



{kind=link}
This article was published as a part of the Data Science Blogathon.
Introduction
It happens quite often that we do not have all the features/input variables in one file, but spread across multiple files. Not just that, it might even need external information to make appropriate joins to prepare the final data in the right format for model training. In this article, we will see how data preparation and feature engineering (specifically target variable engineering) are the most time-consuming step of modeling pipeline.
Let’s get started and see what is the objective?
We will first do the necessary imports.
We have 3 datasets namely, station data, trip data and weather data.
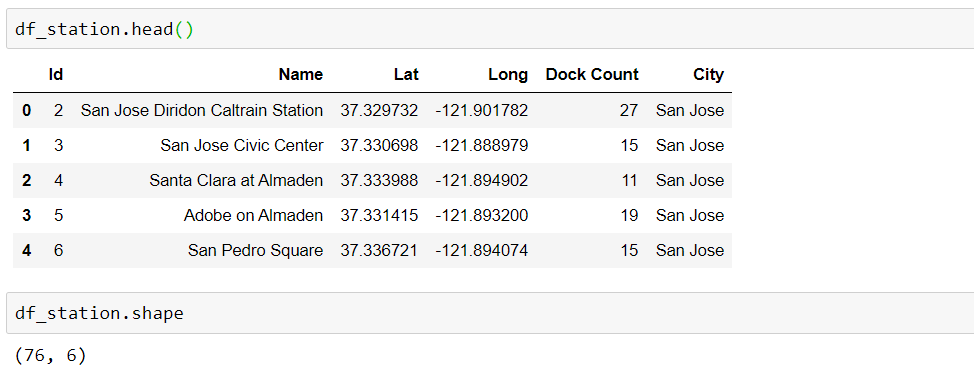
Station Data:
Let’s see how station data looks like:
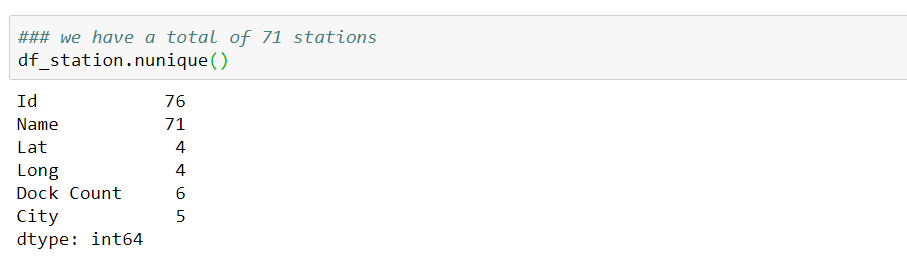
We have 71 stations in total over 5 cities:
Trip data:
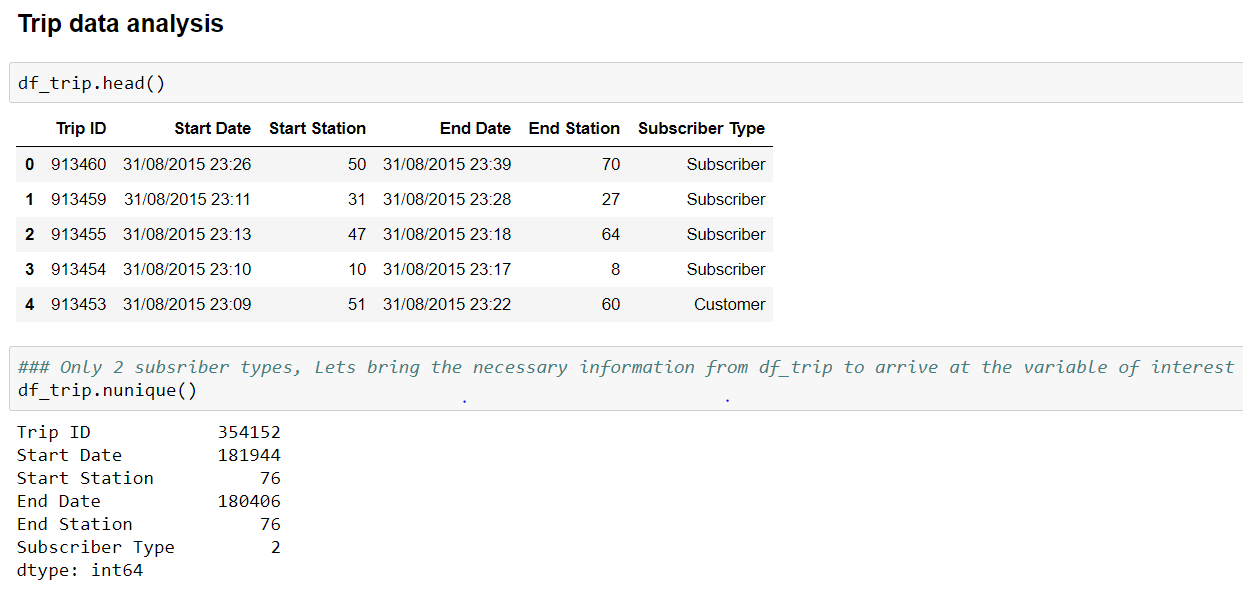
We have seen 2 files till now and understand that the target variable is not given to us as is. We need to create the target variable which is net rate of change in trips at a station in a given hour. For this, we need to create start and end hour features from start and end date respectively.
