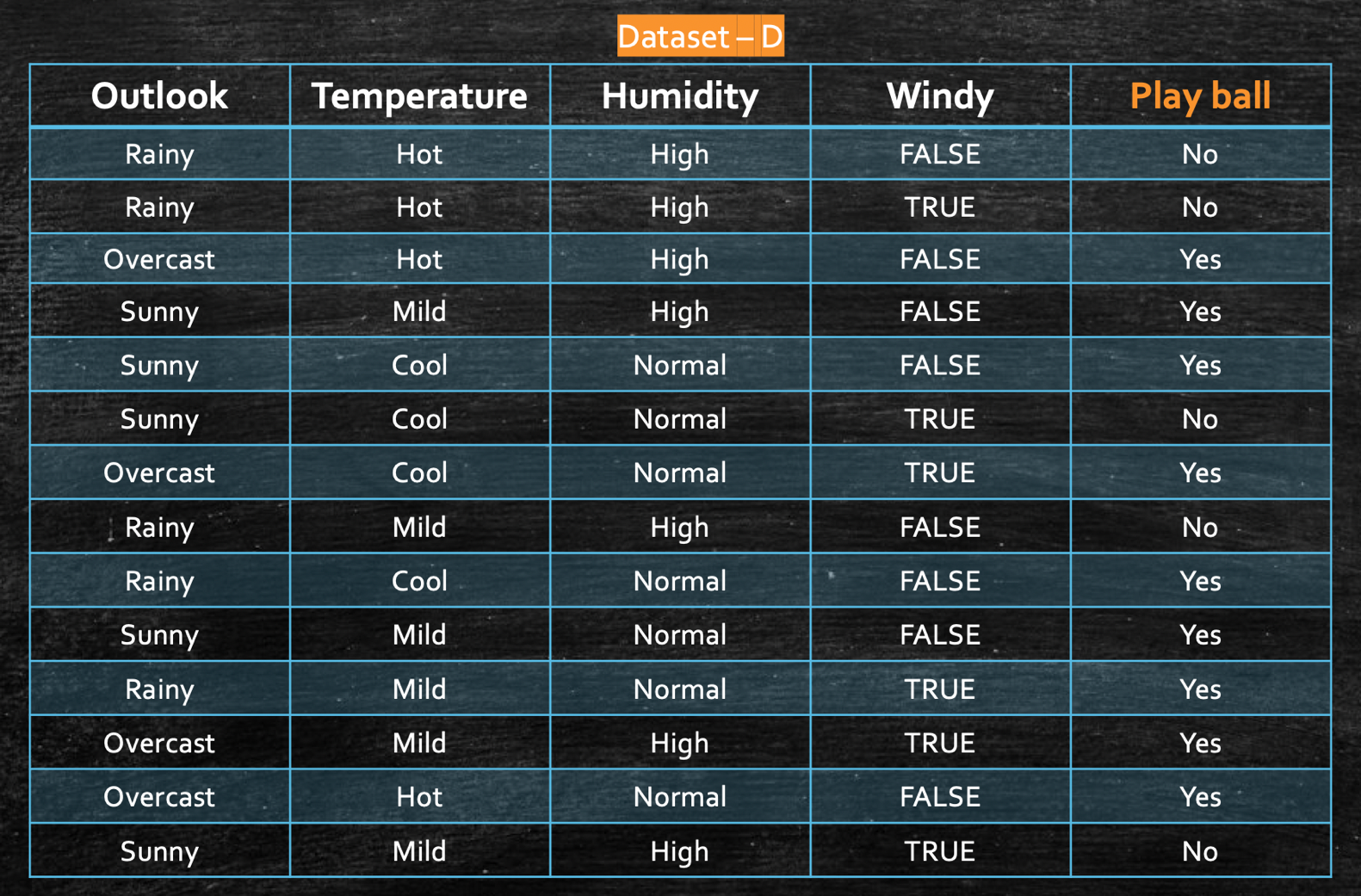
In this dataset(D), Play Ball is the `target` class, and the random variable, X. And it can take only two values, “Yes” or “No”. So,
P(k=Yes) => 9/14 = 0.64
P(k=No) => 5/14 = 0.36
Therefore, the Entropy of “Play Ball” on the dataset(D), would be:

