



{kind=link}
Introduction
Have you ever wondered how good it would be to chat with a video? As a blog person myself, it often bores me to watch an hour-long video to find relevant information. Sometimes it feels like a job to watch a video to get any useful information out of it. So, I built a chatbot that lets you chat with YouTube videos or any video. This was made possible by GPT-3.5-turbo, Langchain, ChromaDB, Whisper, and Gradio. So, in this article, I will do a code walk-through of building a functional chatbot for YouTube videos with Langchain.
Learning Objectives
- Build the web interface using Gradio
- Handle YouTube videos and extract textual data from them using Whisper
- Process and format texts appropriately
- Create embeddings of text data
- Configure Chroma DB to store data
- Initialize a Langchain conversation chain with OpenAI chatGPT, ChromaDB, and embeddings function
- Finally, querying and streaming answers to the Gradio chatbot
Before getting to the coding part, let’s get familiarized with the tools and technologies we will use.
This article was published as a part of the Data Science Blogathon.
Table of contents
Langchain
The Langchain is an open-source tool written in Python that makes Large Language Models data aware and agentic. So, what does that even mean? Most of the commercially available LLMs, such as GPT-3.5 and GPT-4, have a limit on the data they are trained on. For example, ChatGPT can only answer questions that it has already seen. Anything after September 2021 is unknown to it. This is the core issue that Langchain solves. Be it a Word doc or any personal PDF, we can feed the data to an LLM and get a human-like response. It has wrappers for tools like Vector DBs, Chat models, and embedding functions, which make it easy to build an AI application using just Langchain.

Langchain also allows us to build Agents – LLM bots. These autonomous agents can be configured for multiple tasks, including data analysis, SQL querying, and even writing basic codes. There are a lot of things we can automate using these agents. This is helpful as we can outsource low-level knowledge work to an LLM, saving us time and energy.
In this project, we will use Langchain tools to build a chat app for videos. For more information regarding Langchain, visit their official site.
Whisper
Whisper is another progeny of OpenAI. It is a general-purpose speech-to-text model that can convert audio or videos into text. It is trained on a large amount of diverse audio to perform multi-lingual translation, speech recognition, and classification.
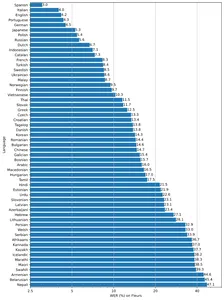
The model is available in five different sizes tiny, base, medium, small, and large, with speed and accuracy tradeoffs. The performance of models also depends on the language. The figure below shows a WER (Word Error Rate) breakdown by languages of Fleur’s dataset using the large-v2 model.
Vector Databases
Most machine learning algorithms cannot process raw unstructured data like images, audio, video, and texts. They have to be converted into matrices of vector embeddings. These vector embeddings represent the said data in a multi-dimensional plane. To get embeddings, we need highly efficient deep-learning models capable of capturing the semantic meaning of data. This is highly important for making any AI app. To store and query this data, we need databases capable of handling them effectively. This resulted in the creation of specialized databases called vector databases. There are multiple open-source databases are there. Chroma, Milvus, Weaviate, and FAISS are some of the most popular.
Another USP of vector stores is that we can perform high-speed search operations on unstructured data. Once we get the embeddings, we can use them for clustering, searching, sorting, and classification. As the data points are in a vector space, we can calculate the distance between them to know how closely they are related. Multiple algorithms like Cosine Similarity, Euclidean Distance, KNN, and ANN (Approximate Nearest Neighbour) are used to find similar data points.
We will use Chroma vector store – an open-source vector database. Chroma also has Langchain integration, which will come in very handy.
Gradio
The fourth horseman of our app Gradio is an open-source library to share machine learning models easily. It can also help build demo web apps with its components and events with Python.
If you are unfamiliar with Gradio and Langchain, read the following articles before moving ahead.
Let’s now start building it.
Setup Dev Env
To set up the development environment, create a Python virtual environment or create a local dev environment with Docker.