Once we have the net_rate feature created as our target variable, we need to start bringing all the relevant attributes into one dataframe.
So, we have merged station and trip data to create an intermediate df named as, df_station_netrate:
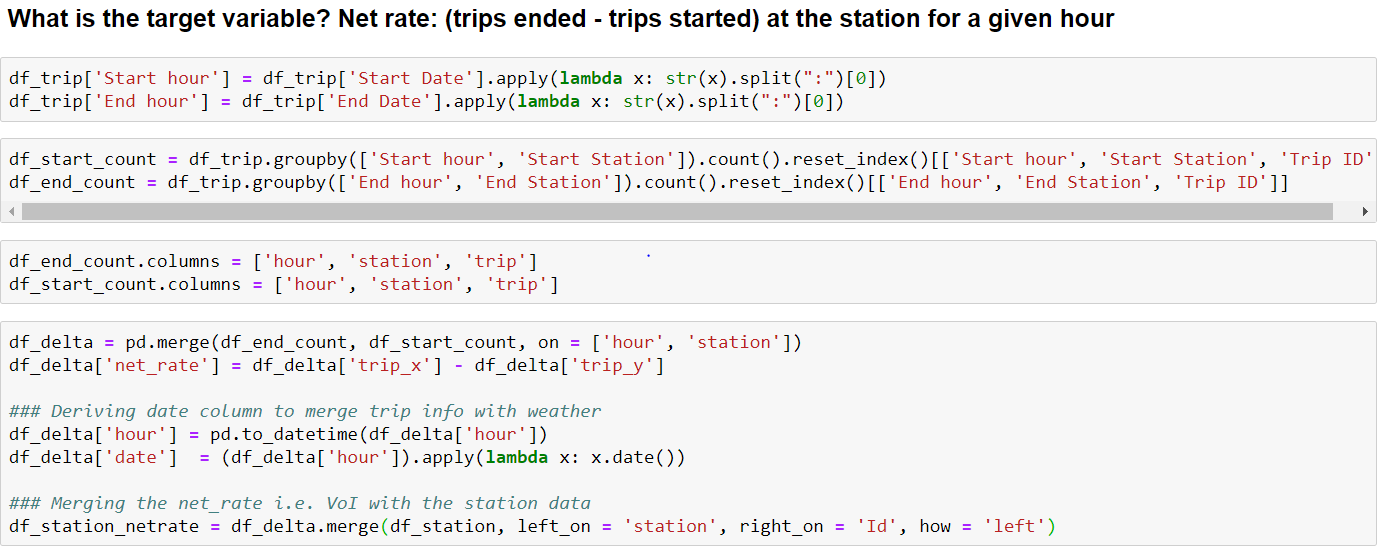