If we think intuitively, what this essentially means is:
– `Higher` the Entropy, `more impure` the dataset is.
– `Lower` the Entropy, `more pure` the dataset is.
Information Gain(IG)
Now that we have an idea of what Entropy is, the next important concept to look into is Information Gain (IG). Let’s continue with the same example as above, where we have the Entropy, H(“Play Ball”) or in other words, Entropy of the target label, “Play Ball” is 0.94. Now, let’s say we split the dataset with the “Outlook” feature set, then our dataset would look like this:

Now, we get 3 small sub-datasets (D1, D2, and D3), based on the different values we have for the feature “Outlook”(i.e. Rainy, Overcast and Sunny). So, if now compute the Entropy of each of this small sub-dataset on the same target class “Play ball,” it would be:
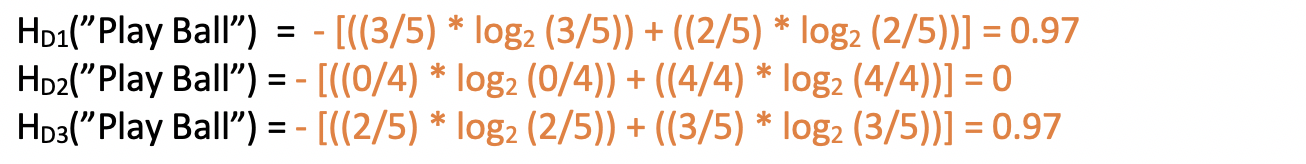
Now, the Weighted Entropy after breaking the dataset to D1, D2, and D3 would be:
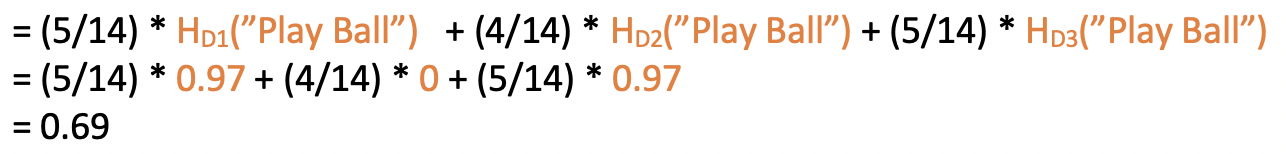
So, the Information Gain of the dataset D, when we break it based on feature, Outlook, would be:
Information Gain(Outlook) = Entropy(D) − Weighted Entropy after breaking the dataset