Now install all these dependencies
pytube==15.0.0
gradio == 3.27.0
openai == 0.27.4
langchain == 0.0.148
chromadb == 0.3.21
tiktoken == 0.3.3
openai-whisper==20230314
Import Libraries
import os
import tempfile
import whisper
import datetime as dt
import gradio as gr
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.chat_models import ChatOpenAI
from langchain.chains import ConversationalRetrievalChain
from pytube import YouTube
from typing import TYPE_CHECKING, Any, Generator, List
Create Web Interface
We will use Gradio Block and components to build the front end of our application. So, here’s how you can make the interface. Feel free to customize as you see fit.
with gr.Blocks() as demo:
with gr.Row():
# with gr.Group():
with gr.Column(scale=0.70):
api_key = gr.Textbox(placeholder='Enter OpenAI API key',
show_label=False, interactive=True).style(container=False)
with gr.Column(scale=0.15):
change_api_key = gr.Button('Change Key')
with gr.Column(scale=0.15):
remove_key = gr.Button('Remove Key')
with gr.Row():
with gr.Column():
chatbot = gr.Chatbot(value=[]).style(height=650)
query = gr.Textbox(placeholder='Enter query here',
show_label=False).style(container=False)
with gr.Column():
video = gr.Video(interactive=True,)
start_video = gr.Button('Initiate Transcription')
gr.HTML('OR')
yt_link = gr.Textbox(placeholder='Paste a YouTube link here',
show_label=False).style(container=False)
yt_video = gr.HTML(label=True)
start_ytvideo = gr.Button('Initiate Transcription')
gr.HTML('Please reset the app after being done with the app to remove resources')
reset = gr.Button('Reset App')
if __name__ == "__main__":
demo.launch() The interface will appear like this
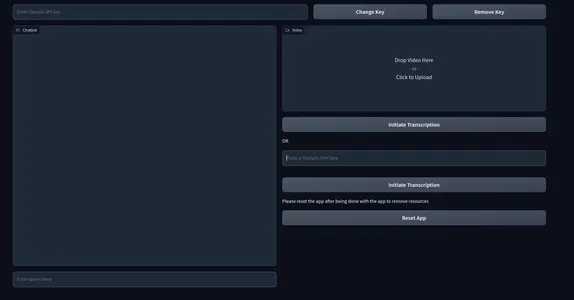
Here, we have a textbox that takes the OpenAI key as input. And also two keys for changing the API key and deleting the key. We also have a chat UI on the left and a box for rendering local videos on the right. Immediately below the video box, we have a box asking for a YouTube link and buttons that say “Initiate Transcription.”
Gradio Events
Now we will define events to make the app interactive. Add the below codes at the end of the gr.Blocks().
start_video.click(fn=lambda :(pause, update_yt),
outputs=[start2, yt_video]).then(
fn=embed_video, inputs=,
outputs=).success(
fn=lambda:resume,
outputs=[start2])
start_ytvideo.click(fn=lambda :(pause, update_video),
outputs=[start1,video]).then(
fn=embed_yt, inputs=[yt_link],
outputs = [yt_video, chatbot]).success(
fn=lambda:resume, outputs=[start1])
query.submit(fn=add_text, inputs=[chatbot, query],
outputs=[chatbot]).success(
fn=QuestionAnswer,
inputs=[chatbot,query,yt_link,video],
outputs=[chatbot,query])
api_key.submit(fn=set_apikey, inputs=api_key, outputs=api_key)
change_api_key.click(fn=enable_api_box, outputs=api_key)
remove_key.click(fn = remove_key_box, outputs=api_key)
reset.click(fn = reset_vars, outputs=[chatbot,query, video, yt_video, ])- start_video: When clicked will trigger the process of getting texts from the video and create a Conversational chain.
- start_ytvideo: When clicked will do the same but now from the YouTube video, and when completed will render the YouTube video just below it.
- query: Responsible for streaming response from LLM to the chat UI.
The rest of the events are for handling the API key and resetting the app.
We have defined the events but haven’t defined the functions responsible for triggering events.
Backend
To not make it complicated and messy, we will outline the processes we will be dealing with in the backend.
- Handle API keys.
- Handle Uploaded video.
- Transcribe videos to get texts.
- Create chunks out of video texts.
- Create embeddings from texts.
- Store vector embeddings in the ChromaDB vector store.