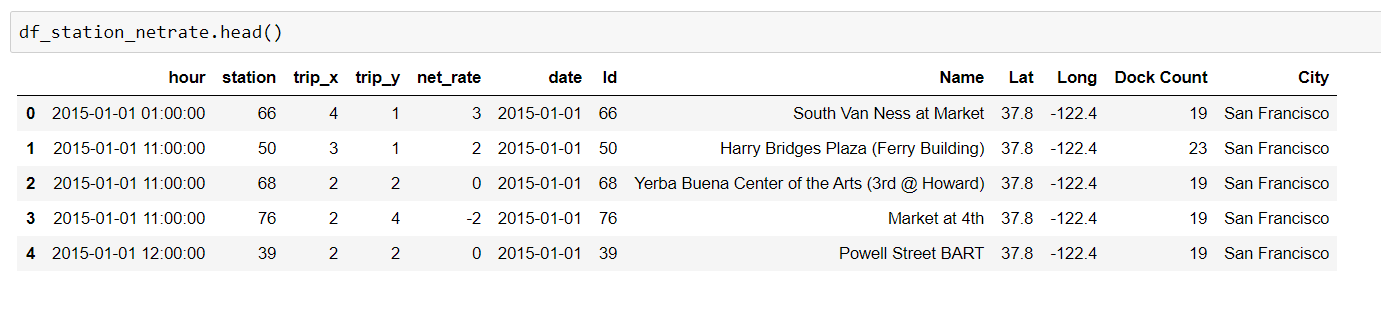
Let’s see how this intermediate df ‘df_station_netrate’ looks like:
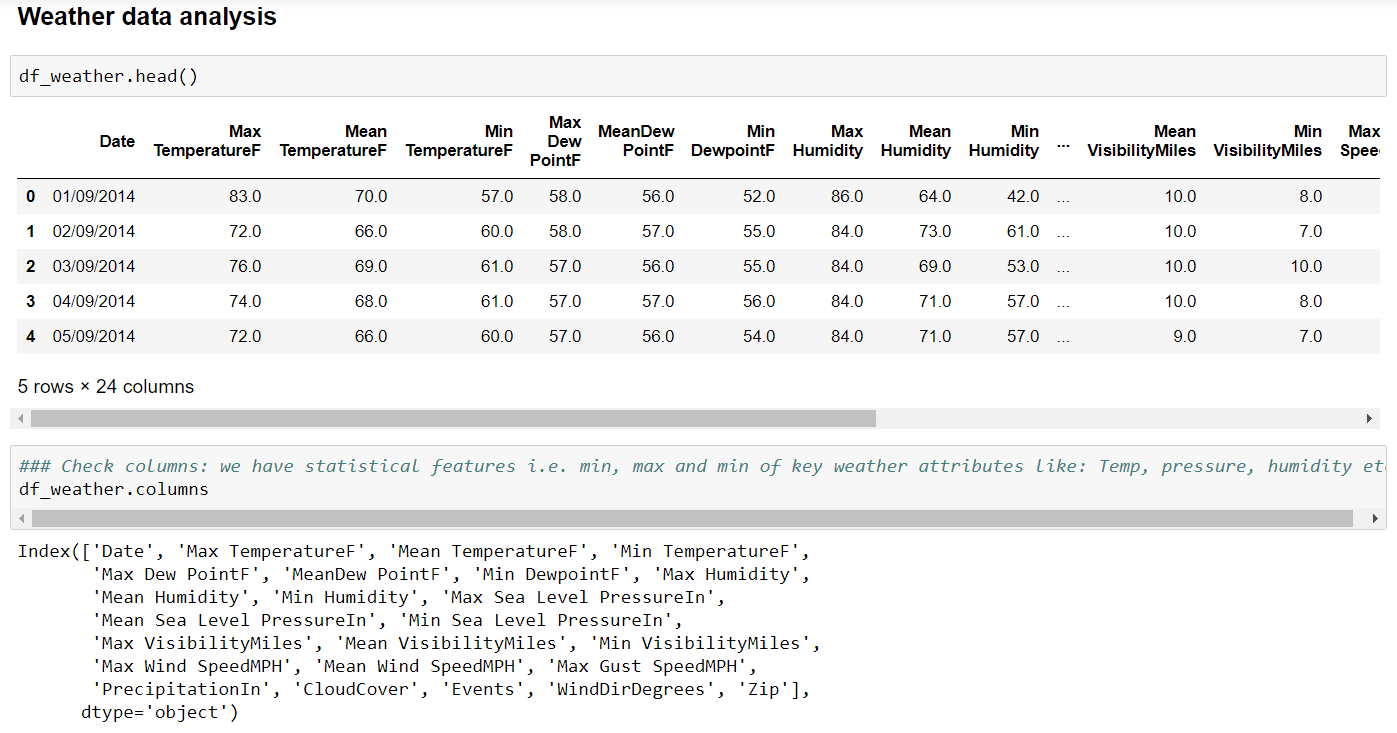
Weather Data:
Note that we have yet not studied weather data, so let’s see how to bring weather information to our intermediate df ‘df_station_netrate’ created above.