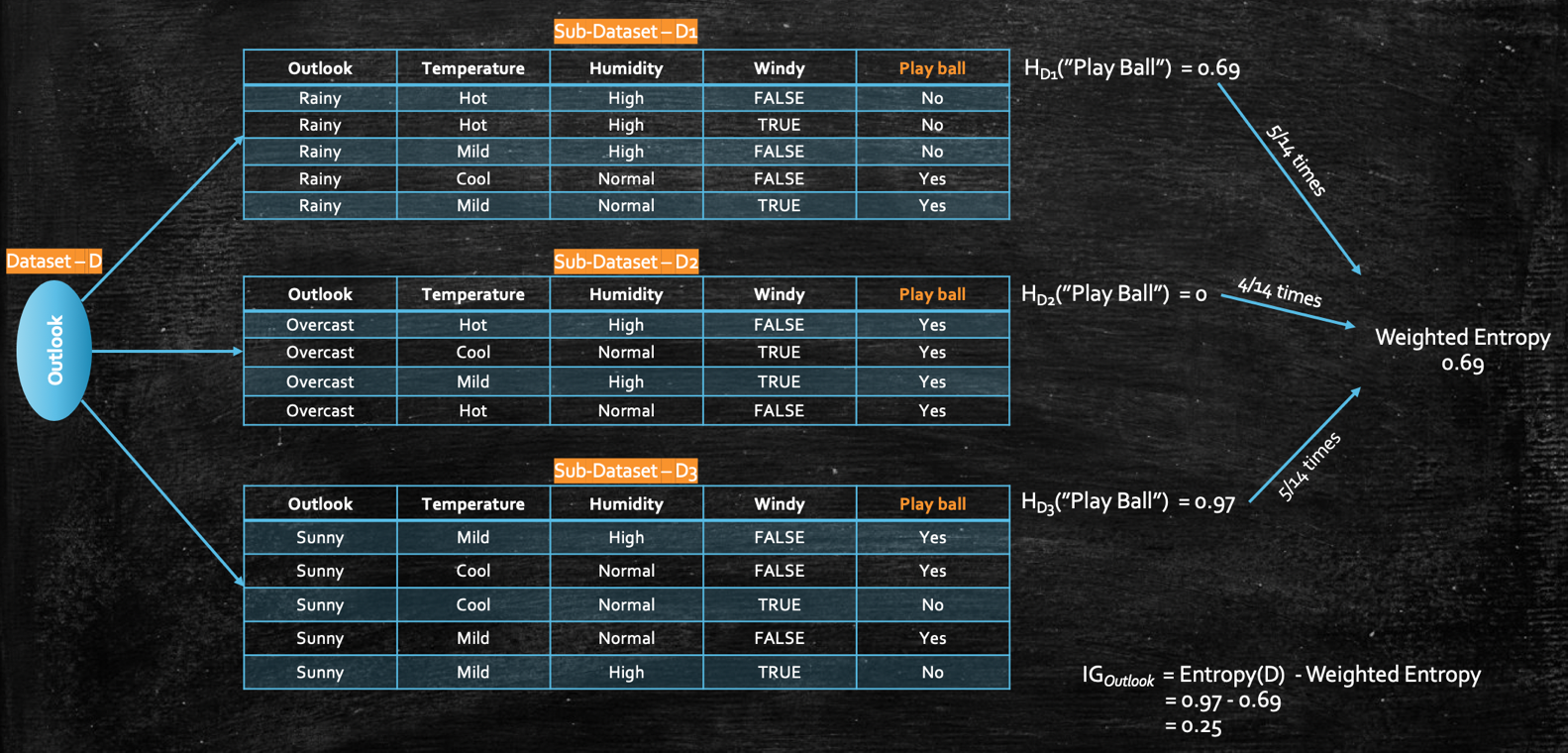
Similarly, we can find the IG based on other features as well (for `Temperature`, `Humidity` and `Windy`)