- Create a Conversational Retrieval chain with Langchain.
- Send relevant documents to the OpenAI chat model (gpt-3.5-turbo).
- Fetch the answer and stream it on chat UI.
We will be doing all these things along with a few exception handling.
Define a few environment variables.
chat_history = []
result = None
chain = None
run_once_flag = False
call_to_load_video = 0
enable_box = gr.Textbox.update(value=None,placeholder= 'Upload your OpenAI API key',
interactive=True)
disable_box = gr.Textbox.update(value = 'OpenAI API key is Set',
interactive=False)
remove_box = gr.Textbox.update(value = 'Your API key successfully removed',
interactive=False)
pause = gr.Button.update(interactive=False)
resume = gr.Button.update(interactive=True)
update_video = gr.Video.update(value = None)
update_yt = gr.HTML.update(value=None) Handle API Keys
When a user submits a key, it gets set as the environment variable, and we will also disable the textbox from further input. Pressing the change key will make it mutable again. Clicking the remove key will remove the key.
enable_box = gr.Textbox.update(value=None,placeholder= 'Upload your OpenAI API key',
interactive=True)
disable_box = gr.Textbox.update(value = 'OpenAI API key is Set',interactive=False)
remove_box = gr.Textbox.update(value = 'Your API key successfully removed',
interactive=False)
def set_apikey(api_key):
os.environ['OPENAI_API_KEY'] = api_key
return disable_box
def enable_api_box():
return enable_box
def remove_key_box():
os.environ['OPENAI_API_KEY'] = ''
return remove_boxHandle Videos
Next up, we will be dealing with uploaded videos and YouTube links. We will have two different functions dealing with each case. For YouTube links, we will create an iframe embed link. For each case, we will call another function make_chain() responsible for creating chains.
These functions are triggered when someone uploads a video or provides a YouTube link and presses transcribe button.
def embed_yt(yt_link: str):
# This function embeds a YouTube video into the page.
# Check if the YouTube link is valid.
if not yt_link:
raise gr.Error('Paste a YouTube link')
# Set the global variable `run_once_flag` to False.
# This is used to prevent the function from being called more than once.
run_once_flag = False
# Set the global variable `call_to_load_video` to 0.
# This is used to keep track of how many times the function has been called.
call_to_load_video = 0
# Create a chain using the YouTube link.
make_chain(url=yt_link)
# Get the URL of the YouTube video.
url = yt_link.replace('watch?v=', '/embed/')
# Create the HTML code for the embedded YouTube video.
embed_html = f"""<iframe width="750" height="315" src="{url}"
title="YouTube video player" frameborder="0"
allow="accelerometer; autoplay; clipboard-write;
encrypted-media; gyroscope; picture-in-picture"
allowfullscreen></iframe>"""
# Return the HTML code and an empty list.
return embed_html, []
def embed_video(video=str | None):
# This function embeds a video into the page.
# Check if the video is valid.
if not video:
raise gr.Error('Upload a Video')
# Set the global variable `run_once_flag` to False.
# This is used to prevent the function from being called more than once.
run_once_flag = False
# Create a chain using the video.
make_chain(video=video)
# Return the video and an empty list.
return video, []Create Chain
This is one of the most important steps of all. This involves creating a Chroma vector store and Langchain chain. We will use a Conversational retrieval chain for our use case. We will use OpenAI embeddings, but for actual deployments, use any free embedding models like Huggingface sentence encoders, etc.
def make_chain(url=None, video=None) -> (ConversationalRetrievalChain | Any | None):
global chain, run_once_flag
# Check if a YouTube link or video is provided
if not url and not video:
raise gr.Error('Please provide a YouTube link or Upload a video')
if not run_once_flag:
run_once_flag = True
# Get the title from the YouTube link or video
title = get_title(url, video).replace(' ','-')
# Process the text from the video
grouped_texts, time_list = process_text(url=url) if url else process_text(video=video)
# Convert time_list to metadata format
time_list = [{'source': str(t.time())} for t in time_list]
# Create vector stores from the processed texts with metadata
vector_stores = Chroma.from_texts(texts=grouped_texts, collection_name='test',
embedding=OpenAIEmbeddings(),
metadatas=time_list)
# Create a ConversationalRetrievalChain from the vector stores
chain = ConversationalRetrievalChain.from_llm(ChatOpenAI(temperature=0.0),
retriever=
vector_stores.as_retriever(
search_kwargs={"k": 5}),
return_source_documents=True)
return chain
- Get texts and metadata from either YouTube URL or video file.