Missing values in weather data:
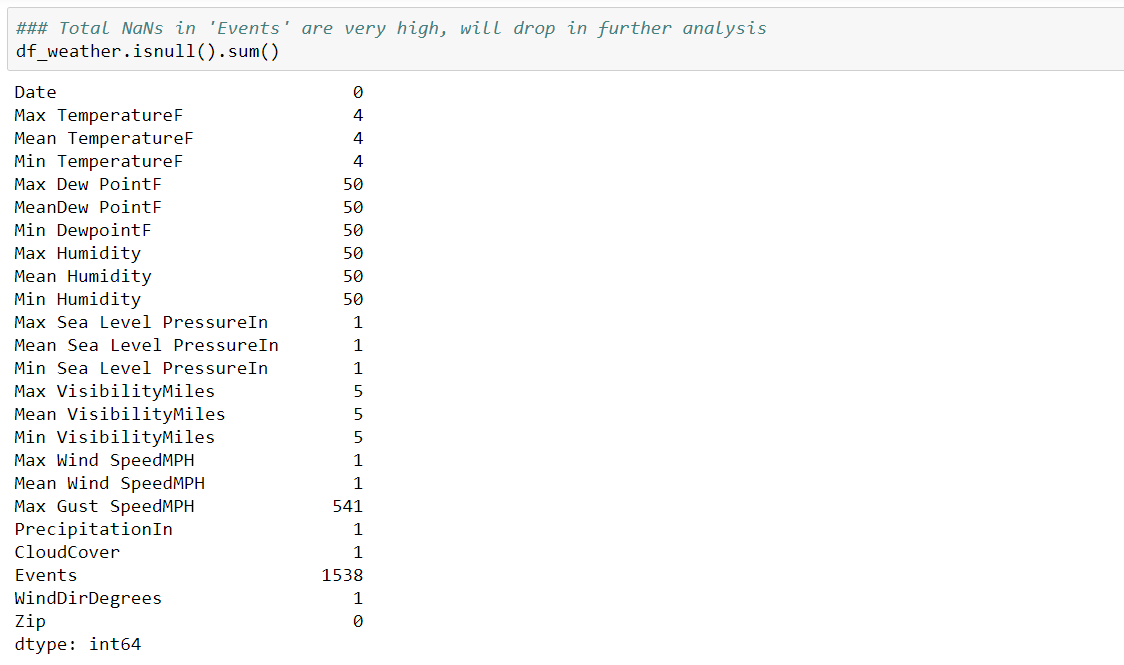
External Data:
Note that we have zipcode in weather data and lat-long information in intermediate df ‘df_station_netrate’, so we need zipcode to lat-long mapping to be able to merge weather data with station data.