Now, if we have the information gain of all these 4 features, and it’s very clear that the information gain of the feature “Outlook” is the largest, which indirectly says that this feature (“Outlook”) gives us the maximum amount of information about the target class(“Play ball”).
Hence, a decision tree would use this feature as the ROOT node of the tree. And once the data is split, we need to further check each of the small subtree and perform the same activity and decide the next feature which has the highest IG, so that we can split the dataset further to get to a leaf node.
How to Build a Decision Tree
With the understanding of what is `Entropy` and `IG`, we can build a tree, and here is the algorithmic steps:
- First, the entropy of the total dataset is calculated for the target label/class.
- The dataset is then split into different features.
- The entropy for each branch is calculated. Then it is added proportionally, to get total weighted entropy for the split.
- The resulting entropy is subtracted from the entropy before the split.
- The result is the Information Gain.
- The feature that yields the largest IG is chosen for the decision node.
- Repeat step #2 to #6, for each subset of the data(for each internal node) until:
- All the dependent features are exhausted.
- The stopping criteria are met.
A few of the stopping criteria used are:
- No. of levels of the decision tree from the root node(or in other words, depth of the tree)
- Minimum no. of observations in the parent/child node(e.g. 10% of the training data)
- Minimum reduction of impurity index
The algorithm behind a decision tree
So far, we have discussed Entropy as one of the ways to find the impurity of a node, but there are other techniques available to split the data, like `Gini Impurity`, `Chi-Square`, `Variance`, `etc.`. However, we have different algorithms to implement a Decision Tree model, and each uses different techniques to identify the impurity of a node, and hence the split. For example:
- ID3(Iterative Dichotomiser 3) algorithm – uses Entropy
- CART algorithm – uses Gini Impurity Index
- C4.5 – uses Gain Ratio
Thankfully, we do not have to do all this(like calculating Entropy, IG, implement ID3, etc.), we have lots of libraries/packages available in Python which we can use to solve a problem with a decision tree.
Problem
Here is the dataset. Does the data set contain wifi signal strength observed from 7 wifi devices on a smartphone collected in indoor space(4 different rooms)? The task is to predict the location(which room) from wifi signal strength. For more details check here.
Amazon SageMaker Notebook
Before we get into code, we would spin an Amazon SageMaker Notebook, it’s a fully managed ML compute instance running the Jupyter Notebook App. It manages creating the instance and related resources for us, we are going to use Amazon SageMaker Notebook, rather than using local Jupyter-Notebook on our laptop(and we will later see why?)
We will use Jupyter notebooks within our notebook instance to prepare and process data, write code to train models, deploy models to Amazon SageMaker hosting, and test or validate your models. For this tutorial, since we are going to have a small dataset, we will not be deploying the model, but going forward for the upcoming tutorials we are going to solve various complex problems wherein we would deploy the model as well.
- Login to `AWS Console`
- Search of `SageMaker` under Find Services search bar

- Click on the side menu, `Notebook` -> `Notebook Instances` and then click on `Create notebook Instance`

- Specify the instance type, and click `Create notebook instance`.

- Wait for the instance till the Status changes from `Pending` to `InService`

- Once it’s `InService`, click on `Open Jupyter`

So, now our `Jupyter Notebook` is up and running. One of the best part of SageMaker Notebook is it being completely managed and all the different framework comes out of the box, for example, if we click on New and try to create a new notebook, we will see list of different kernels available, we don’t have to worry about installing, maintaining the updates, etc.
OK, we are all set now, let’s go back the problem statement we have in hand and start coding.