- Create a Chroma vector store from texts and metadata.
- Build a chain using OpenAI gpt-3.5-turbo and chroma vector store.
- Return chain.
Process Texts
In this step, we will do appropriate slicing of texts from videos and also create the metadata object we used in the above chain-building process.
def process_text(video=None, url=None) -> tuple[list, list[dt.datetime]]:
global call_to_load_video
if call_to_load_video == 0:
print('yes')
# Call the process_video function based on the given video or URL
result = process_video(url=url) if url else process_video(video=video)
call_to_load_video += 1
texts, start_time_list = [], []
# Extract text and start time from each segment in the result
for res in result['segments']:
start = res['start']
text = res['text']
start_time = dt.datetime.fromtimestamp(start)
start_time_formatted = start_time.strftime("%H:%M:%S")
texts.append(''.join(text))
start_time_list.append(start_time_formatted)
texts_with_timestamps = dict(zip(texts, start_time_list))
# Convert the timestamp strings to datetime objects
formatted_texts = {
text: dt.datetime.strptime(str(timestamp), '%H:%M:%S')
for text, timestamp in texts_with_timestamps.items()
}
grouped_texts = []
current_group = ''
time_list = [list(formatted_texts.values())[0]]
previous_time = None
time_difference = dt.timedelta(seconds=30)
# Group texts based on time difference
for text, timestamp in formatted_texts.items():
if previous_time is None or timestamp - previous_time <= time_difference:
current_group += text
else:
grouped_texts.append(current_group)
time_list.append(timestamp)
current_group = text
previous_time = time_list[-1]
# Append the last group of texts
if current_group:
grouped_texts.append(current_group)
return grouped_texts, time_list
- The process_text function takes either a URL or a Video path. This video is then transcribed in the process_video function, and we get the final texts.
- We then get the start time of each sentence (from Whisper) and group them in 30 seconds.
- We finally return the grouped texts and starting time of each group.
Process Video
In this step, we transcribe video or audio files and get texts. We will use the Whisper base model for transcription.
def process_video(video=None, url=None) -> dict[str, str | list]:
if url:
file_dir = load_video(url)
else:
file_dir = video
print('Transcribing Video with whisper base model')
model = whisper.load_model("base")
result = model.transcribe(file_dir)
return resultFor YouTube videos, as we cannot directly process them, we will have to handle them separately. We will use a library called Pytube to download the audio or video of the YouTube video. So, here’s how you can do it.
def load_video(url: str) -> str:
# This function downloads a YouTube video and returns the path to the downloaded file.
# Create a YouTube object for the given URL.
yt = YouTube(url)
# Get the target directory.
target_dir = os.path.join('/tmp', 'Youtube')
# If the target directory does not exist, create it.
if not os.path.exists(target_dir):
os.mkdir(target_dir)
# Get the audio stream of the video.
stream = yt.streams.get_audio_only()
# Download the audio stream to the target directory.
print('----DOWNLOADING AUDIO FILE----')
stream.download(output_path=target_dir)
# Get the path of the downloaded file.
path = target_dir + '/' + yt.title + '.mp4'
# Return the path of the downloaded file.
return path
- Create a YouTube object for the given URL.
- Create a temporary target directory path
- Check if the path exists else create the directory
- Download the audio of the file.
- Get the path directory of the video
This was the bottom-up process from getting texts from videos to creating the chain. Now, all that remains is configuring the chatbot.