We resort to open-source data for this information: https://public.opendatasoft.com/explore/dataset/us-zip-code-latitude-and-longitude/export/
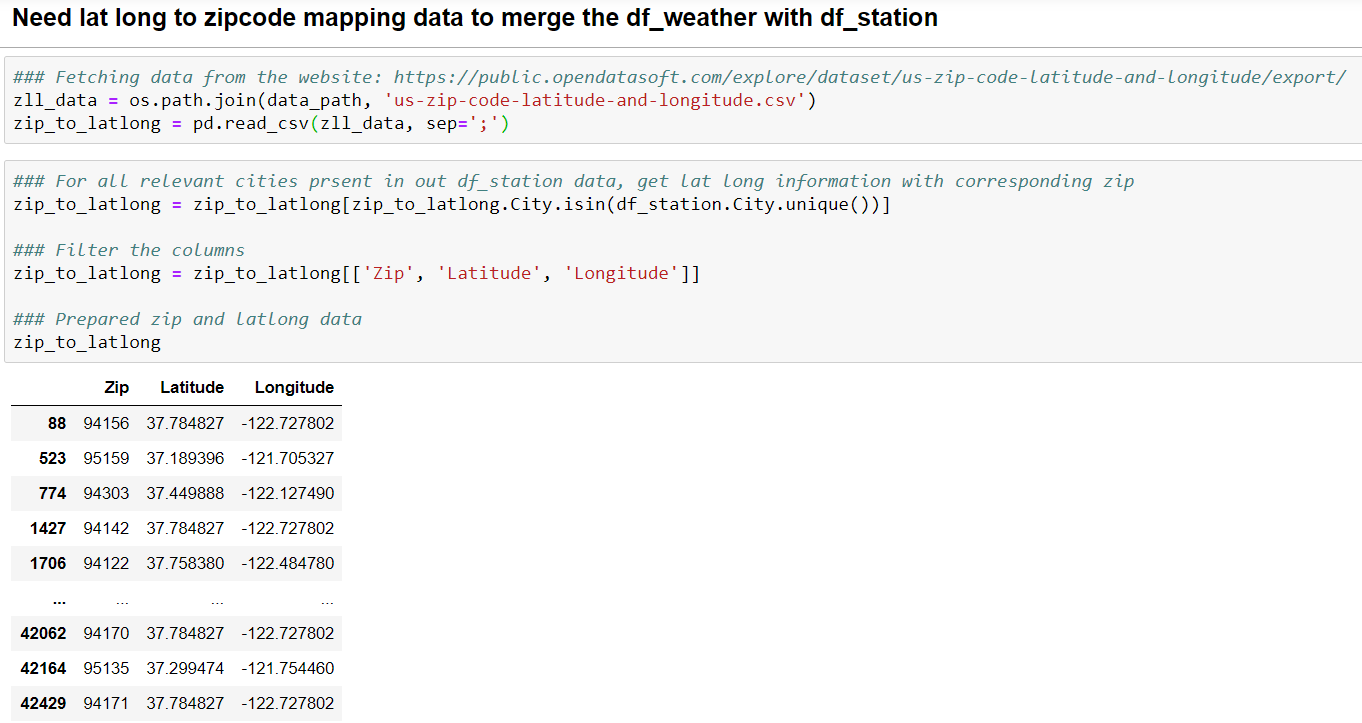
Now that we have the necessary mapping, we merge it with weather data:
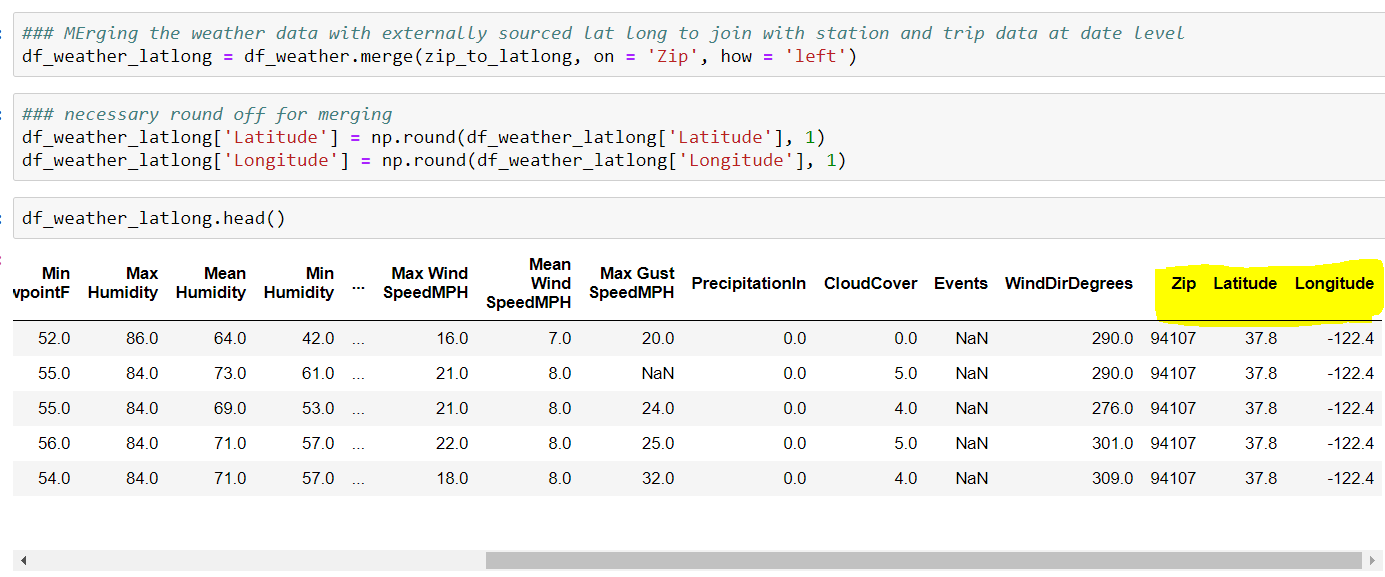
Final Data:
Now, we can merge this weather information with df_station_netrate, as our final training data preparation step:
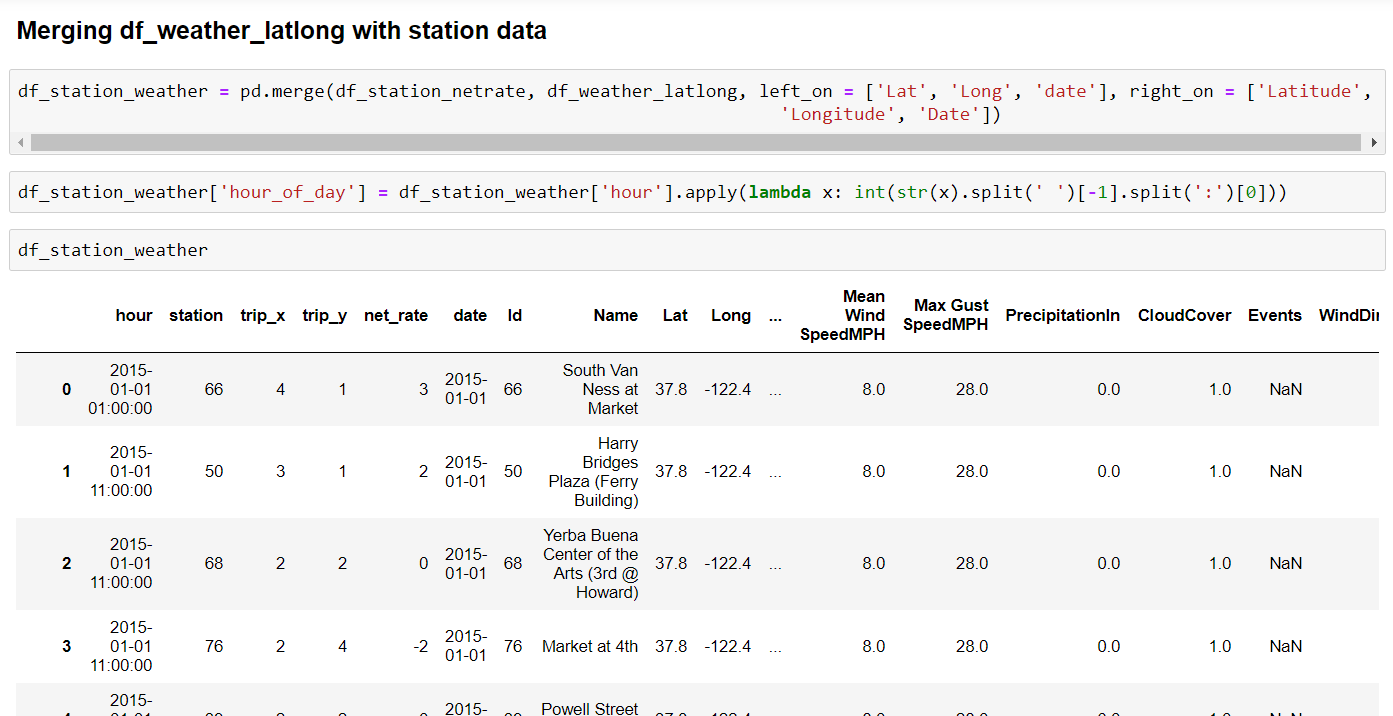
We shall also create date type features as part of the feature engineering process:

Finally, we have one flat file to train a model. So, we have seen that training data preparation and feature engineering are the most arduous task in creating a machine learning model.
Data and the source code is kept here.