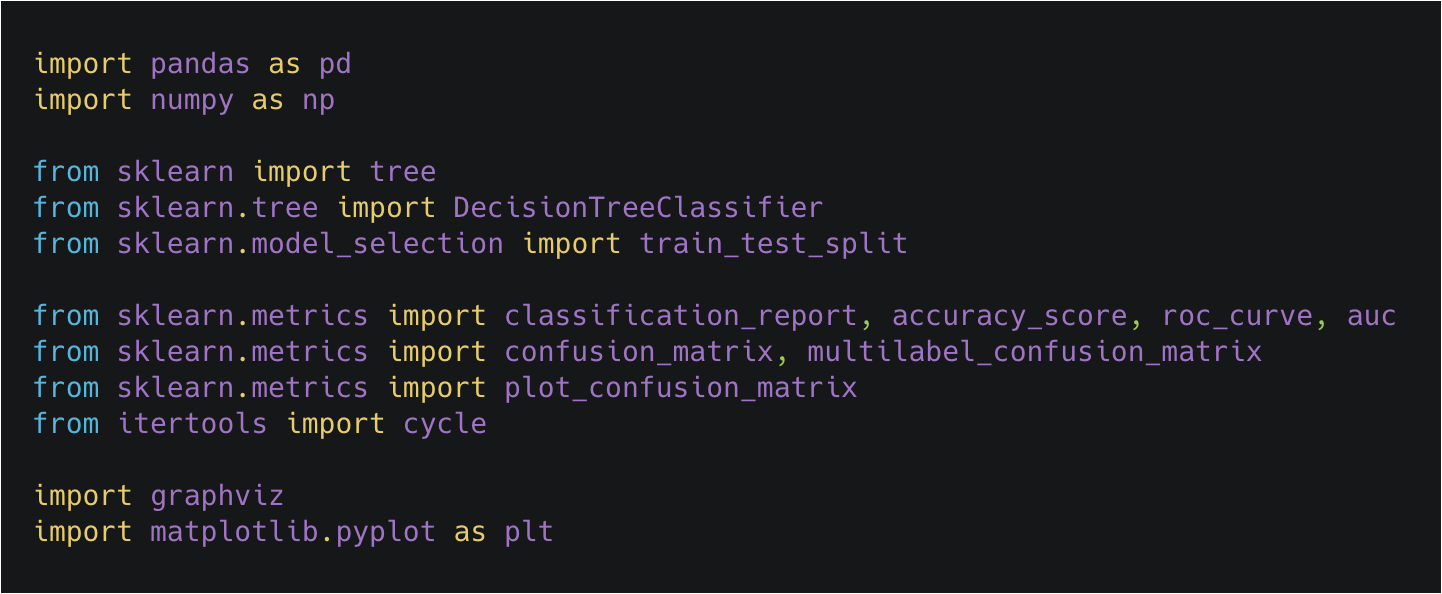
Loading the necessary modules
Let’s load the modules we will need to work with this problem, we will be using scikit-learn machine learning library
Decision Tree Classifier
Let’s create a small function that will return a decision tree classifier
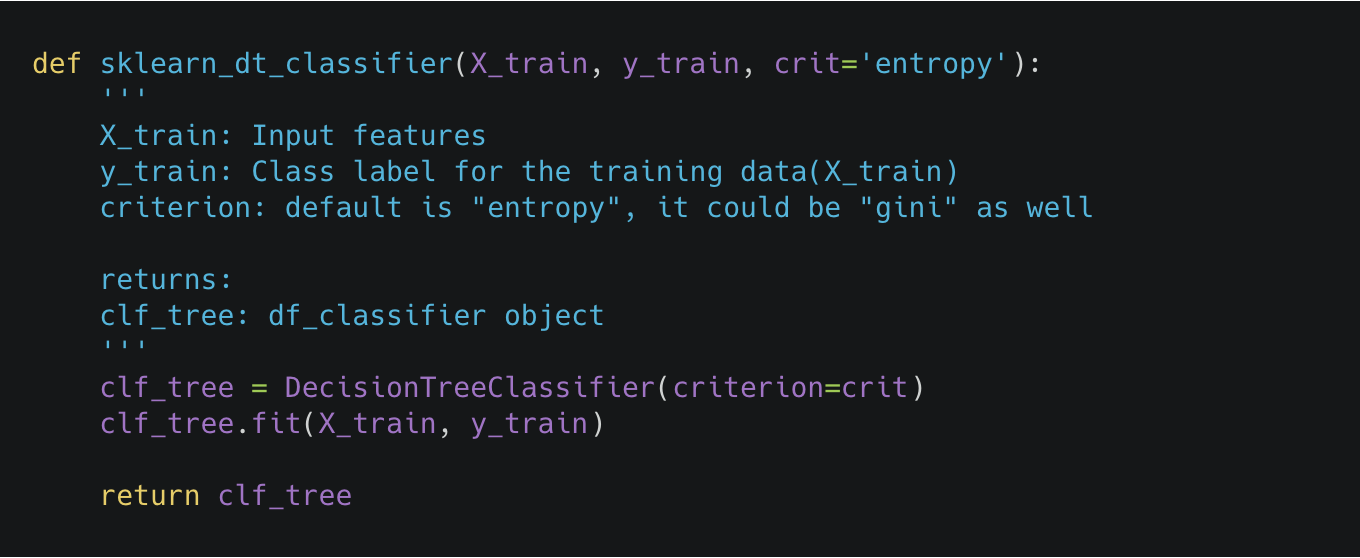
Here, the function takes 2 arguments,
- X_train: Input or Independent Features and
- y_train: Class or Target Label
Then we use DecisionTreeClassifier classifier from the scikit-learn library, this function takes many arguments(which are also commonly known as hyperparameters), and here we are using one of them, criterion: The function to measure the quality of a split. Supported criteria are “gini” for the gini impurity and “entropy” for the information gain.
And this function returns “clf_tree”: the decision tree classifier which we will be using for inference(prediction) later.
Load the dataset
Let’s load the dataset (`wifi_localization.txt`)