Configure Chatbot
All we need now is to send a query and a chat_history to it to fetch our answers. So, we will define a function that only triggers when a query is submitted.
def add_text(history, text):
if not text:
raise gr.Error('enter text')
history = history + [(text,'')]
return history
def QuestionAnswer(history, query=None, url=None, video=None) -> Generator[Any | None, Any, None]:
# This function answers a question using a chain of models.
# Check if a YouTube link or a local video file is provided.
if video and url:
# Raise an error if both a YouTube link and a local video file are provided.
raise gr.Error('Upload a video or a YouTube link, not both')
elif not url and not video:
# Raise an error if no input is provided.
raise gr.Error('Provide a YouTube link or Upload a video')
# Get the result of processing the video.
result = chain({"question": query, 'chat_history': chat_history}, return_only_outputs=True)
# Add the question and answer to the chat history.
chat_history += [(query, result["answer"])]
# For each character in the answer, append it to the last element of the history.
for char in result['answer']:
history[-1][-1] += char
yield history, ''
We provide the chat history with the query to keep the context of the conversation. Finally, we stream the answer back to the chatbot. And don’t forget to define the reset functionality to reset all the values.
So, this was all about it. Now, launch your application and start chatting with videos.
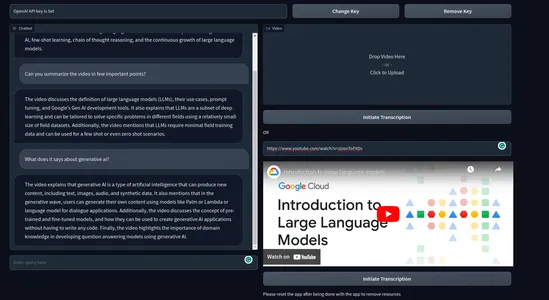
This is how the final product looks
Video Demo:
Real-life Use cases
An application that lets end-user chat with any video or audio can have a wide range of use cases. Here are some of the real-life use cases of this chatbot.
- Education: Students often go through hours-long video lectures. This chatbot can aid students in learning from lecture videos and extract useful information quickly, saving time and energy. This will significantly improve the learning experience.
- Legal: Law professionals often go through lengthy legal proceedings and depositions to analyze the case, prepare documents, research, or compliance monitoring. A chatbot like this can go a long way in decluttering such tasks.
- Content Summarization: This app can analyze video content and generate summarized text versions. This lets the user grasp highlights of the video without watching it entirely.
- Customer Interaction: Brands can incorporate a video chatbot feature for their products or services. This can be helpful for businesses that sell products or services that are high-ticket or that require a lot of explanation.
- Video Translation: We can translate the text corpus to other languages. This can facilitate cross-lingual communication, language learning, or accessibility for non-native speakers.
These are some of the potential use cases I could think of. There can have a lot more useful applications of a chatbot for videos.
Conclusion
So, this was all about building a functional demo web app for a chatbot for videos. We covered a lot of concepts throughout the article. Here are the key takeaways from the article.
- We learned about Langchain – a popular tool for creating AI applications with ease.
- Whisper is a potent speech-to-text model by OpenAI. An open-source model that can convert audio and videos to text.
- We learned how vector databases facilitate the effective storing and querying of vector embeddings.
- We built a completely functional web app from scratch using Langchain, Chroma, and OpenAI models.
- We also discussed potential real-life use cases of our chatbot.
This was all about it hope you liked it, and do consider following me on Twitter for more things related to development.
GitHub Repository: sunilkumardash9/chatgpt-for-videos. If you find this helpful, do ⭐ the repository.
Frequently Asked Questions
A. LangChain is an open-source framework that simplifies the creation of applications using large language models. It can be used for a variety of tasks, including chatbots, document analysis, code analysis, question answering, and generative tasks.
A. Chains are a sequence of steps that are executed in order. They are used to define a specific task or process. For example, a chain could be used to summarize a document, answer a question, or generate creative text.
Agents are more complex than chains. They can make decisions about which steps to execute, and they can also learn from their experiences. Agents are often used for tasks that require a lot of creativity or reasoning, For example, data analysis, and code generation.
A. 1. Action: Action agents decide an action to take and execute that action one step at a time. They are more conventional and suitable for small tasks.
2. Plan-and-execute agents first decide on a plan of action to take and then execute those actions one at a time. They are more complex and suitable for tasks that require more planning and flexibility.
A. Langchain is capable of integrating LLMs and chat models. LLMs are models that take string input and return a string response. Chat models take a list of chat messages as input and output a chat message.
A. Yes, Lagchain is an open-source free-to-use tool, but most operations will require an OpenAI API key which incurs charges.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.