Here, after loading the data in a `df`: Pandas DataFrame, we insert the column names and separates the Input Features(`X` DataFrame) and Target Label(`Y` DataFrame)
Splitting the dataset
Now, we will split the whole dataset into training and testing(we will use 20% of the total data points for testing),

Now we can see the first 5 data points:
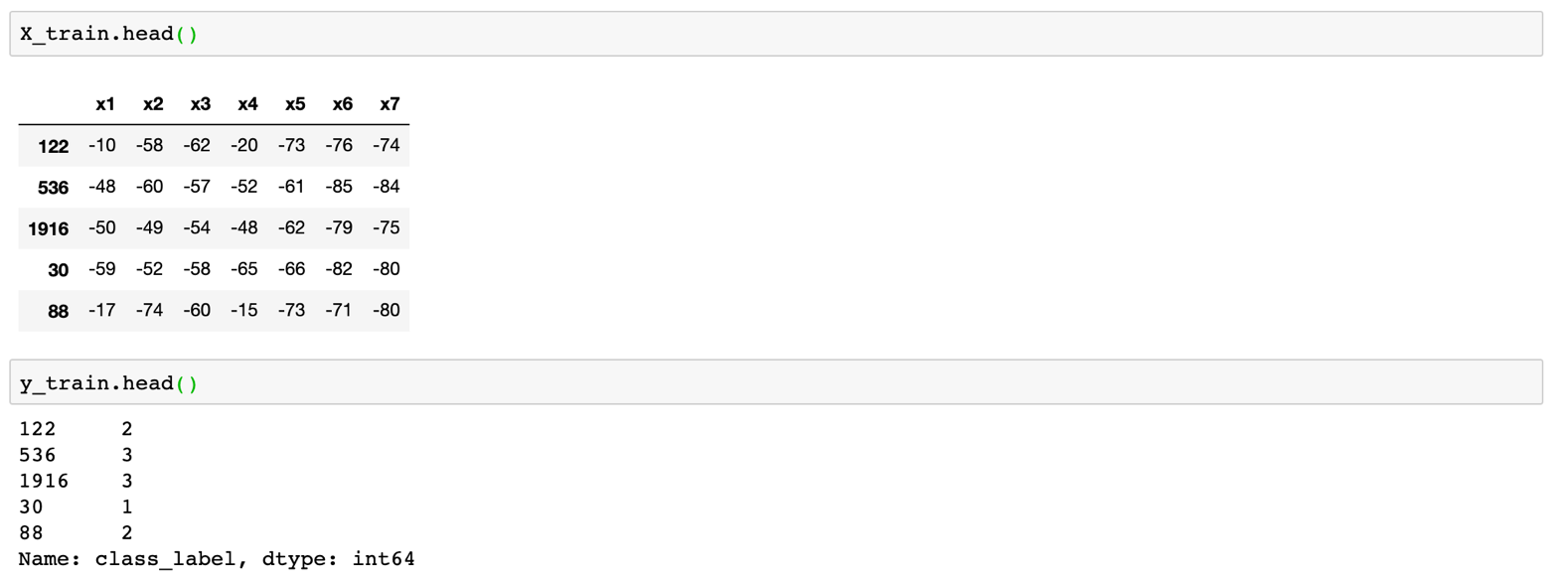
Decision Tree Classifier


We can see that this classifier can be tuned with many parameters(often times, it’s called hyper-parameters. For more details on what each hyperparameters mean, we can refer to the documentation.
We have used one of the hyper-parameter here `criterion`, as entropy, which means that the classifier will use entropy to calculate the IG, which would be ultimately used to split the data in the background.
Predicting the result on the test data
Finally, we can use our Decision Tree Classifier object `clf_tree` to make some predictions on my testing data(`X_test`)

Evaluating the Performance
Now, that we got the prediction(`y_pred`), we can validate it with the actual labels (`y_test`) of this test data.


We did a lot in these last few lines of code, and we saw some new terms, `accuracy`, `precision`, `recall`, `f1-score`, and `confusion matrix`
These all were Model Performance Metrics, we will have one tutorial dedicated to different Model Performance Metrics as we have many and not only these which are mentioned here, but for now, we can think of these as:
- Accuracy: It simply measures, how accurately the model predicted, e.g. if we have 10 test data points, and out of 10, only 8 data points are predicted correctly by the classifier, then the accuracy would be 80%, which also means accuracy can lie between 0 to 1
- Precision: The precision is the ratio `tp / (tp + fp)` where tp is the number of true positives and fp the number of false positives. The precision is intuitively the ability of the classifier not to label as positive a sample that is negative.
- Recall: The recall is the ratio `tp / (tp + fn)` where tp is the number of true positives and fn the number of false negatives. The recall is intuitively the ability of the classifier to find all the positive samples.
- F1-score: The F1 score can be interpreted as a weighted average of the precision and recall, where an F1 score reaches its best value at 1 and worst score at 0. The relative contribution of precision and recall to the F1 score are equal. Mathematically it is defined by: `2 * (precision * recall) / (precision + recall)`
Visualize A Decision Tree
Finally, we will try to visualize how our Decision Tree looks like, and we can do so, using a library graphviz.
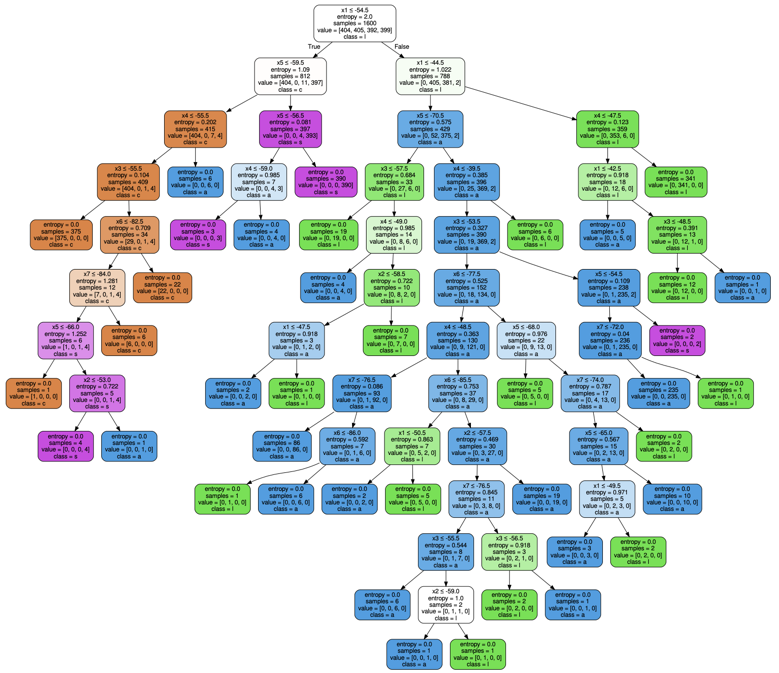
This is finally how the tree from the above classifier would look like. You can also download it from here.
You may like to get the code/jupyter-notebook from git repo.
References
You may like to visit the below-mentioned course, books, and source links which were referred to for the tutorial:
Course:
Books:
Amazon SageMaker:
By Suman Debnath, Principal Developer Advocate, Amazon Web Services